面试八股
实习 目的地搜索优化 以前用户在搜索机场数据时,只会展示对应的城市机场信息,新的需求是用户在搜索某个景点信息时,展示对应城市的机场信息。另外优化了两个问题: 邻近机场距离由机场 邻近城市 机场 邻近机场:增加near airport d
实习 – 目的地搜索优化
以前用户在搜索机场数据时,只会展示对应的城市机场信息,新的需求是用户在搜索某个景点信息时,展示对应城市的机场信息。另外优化了两个问题:
- 邻近机场距离由机场-邻近城市 -> 机场-邻近机场:增加near_airport_distance的json格式串
- 同音不同字的城市机场搜索:cityPinyin -> 机场 的 Map 切换为 MultiMap
数据库设计
Scenic_Data
4K 多条数据
CREATE TABLE `scenic_data` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`scenic_id` varchar(32) NOT NULL DEFAULT '',
`scenic_name` varchar(32) NOT NULL DEFAULT '',
`city_code` char(3) DEFAULT NULL,
`city_name` varchar(32) DEFAULT NULL,
`scenic_longitude` varchar(32) NOT NULL DEFAULT '',
`scenic_latitude` varchar(32) NOT NULL DEFAULT '',
`deleted` int(11) NOT NULL DEFAULT '0',
`operator` varchar(32) NOT NULL DEFAULT '',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_city_code` (`city_code`),
KEY `idx_scenic_id` (`scenic_id`),
KEY `idx_deleted` (`deleted`)
) ENGINE=InnoDB AUTO_INCREMENT=7762 DEFAULT CHARSET=utf8mb4'
Scenic_Near_Airports
CREATE TABLE `scenic_near_airports` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`scenic_id` varchar(32) NOT NULL DEFAULT '',
`scenic_name` varchar(32) NOT NULL DEFAULT '',
`near_city_code` char(3) NOT NULL DEFAULT '',
`near_airport_code` char(3) NOT NULL DEFAULT '[]',
`distance` int(11) DEFAULT '0',
`deleted` int(11) NOT NULL DEFAULT '0',
`operator` varchar(32) NOT NULL DEFAULT '',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_scenic_near_airport` (`scenic_id`,`near_airport_code`),
KEY `idx_deleted` (`deleted`)
) ENGINE=InnoDB AUTO_INCREMENT=7589 DEFAULT CHARSET=utf8mb4
核心逻辑
景点/邻近机场落库
ScenicDataPullJob#pullScenicPoiAndComputeNearAirport 每 6H 执行一次
- 从景点服务拉取全量景点数据
- 过滤有机场的城市、国内景点等等各种过滤
- 和DB里面现有的的景点数据做diffAndSave
- 计算景点的邻近机场,选取0-300km以内,且距离最近的三个机场
- 落到景点邻近机场表里
本地缓存/搜索树
InitService#buildSuggestionEnv 服务启动时/每天凌晨执行 (本地缓存1.5G,机器8G,影响不大)
- 读取数据库的最新数据,构建 景点id -> 邻近机场 的map集合
- 根据拼音构建前缀搜索树 Trie Tree,key=景点拼音,value=景点id
- 服务里缓存了很多前缀树,如城市拼音、城市拼音简称、机场、邻近机场、景点等等,存入一个
Map<TrieTreeTypeEnum, TrieTree>里 - TrieTree封装了一个TreeNode根结点,每个TreeNode节点里面是一个TreeNode列表,和当前这个节点保存的字符,以及是否是叶子结点的标志位,叶子结点还会有一个存储景点Id的data字段
- 搜索的时候按照用户输入的内容转换成拼音,然后一个个字符匹配,输入全部匹配完或者到达叶子结点即匹配成功,把当前这层后续的所有叶子结点里data域存储的景点Id返回出去,如果中途遇到某个字符不匹配,那么匹配失败返回个null出去
- 服务里缓存了很多前缀树,如城市拼音、城市拼音简称、机场、邻近机场、景点等等,存入一个
TrieTree = TreeNode + 对外的方法
TreeNode = List<TreeNode> + char + terminal + scenicId
搜索逻辑
- 用户输入过滤非法字符,转换成拼音
- 根据拼音搜索前缀树,获得匹配的景点Id
- 然后构造对应的景点信息
- 接着用中文过滤一遍,防止中文搜索时同音不同名的景点信息(黄鹤楼/黄河楼)
- 然后再过滤没有机场信息的景点
- 如果过滤完的结果为空,会根据用户输入去查邻近城市的机场做一个兜底
- 最后有一些后置的处理,像城市/景点的搜索热度等等。最后将搜索结果返回
多线程使用
中转av批量查询接口需求中,需要根据 ftd 批量查询中转联程的AV情况,以前已经有了单个查询请求的接口,这次需要新增批量查询接口。由于每次查询都是一个耗时的RPC调用,因此需要使用多线程提高效率。
CompletableFuture<Void> allFuture = CompletableFuture.allOf(transferAvFlightReqs.stream()
.map(request -> CompletableFuture
.supplyAsync(() -> queryTransferAv((request)))
.thenAccept((res) -> {
String uniqueKey = getTransferAvUniqueKey(request);
map.put(uniqueKey, res);
}))
.toArray(CompletableFuture[]::new));
allFuture.get(Config.BATCH_QUERY_TRANSFER_AV_TIMEOUT, TimeUnit.MILLISECONDS);
主要的考虑点是要保证单个请求的失败不影响其它请求(thenAccept),并且基于单次查询的调用时间,通过配置的方式限制批量请求的总时间。
项目
酷安好物
酷安好物是一个好物推荐和购物商城,用户可以通过网页浏览商品信息、搜索商品、下单等,管理员通过系统后台维护商品
SPU/SKU、订单管理、人员管理等。
技术总体基于 SpringBoot+SpringCloud+MyBatis+Redis。主要
使用 SpringBoot 框架完成后台商品 SPU/SKU 的上下架管理
使用 MyBatisPlus 完成数据库的增删改查
实现 MySQL 的主从同步
使用 Redisson 实现分布式锁避免缓存击穿
使用 阿里云OSS 实现图片的上传存储
