Java Stream 流
介绍 Java Stream 流是一组结合Lambda表达式,简化集合、数组操作的API,可以以声明的方式处理数据,类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。流的特点有: 不是数据结
介绍
Java Stream 流是一组结合Lambda表达式,简化集合、数组操作的API,可以以声明的方式处理数据,类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。流的特点有:
- 不是数据结构,不会保存数据,只是在原数据集上定义了一组操作
- 惰性求值,流在中间处理过程中,只是对操作进行了记录,并不会立即执行,需要等到执行终止操作的时候才会进行实际的计算
- Stream不保存数据,它会将操作后的数据保存到另外一个对象中
基本使用
创建
public class StreamAPI {
public static void main(String[] args) throws FileNotFoundException {
// 1. 数组
Integer[] array = {1, 2, 3};
Stream<Integer> integerStream1 = Arrays.stream(array);
// 2. 集合
List<Integer> list = Arrays.asList(array);
Stream<Integer> listStream1 = list.stream();
Stream<Integer> listStream2 = list.parallelStream();
// 3. BufferedReader -------------------------------
BufferedReader reader = new BufferedReader(new FileReader("xxx"));
Stream<String> linesStream = reader.lines();
// 4. 字符串处理
String str = "1,2,3";
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream(str);
// 4. Stream自带的静态方法
Stream<Integer> integerStream = Stream.of(1, 2, 3);
Stream<Integer> integerStream2 = Stream.iterate(1, s -> (s + 2));
Stream<Double> generate = Stream.generate(Math::random);
}
}
操作
Stream 的操作分为两类:
- 中间操作(Intermediate):仅作为标记,返回值仍是 stream。可以有多个进行链式操作
- 有状态:只有拿到所有元素之后才能获得结果
- 无状态:操作不受之前元素的影响
- 结束操作(Terminal):触发 Stream 进行计算的操作,只能有一个。每次执行完,这个流也就用完了,无法继续执行操作
- 短路:满足短路条件时,不需要处理完所有元素就能返回结果
- 非短路:处理完所有元素才返回结果
| 名称 | 类型 | 返回类型 | 使用的类型/函数式接口 | 函数描述 |