使用 Redis 对购物车数据进行缓存,减少对数据库的访问,加快处理速度
Nginx 反向代理
正向代理代理客户端,反向代理代理服务器。
upstream gulimall{
server 127.0.0.1:10086;
}
server {
listen 80;
server_name gulimall *.gulimall;
location /static {
root D:\Tools\nginx\html;
}
# 配置请求路由
location / {
proxy_pass http://gulimall;
proxy_set_header Host $host;
}
# include D:\\Tools\\nginx\\conf\\conf.d\\*.conf; # 包含了哪些配置文件
}
- 本机请求 gulimall -> 本地 Nginx 服务器,如果是 /static 路径的静态资源直接从 Nginx 目录下返回
- 其它 gulimall 域名下的请求根据 upstream 转发到网关
JVM 调优
JMeter 压测
添加线程组 -> 查看结果树和汇总报告 -> 分析异常比例、吞吐量、响应时间等。
发现:直接访问一个控制器的吞吐量可达 25000 QPS;而经过网关再访问吞吐量还剩 5500 QPS 左右,异常数量也会增加;而如果经过 Nginx 代理吞吐量仅剩 2200 QPS 左右。
优化:
- 三级目录原本是根据父目录 id 查三次数据库,查询 DB 速度很慢。可以优化业务逻辑,一次性全部查出再封装树形结构,QPS 从 2500 提高到了 7000。
- 商品信息展示的业务,网络传输数据量过大,导致页面加载过慢,可以通过 TO 传输对象精简返回的数据量,加快页面的加载
JConsole
Java 监视和管理控制台,根据 PID 连接查看进程信息,可以查看虚拟机内存使用情况,包括堆空间、Eden、Survivor等,包括 Young GC、Old GC 时间,以及线程数量等信息
jmapjstack 查看堆栈信息,以及排查死锁问题jhsdb jmap --heap --pid 20536 查看进程使用的GC算法、堆配置信息和各内存区域内存使用信息jstat -gc -h3 31736 1000 10 查看 GC 情况,各个空间的使用量jmap -dump:format=b,file=dump.hprof 20536 生成堆转储快照 heap profile -> VisualVM/JProfile 查看内存占用情况 -> 定位大对象 -> 定位代码中创建的位置 -> 排查 BUG
缓存
引入 data-redis-starter -> 配置 redis 地址、访问 -> 使用 StringRedisTemplate 操作 Redis (redisTemplate 是 Spring 对 Lettuce/Jedis 的封装)
@Test
void testRedis() {
ValueOperations<String, String> stringStringValueOperations = redisTemplate.opsForValue();
String val = stringStringValueOperations.get("Hello");
if(val == null) {
System.out.println("Key 'Hello' does not exist. Then set it...");
stringStringValueOperations.set("Hello", "World");
val = stringStringValueOperations.get("Hello");
}
System.out.println("Hello = " + val);
}
购物车缓存
使用 Redis 的原因:减轻数据库压力、速度快、共享缓存
具体操作:导入 Spring Cache 和 Redis 依赖坐标,ttl过期时间设为30分钟,@EnableCaching 开启缓存,在对应的控制器方法上标注 @Cacheable 注解对结果缓存。在 save 和 delete 方法上标注 @CacheEvict 标注,对数据库做修改时删除缓存,保证数据一致性。
数据结构:Map<String, Map<String, CatItemInfo>> Cart:UID = {{SKU1 = Info1}, {SKU2 = Info2}}
- 以 业务名+用户ID 作为 key
- 以商品 id 作为值的 field
- 以商品相关信息的 json 数据作为值的 value
多线程使用
自定义线程池,并使用 CompletableFuture 异步编排实现根据 skuId 检索商品详细信息,SKU 分基本信息、图片信息、销售属性、介绍、规格参数。其中,图片信息是可以和基本信息并发检索的,通过 runAsync 实现,而后面三个属性必须先获取到 SKU 的 spuId 才能检索,因此通过 thenAcceptAsync 实现。最后通过 CompletableFuture.allOf(…) 等待所有检索完成再返回。
CompletableFuture::supplyAsync(Supplier, executor)相比于CompletableFuture::runAsync(Runnable, executor)可以获取返回值- 如果没有指定线程池,则默认使用 ForkJoinPool.commonPool()
- get() 获取结果时,如果结果非空则 reportGet(),否则 waitingGet()
线程池配置
return new ThreadPoolExecutor(20, 200, 10,TimeUnit.SECONDS,
new LinkedBlockingDeque<>(10000), Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
/**
* 查询页面详细内容
*/
@Override
public SkuItemVo item(Long skuId) throws ExecutionException, InterruptedException {
SkuItemVo skuItemVo = new SkuItemVo();
// 1. sku 基本信息
CompletableFuture<SkuInfoEntity> infoFuture = CompletableFuture.supplyAsync(() -> {
SkuInfoEntity info = getById(skuId);
skuItemVo.setInfo(info);
return info;
}, executor);
// 2. sku图片信息
CompletableFuture<Void> imageFuture = CompletableFuture.runAsync(() -> {
List<SkuImagesEntity> images = imagesService.getImagesBySkuId(skuId);
skuItemVo.setImages(images);
}, executor);
// 3. 获取spu销售属性组合 list (在 1 之后)
CompletableFuture<Void> saleAttrFuture = infoFuture.thenAcceptAsync(res -> {
List<ItemSaleAttrVo> saleAttrVos = skuSaleAttrValueService.getSaleAttrsBuSpuId(res.getSpuId());
skuItemVo.setSaleAttr(saleAttrVos);
}, executor);
// ......
// TODO 6. 查询当前 sku 是否参与秒杀优惠
// 等待所有任务都完成在返回
CompletableFuture.allOf(imageFuture, saleAttrFuture, descFuture, baseAttrFuture).get();
return skuItemVo;
}
订单、库存
业务逻辑:当用户下单时,订单系统生成订单,商品系统扣减库存,促销系统扣减优惠券,最后订单入库。
可以采用 2PC、3PC、TCC 等分布式事务方案(适合要求强一致性的场景例如金融支付),但本项目采用 MQ 保证事务的最终一致性。
订单业务
用户下单后,订单系统需要
- 发送订单创建的消息给 MQ,并设置 TTL,经过设定的 TTL 后进入死信队列,监听死信队列的服务根据订单的状态(已支付/未支付)进行后续业务处理(交付仓储物流/关单库存解锁),实现自动关单
- 然后进入库存系统锁定库存
库存锁定
- 由于订单可能回滚,所以为了能够得到库存锁定的信息,在锁定时需要记录库存工作单(订单信息、商品信息、数量等)
- 库存保存在 Redis 中,收到请求后判断库存是否充足,然后减掉 Redis 中的库存(Redis 中的库存扣完就无法下单了)
- 锁定成功后向延迟队列发送消息(锁定的相关信息),实现库存自动解锁。然后修改对应的订单状态,进入支付流程
- 支付成功后订单进入出库状态,此时扣除数据库中的库存。如果中途失败,则取消订单,解锁库存等
库存自动解锁:库存锁定(Redis 中)后,也会有一个消息发送到延迟队列,经过 TTL 后根据订单状态和工作单状态来判断是否进行库存解锁,只有订单是过期的,且工作单的库存处于锁定状态才进行库存解锁。
自动关单和自动解锁库存两个业务通过重新查询当前的状态来保证幂等性。
优惠券业务
- 订单系统下单时,将扣减的优惠券事件放入消息队列中,最终优惠券系统会执行对应的业务,完成后通过手动确认的方式发送应答,告诉 MQ 删除这条消息,防止业务出现异常而消息已经被删除的问题。
- 同时订单系统需要将对应的优惠券消息写入数据库,并把状态设为未完成,优惠券系统在消费成功后,也向 MQ 发送一个消息,通知订单系统将这个订单的优惠券业务状态设为完成,这样,即使消息积压导致消息丢失,也能通过定时任务将未完成的消息重新发送,实现最终一致性。
MQ
消息丢失
MQ 本身有持久化机制,此外还有:
- 消息确认机制
- ConfirmCallback
- ReturnCallback
- ConsumerAck
- 消息生产端给每个消息注入一个唯一 ID,消费者基于 ID 进行校验,实现消息检测,防止消息丢失
注:分布式 ID 的生成可以使用 自增主键、UUID、Redis、雪花算法等
重复消费(幂等性)
防止消息被重复消费,也即解决消费者端幂等性问题。可以通过建立消息的日志表(MySQL/Redis),记录消息的 ID 和执行状态(未执行/已完成),然后根据消息的执行状态做进一步的判断处理。
消息积压
一般是消费者端的性能问题。
- 扩容,增加消费者的数量
- 降级一些非核心业务,减少服务端的压力
- 通过监控、日志等手段分析业务逻辑是否影响了性能
秒杀设计
- 服务单一职责 + 独立部署:秒杀服务即使自己扛不住挂掉,也不影响其他服务
- 秒杀链接加密:防止恶意攻击、链接暴露
- 库存预热 + 快速扣减:秒杀读多写少,无需每次实时校验库存,提前扣减库存放到 Redis 中,并用信号量控制进来的请求数
- 动静分离:nginx 做好动静分离,保证动态请求才打到后端的服务集群,并使用 CDN 网络分担集群压力
- 恶意请求拦截:网关层识别非法攻击请求并拦截
- 流量错峰:利用验证码、加入购物车等手段均摊流量
- 限流、熔断、降级:前后端限流,限制次数,快速失败降级运行,熔断隔离防止雪崩
- 队列削峰:所有秒杀成功的请求进入队列,慢慢处理后续流程
手写Spring
IoC
BeanFactory
最基本的可初始化的容器:DefaultListableBeanFactory 通过一层层的继承关系主要实现了两个接口:
- BeanFactory: Map 存储 BeanName 和 BeanDefinition(全限定类名+属性集合) 的映射关系
- SingletonBeanRegistry:Map 存储 BeanName 和单例 Bean 的映射,需要时候通过 BeanName 从 map 里获取 Bean 对象,如果获取的时候不存在对应的Bean对象,就从BeanFactory中取BeanDefinition实例化(反射/Cglib)后放入map
注:实例化一般就是反射创建对象,区别于拦截器通过Cglib动态创建代理对象