|---|---|---|---|---|
| filter | 中间操作(Intermediate) | Stream | Predicate | T -> boolean |
| distinct | 中间操作(Intermediate)、有状态 | Stream | 无 | T -> boolean |
| skip | 中间操作(Intermediate)、有状态 | Stream | 无 | 无 |
| limit | 中间操作(Intermediate) | Stream | 无 | 无 |
| map | 中间操作(Intermediate) | Stream | Function | T -> R |
| flatMap | 中间操作(Intermediate) | Stream | Function | T -> Stream |
| sorted | 中间操作(Intermediate)、有状态 | Stream | Comparator | (T, T) -> int |
| noneMatch | 结束操作(Terminal) | boolean | Predicate | T -> boolean |
| allMatch | 结束操作(Terminal) | boolean | Predicate | T -> boolean |
| findAny | 结束操作(Terminal) | Optional | 无 | 无 |
| findFirst | 结束操作(Terminal) | Optional | 无 | 无 |
| forEach | 结束操作(Terminal) | void | Consumer | T -> void |
| collect | 结束操作(Terminal) | R | Collector | 无 |
| reduce | 结束操作(Terminal) | Optional | BinaryOperator | (T, T) -> T |
| count | 结束操作(Terminal) | long | 无 | 无 |
User user1 = new User(1,"张三");
User user2 = new User(2,"李四");
User user3 = new User(3,"王五");
ArrayList<User> users = new ArrayList<>();
users.add(user1);
users.add(user2);
users.add(user3);
// list
List<Integer> list = integerStream1.collect(Collectors.toList());
// set
Set<Integer> set = integerStream1.collect(Collectors.toSet());
// map key不能相同
Map<Integer, String> map = users.stream().collect(Collectors.toMap(User::getId, User::getName));
// 获取users元素个数
Long count = users.stream().collect(Collectors.counting());
// 获取users集合id最大值