ApplicationContext
更进一步,ApplicationContext 组合了 BeanFactory(具有加载 BeanDefinition 和 存储 Bean 的功能),还提供了很多额外的扩展点,例如自动装载、后置处理器、Aware 接口、监听器等等。
注:BeanFactory是需要手动注册Bean的,获取时自动实例化。而Context创建时根据配置自动注册Bean。
创建 ApplicationContex 时,传入Bean的配置文件,然后进入 refresh() 方法,执行应用上下文的初始化:
- refreshBeanFactory:创建 BeanFactory 装载所有 BeanDefinition(包括各种处理器、监听器)
- invokeBeanFactoryPostProcessor:实例化所有 BeanFactoryPostProcessor 并执行后置处理
- registerBeanPostProcessor:实例化所有 BeanPostProcessor 并执行后置处理
- InitApplicationEventMulticaster:初始化事件发布器,创建所有 ApplicationListener 的集合用于事件处理
- registerListeners:实例化 ApplicationListener 并放入监听器集合
- preInstantiateSingletons:实例化所有单例 Bean
- finishRefresh:发布容器刷新完成事件
注:事件处理 publishEvent -> multicastEvent -> getListenersForEvent -> onApplicationEvent 具体的监听器负责对事件是否响应、如何响应
AOP
DefaultAdvisorAutoProxyCreator 是默认的代理创建器,基于容器中所有的 AspectJExpressionPointcutAdvisor 对当前要创建的 Bean 作匹配,然后通过 ProxyFactory 选择基于 JDK/CGLIB 创建实际的代理对象作为 Bean 返回,最终加入到容器中。(基于AspectJ实现的)
AspectJExpressionPointcutAdvisor 整合了切面 pointcut、拦截方法 advice、表达式 expression,能够基于 expression 做匹配,构建 AdvisedSupport(代理目标、拦截器)。
Bean 生命周期
让Bean实现DisposableBean(destroy), InitializingBean(afterPropertiesSet), Aware(setters)接口,在容器的各个阶段执行相应的生命周期回调。
循环依赖
Spring 框架设计解决循环依赖需要用到三个Map:
// 一级缓存,存放成品对象
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>();
// 二级缓存,存放未填充属性的半成品对象
protected final Map<String, Object> earlySingletonObjects = new HashMap<>();
// 三级缓存,存放代理对象
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>();
获取单例 Bean 方法如下:
public Object getSingleton(String beanName) {
Object singletonObject = singletonObjects.get(beanName);
if (singletonObject == null) { // 没有就到二级缓存中取
singletonObject = earlySingletonObjects.get(beanName);
if (singletonObject == null) { // 二级还没有去三级缓存找,只有代理对象才会放到三级缓存
ObjectFactory<?> singletonFactory = singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
//把三级缓存中代理工厂的真实对象取出来放入二级缓存
earlySingletonObjects.put(beanName, singletonObject);
singletonFactories.remove(beanName);
}
}
}
return singletonObject;
}
- 单例 Bean 在实例化后立刻放入三级缓存(非代理 Bean 是一个假工厂直接返回该对象)
- 当其他 Bean 依赖此 Bean 时从三级缓存中移除,取出真实对象放入二级缓存提前暴露出来。
- 当对象完全创建完成后,调用 registerSingleton 放入一级缓存,同时移除二级和三级缓存中的引用。
事务管理
编程式:transactionManager、TransactionTemplate
声明式:@Transactional(基于TransactionInterceptor)
- TransactionDefinition:事务定义信息
- 事务隔离级别
- 传播行为、超时
- 只读
- 回滚规则
- TransactionStatus:事务运行状态
- 是否回滚
- 暂停的外部事务
- 并且封装了一个实际的事务对象(Connection)
- TransactionManager:事务管理器,Spring 事务策略的核心管理器。
- getTransaction()
- commit()
- rollback()
- TransactionSynchronizationManager:基于ThreadLocal绑定线程事务,以及提供一些回调
public abstract class TransactionSynchronizationManager {
// 当前线程开启状态的所有数据库连接 Map
// key是DataSource数据源对象
// value是数据库连接ConnectionHolder
private static final ThreadLocal<Map<Object, Object>> resources = new NamedThreadLocal<>("Transactional resources");
// 事务同步器集合,可扩展的接口,定义了若干不同事物阶段的回调
private static final ThreadLocal<Set<TransactionSynchronization>> synchronizations = new NamedThreadLocal<>("Transaction synchronizations");
}
数据结构
排序算法
冒泡 $O(n^2)$, 选择 $O(n^2)$, 插入 $O(n^2)$, 归并 $O(nlogn)$, 快排 $O(nlogn)$, 堆排 $O(nlogn)$
查找算法
顺序查找、二分查找、哈希查找、树表查找(二叉排序树、平衡树、红黑树)
满二叉树和完全二叉树
满二叉树:每一层的节点数都达到最大值,即$2^{h-1}$个,其中h是树的高度。满二叉树的总节点数是$2^h-1$个。
完全二叉树:除了最后一层外,其他层的节点数都达到最大值,且最后一层的节点都连续集中在最左边。总节点数在$2^{h-1}$到$2^h-1$之间。
满二叉树一定是完全二叉树,但完全二叉树不一定是满二叉树。
图
一个图就是一些顶点的集合,这些顶点通过一系列边结对(连接)。
存储结构:邻接表、十字链表、邻接多重表
Prim算法:选已连通集合到未连通集合最小权值边的顶点
Kruscal算法:选最小权值边,直到构成一个连通图
哈希冲突
- 开放定址法:从发生冲突的那个单元起,按照一定的次序,从哈希表中找到一个空闲的单元。线行探查法、平方探查法、双散列函数探查法。
- 链地址法:将哈希值相同的元素构成一个同义词的单链表
- 再哈希法
- 公共溢出区
布隆过滤器
能够快速检索一个元素是否在给定的大集合中,一个布隆过滤器中有多个不同的哈希函数,
- 加入一个元素时,取哈希,对应位数组下标置 1
- 判断一个元素是否存在时,计算哈希判断对应位是否为 1。都为 1 则可能存在,只要有一位非 1,则一定不存在
使用场景:快速判断一个数是否存在于大数据量的集合中、防止缓存穿透、邮箱的垃圾过滤、黑名单功能、去重等。
计网
基础
TCP/IP 网络模型
物数网传会表应。其中只有应用层在用户空间,其它层都在 OS 内核中。
- 应用层:网络应用程序和网络之间的接口
- 表示层:负责把数据转换成兼容另一个系统能识别的格式
- 会话层:负责建立、管理和终止表示层实体之间的通信会话
- 传输层:负责端到端的数据传输
- 网络层:负责数据的路由、转发、分片
- 数据链路层:负责数据的封帧和差错检测,以及 MAC 寻址;
- 物理层:负责在物理网络中传输数据帧
键入网址到网页显示
- 对 URL 网址进行解析,生成 HTTP 请求消息
- 进行 DNS 查询:域名 -> IP地址