Optional<Integer> max = users.stream().map(User::getId).collect(Collectors.maxBy(Integer::compare));
// 获取users集合id最小值
Optional<Integer> min = users.stream().map(User::getId).collect(Collectors.minBy(Integer::compare));
// 获取users集合所有id的和
Integer id = users.stream().collect(Collectors.summingInt(User::getId));
// 获取users集合所有id的平均值
Double average = users.stream().collect(Collectors.averagingDouble(User::getId));
原理
中间操作
List<People> peopleList = new ArrayList<>();
peopleList.add(new People("qc", 18));
peopleList.add(new People("yh", 23));
Stream<Integer> stream = peopleList.stream()
.map(People::getAge)
.filter(x -> x % 2 == 0);
// map 创建了一个 StatelessOp
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
// filter 创建了一个 StatelessOp
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
// 构造器,将 Stage 串联成双向链表
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
以上面这段代码为例,stream() 得到的是是一个继承自 ReferencePipeline 的 Head 头节点,定义流的起点。map 和 filter 各自生成了一个 StatelessOp,在其中定义了对数据的操作。在其父类的构造器里面,实际是将所有 Stage 串联成了一个 ReferencePipeline 类型的双向队列,其中 , map 接收一个 Function 得到子类 StatelessOp,即无状态的中间操作,filter 接收一个 Lambda 也得到一个 StatelessOp。
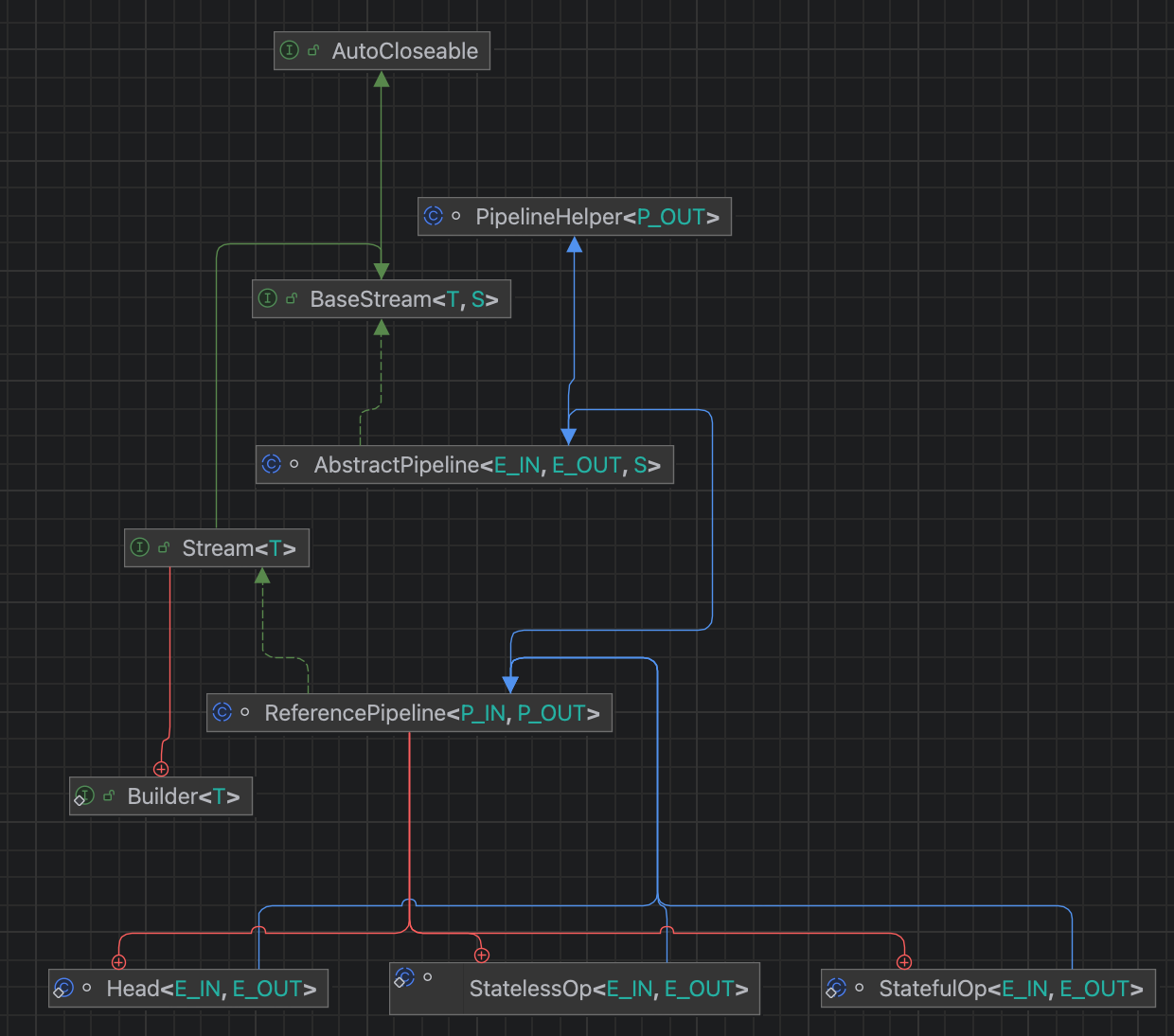
最终我们可以得到这样一个数据结构的流:
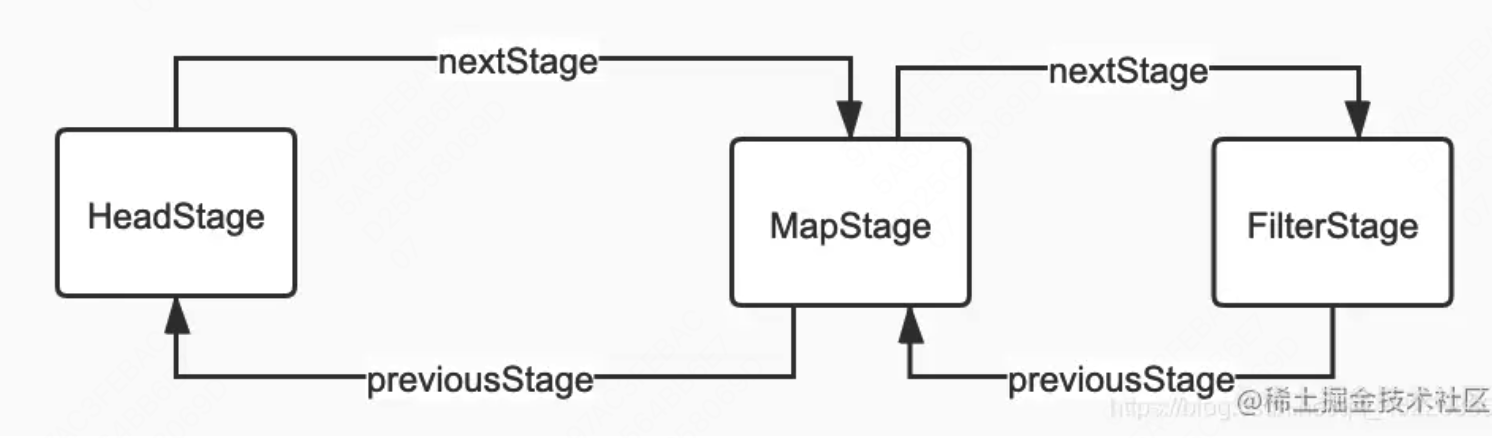
结束操作
// 开始结束操作
List<Integer> list = stream.collect(Collectors.toList());
// makeRef 返回一个 ReduceOp
container = evaluate(ReduceOps.makeRef(collector));
// 串行处理
terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
// makeSink 返回一个 ReducingSink