- 和目标服务器通过三次握手,建立 TCP 连接。连接建立后,封装 TCP 报文,交付网络层
- 网络层封装IP数据包,写入源 IP 地址、目标 IP 地址、协议等信息,然后交付网络接口层
- 网络接口层通过 ARP 协议获得下一跳 MAC 地址,封装数据帧发送出去。
- 数据包经过若干个交换机/路由器的转发,来到目标 IP 所在的子网,再交给目标 IP 对应的的服务器
- 服务器一层层解析数据包,根据端口交付给对应的进程。
- 进程将响应数据封装成 HTTP 响应报文,然后也一层层封装,发回给客户端进程,也就是浏览器。
- 客户端的浏览器对接收到的数据包解析,然后渲染整个网页的显示。
- 最后,如果没有别的数据请求了,双方就进行 TCP 四次挥手断开连接
内核收发数据包
应用程序通过系统调用,跟 Socket 层进行数据交互,经过传输层、网络层、网络接口层,最后由网卡负责接收和发送网络包。
接收
- 网卡接收到一个网络包后,通过 DMA 写入 RingBuffer 环形缓冲区
- 接着网卡向 CPU 发起硬件中断(屏蔽中断 -> 软中断 -> 取消屏蔽),唤醒数据接收服务程序
- 内核中的
ksoftirqd线程负责处理软中断,通过 poll 方法轮询处理数据(从 RingBuffer 取 sk_buff 帧交由协议栈,放入 Socket 接收缓冲区) - 应用层程序调用 Socket 接口,将接收缓冲区数据拷贝到应用层缓冲区,然后唤醒用户进程
发送
- 程序调用 socket 发送数据时,内核申请一个内核态的 sk_buff 内存,将待发送数据拷贝到 sk_buff 中,并加入发送缓冲区
- 网络协议栈从发送缓冲区中取出 sk_buff,向下逐层处理(对于 TCP,会拷贝一份 sk_buff 副本以支持重传)
- 网卡驱动程序从发送队列中读取 sk_buff,挂到 RingBuffer 中,并将数据映射到 DMA 内存区域,触发真实发送
- 发送完成后,网卡触发硬中断释放内存(sk_buff 和 RingBuffer,收到 ACK 后释放 TCP 数据包对应的原始 sk_buff)
期间共发生了三次内存拷贝:
用户数据 -> 内核 sk_buff -> TCP 拷贝 -> sk_buff 大于 MTU 时拷贝成多份小 sk_buff
网络分析
一般使用 tcpdump 在 Linux 下抓取数据包存入 pcap 文件,然后到 Wireshark 中进行分析
tcpdump -i <eth0> <protocol> and host <ip> -nn
- 数据格式:
时间戳 协议 源地址.源端口 > 目的地址.目的端口 网络包详情 - 数据链路层可以得到 源 MAC 地址、目标 MAC 地址、类型等
- IP 层可以得到 源 IP、目的 IP、TTL、IP 包长度、协议等字段
HTTP
HTTP 协议
超文本传输协议,超文本指文字、图片、视频等等信息,传输指在多个设备之间,协议指规定了通信的方式。
状态码
- 1xx 提示信息
- 2xx 成功。如 200 OK;204 No Content
- 3xx 重定向。如 301 永久重定向;304 资源未修改
- 4xx 发送报文有误。如 400 请求错误;404 资源不存在
- 5xx 服务器处理出错。如 500 服务器内部错误;503 服务器忙
字段
- Host: 服务器域名
- Content-Length: 本次回应的数据长度
- Connection: 是否使用长连接 Keep-Alive。只要任意一端没有提出断开,就保持TCP连接状态
- Content-Type: 服务器回应客户端本次数据的格式
Content-Type: text/html; Charset=utf-8 - Accept: 客户端声明自己接收的数据格式,
Accept: */*表示任意 - Content-Encoding / Accept-Encoding: 发送 / 可接受的压缩格式
HTTP 缓存
- 强制缓存:根据响应中的 Cache-Control (相对时间) 和 Expires (绝对时间) 判断请求是否过期,没过期直接从缓存中取响应结果
- 协商缓存:强制缓存没有命中时,可以与服务端协商之后,通过协商结果来判断是否使用本地缓存,一般响应 304 告知使用缓存。两种头部实现
- Last-Modified 和 If-Modified-Since 根据时间判断是否有更新
- Etag 和 If-None-Match 根据唯一标识判断 (类似CAS)
HTTP 优化
尽量避免发送 HTTP 请求
对于重复性的 HTTP 请求,通过缓存技术,避免发送请求。具体的:
- 客户端把第一次请求以及响应的数据保存在本地磁盘上,key 是 URL,value 是响应
- 响应过期后,再次发送请求会在 Etag 头部带上唯一标识响应的摘要,服务器将摘要和本地资源作比较
- 如果一致,响应 304 Not Modified,无需携带数据
减少请求次数
- 减少重定向请求次数:
如果资源转移了,且由代理服务器转发,可能产生多次重定向。而如果重定向的工作交由代理服务器完成,就能减少 HTTP 请求次数了 - 合并请求:
- 把多个访问小文件的请求合并成一个大的请求,减少重复发送的 HTTP 头部
- 例如对于很多小图片,可以使用 CSS Image Sprites 合成一个大图片;服务端 Webpack 工具打包 js/css 资源;图片二进制数据用 Base64 编码跟随 HTML 一起发送
- 但可能一个小资源变化后,必须重新下载整个大资源
- 延迟发送请求:
- 按需下载,用户滑动到某个元素才加载
减少响应数据的大小
- 无损压缩:例如霍夫曼编码、gzip,适用于文本、代码、可执行文件等
- 有损压缩:WebP/PNG、H264/H265…,适用于音频、视频、图片等
HTTPS 协议
HTTP 默认端口 80,HTTPS 默认端口 443。HTTPS 在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
- 混合加密:通信建立前基于非对称加密的数字证书交换
会话秘钥,通信过程中基于对称加密用会话秘钥来加密明文数据 - 摘要算法:通过哈希函数计算传输内容的指纹,保证消息完整性。
- 数字证书:将服务器公钥放在 CA 机构的数字证书中,只要证书是可信的,公钥就是可信的
非对称加密算法:RSA、DSA、ECDHE…
对称加密算法:DES、AES、RC5…
散列摘要算法:SHA1、SHA256、MD5…
TLS 握手
RSA 密钥协商算法
HTTP 完成 TCP 连接建立需要三次握手,而 HTTPS 还要进行 SSL/TLS 四次握手(2个RTT)。旧版 TLS 使用 RSA 算法实现:
- 第一次 - 客户端:
Client Hello包括 TLS版本 + client_random + 支持的密码套件 - 第二次 - 服务端:
Server Hello包括 确认 TLS 版本 + server_random + 选择的密码套件,以及Server Certificate内含数字证书、 - 第三次 - 客户端:
Client Key Exchange内含用服务端 RSA 公钥加密的新随机数pre-master- 然后双方基于三个随机数生成基于对称加密的会话密钥。
- 接着发送
Change Cipher Spec告诉服务端开始使用加密方式发送消息 - 最后发送
Encrypted Hashshake Message (Finished),对之前的数据做个摘要并用会话密钥加密,让服务器做验证,确保加密通信安全可用
- 第四次 - 服务端:也发送
Change Cipher Spec和Encrypted Hashshake Message,验证加密通信安全可用
RSA 算法缺陷:不支持前向保密,一旦服务端私钥泄露,过去所有被截获的 TLS 通信密文都会被破解。因此产生了 ECDHE 密钥算法。
改进:ECDHE 密钥协商算法
- 基于离散对数、ECC 椭圆曲线计算得到会话密钥
- 支持前向保密
数字证书
用来认证公钥持有者的身份,防止第三方进行冒充。
- 数字证书 = 公钥 + 持有者信息 + CA 机构信息 + CA 对这份文件的数字签名、算法、有效期等
- 其中数字签名由 CA 对持有者的相关信息 Hash 后用 CA 私钥加密而得
- 客户端从服务端拿到数字证书后,用 CA 公钥解密数字签名,与服务端信息做对比,一致则是可信赖的
HTTP 演进
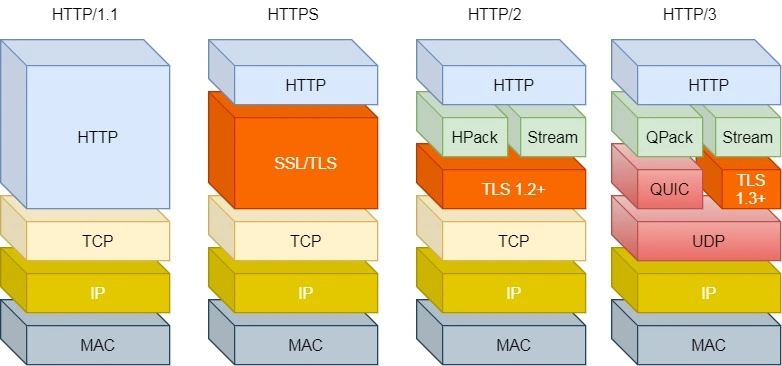
HTTP/1.1
优点:简单、灵活、易于扩展、应用广泛、跨平台。相比于1.0,HTTP/1.1 使用长连接减少连接建立释放的开销,支持管道化传输,可以一次发起多个请求
缺点:
- 无状态,得用Cookie解决
- 不安全:明文传输
- 性能一般:存在响应的队头阻塞问题(HTTP 完成一个请求+响应才能处理下一个)
HTTP/2
- 基于HTTPS,安全性得到保证
- 头部压缩:HPack 算法压缩 Header 部分固定重复的字段
- 二进制帧:分数据帧和控制帧两类
- 多路复用:一个 TCP 连接包含多个 Stream,不同的 HTTP 请求通过 Stream ID 区分
- 支持服务器主动推送(偶数号 Stream)