helper.wrapAndCopyInto(makeSink(), spliterator).get();
// 封转 Sink --> 执行操作
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
// 封装 Sink 并串联起来,每个 sink 的 downstream 指向下一步操作
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
// 流编排
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
// 通知下游做好准备,比如 collect 这个结束操作要准备好一个 List
wrappedSink.begin(spliterator.getExactSizeIfKnown());
// 实际执行操作
spliterator.forEachRemaining(wrappedSink);
// 通知下游结束
wrappedSink.end();
} else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
// 实际对元素执行操作
public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList<E> lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
// 关键,每个 ReferencePipeline 接收一个元素,执行操作。并且将元素传递下去,继续执行后续操作
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
当调用结束操作的时候,会从最后一个操作开始,用头插法,将每个 Stage 封装成 Sink 串联起来,每个 Sink 的 downstream 保存下一个阶段需要执行的操作。一个完整的 Stage 由【数据来源、操作、回调函数】这样的三元组来表示。
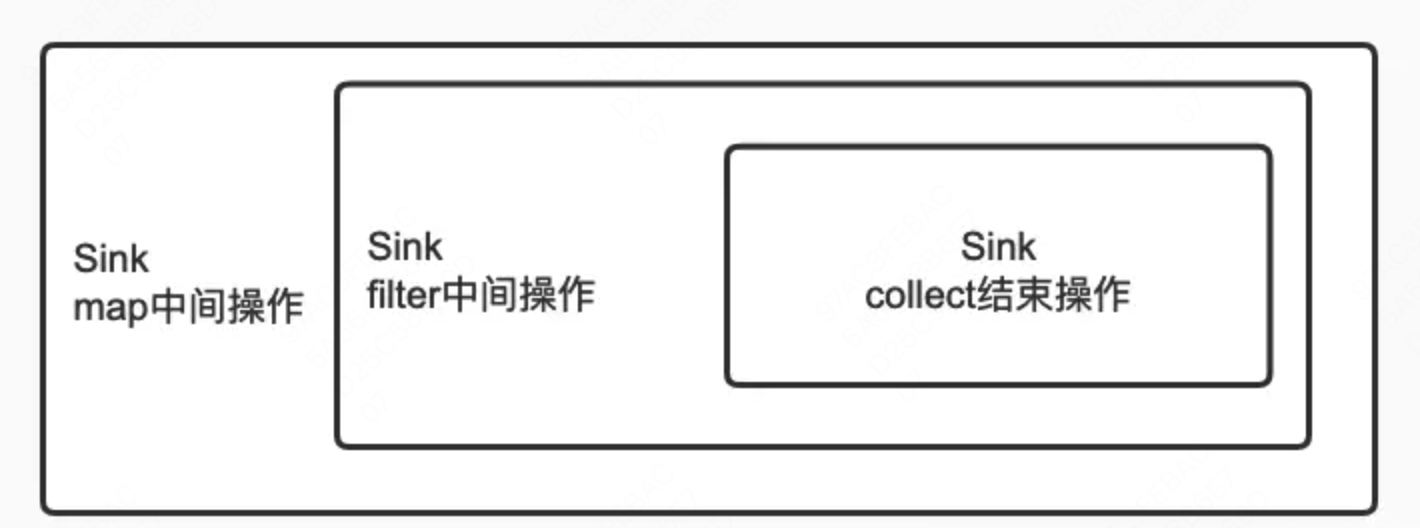
执行操作就是通过 Sink 套娃,每个操作依次 begin --> 对每个元素 accept --> 依次 end。从上面流的执行过程可以看出,直到终结操作才会开始对元素执行真正的操作,也就是流的延迟执行机制(惰性机制),所以尽早执行 filter 这样的操作,过滤掉不必要的元素,能够节省计算资源。
Sink 抽象了四种操作,Stream API 内部实现的本质,就是如何重写 Sink 的这四个接口:
- begin 开始遍历元素前执行
- end 所有元素遍历结束后执行
- cancellationRequested 是否可以短路,结束操作
- accept 遍历元素时执行
执行后的结果存放有四种类型:
- boolean:anyMatch, allMatch, noneMatch
- Optional: findFirst, findAny
- 归约结果:reduce、collect
- 数组:toArray
其中,boolean 和 Optional 都直接在 Sink 中记录值即可,归约操作会放到用户指定的容器中,数组底层存储在一种叫 Node 的多叉树数据结构里。
评论加载中。如果这里长期空白,请检查 giscus.app / GitHub 是否可访问。