- 缺陷:由于基于TCP,仍然存在 TCP 层队头阻塞问题(只有前一个字节数据到达,后面的字节数据才能从内核缓冲区中取出)
HTTP/3
使用基于 UDP 的 QUIC 协议(一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用协议)。特点:
- 单向递增的 Packet Number,配合 StreamID 和 Offset 字段,支持乱序确认而不影响数据包的正确组装
- 无队头阻塞:多个 Stream 之间独立,互不影响。某个流发生丢包仅影响该流
- 更快的连接建立:QUIC 本身包含 TLS 1.3,一个 RTT 内就可以完成连接建立和密钥协商
- 支持连接迁移:通过
连接ID标记通信的两个端点,避免网络切换后的握手、慢启动造成网络卡顿 - 优化 HTTP 层:简化帧结构、QPack 压缩算法
Get 和 Post
- Get 的语义是从服务器获取指定的资源,请求的参数一般是以 KV 形式写在 URL 中(浏览器会对 URL 的长度有限制, HTTP协议没有)
- POST 的语义是根据请求体对指定的资源做出处理,请求携带的数据一般是在报文 body 中,格式任意,大小不限
- Get 方法是安全且幂等的,不会破坏服务器上的资源,且多次执行的结果相同(因此 GET 请求的数据可以缓存,POST 需要手动设置)。
- Post 方法不是安全,也不是幂等的。
HTTP 请求都是明文,因此GET/POST都不安全,此外GET没有规定不能携带请求体,POST请求URL也可以有参数。
对比 RPC
纯裸 TCP 可以收发数据,但它是个无边界的数据流,上层需要定义消息格式用于定义消息边界。于是就有了各种协议,HTTP 和各类 RPC 协议就是在 TCP 之上定义的应用层协议。RPC本质上是一种调用方式,具体的实现 gRPC/Thrift 才是协议,目的是希望程序员能像调用本地方法那样去调用远端的服务方法。当然 RPC 也不一定非得基于 TCP。
区别:
- 服务发现:RPC一般有专门的中间服务,如 Zookeeper 来保存服务名和IP信息(HTTP当然也能实现)
- 底层连接形式:RPC使用连接池
- 传输内容:HTTP报文非常冗余,而RPC定制化程度高,性能也更好。因此内网服务之间通常使用 RPC。
不过,HTTP/2 通过压缩做了很多改进,性能甚至优于RPC,例如 gRPC 基于 HTTP/2 实现。但由于历史原因,RPC仍在使用。
TCP
TCP/UDP 区别
- TCP是有连接的、面向字节流的可靠传输协议。
- UDP是无连接的,面向数据报的协议,尽最大努力交付,不保证可靠传输。
- TCP提供流量控制,即源端通过滑动窗口来告诉对端自己的发送窗口大小,从而控制对端发送数据的速度;UDP没有流量控制。
- TCP提供拥塞控制,即当网络拥塞时,TCP会降低自己的发送速度,从而避免网络拥塞的恶性循环;UDP没有拥塞控制。
- TCP开销大,头部至少20个字节,而UDP头部固定只有8个字节。
三次握手
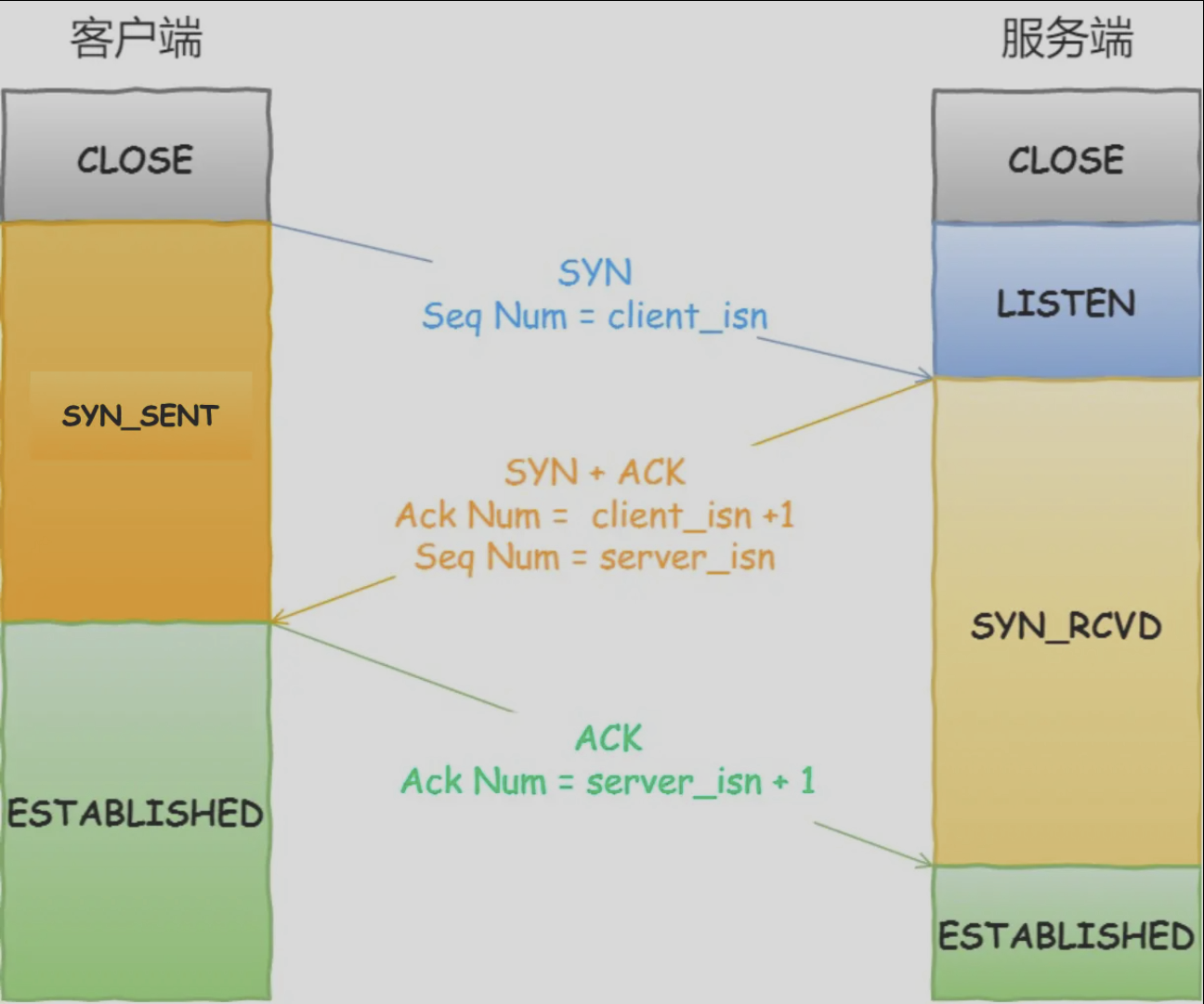
过程:
- 首先服务端主动监听某个端口,处于 Listen 状态
- 客户端随机一个序列号,并发送 SYN 报文给服务端。此时客户端处于 SYN-SENT 状态
- 服务端接收到客户端的 SYN 报文后,也随机一个序列号,然后发送 SYN+ACK 报文给客户端,并且确认客户端报文的序列号。此时服务端处于 SYN-RCVD 状态
- 客户端收到服务端报文后,序列号+1,再次向服务端回应一个 ACK 报文,同时确认服务端报文的序列号。此次报文已经可以携带数据了。之后客户端处于 ESTABLISHED 状态
- 服务端收到客户端应答报文后,也进入 Established 状态。三次握手完成。
TCP 通过 (源IP、源端口、目的IP、目的端口) 这样的四元组来唯一确定一条连接。
为什么需要三次握手:
- 首要原因是防止旧的(阻塞在网络中)重复连接初始化造成混乱。如果只有两次握手,服务端没有中间状态给客户端来阻止旧连接,导致连接释放后服务端又建立一个旧连接,造成资源浪费。
- 同步双方的初始序列号,两次握手只能保证服务端确认了客户端的序列号,不能保证客户端确认了服务端的序列号。
握手丢失
- 第一次握手 SYN 丢失: 触发超时重传,Linux 会重传 5 次,且超时时间 RTO 呈指数上涨(翻倍 1 -> 3 -> 7 -> 15 -> 31)
- 第二次握手 SYN + ACK 丢失:客户端重传 SYN,服务端重传 SYN + ACK,一直重传至最大次数
- 第三次握手 ACK 丢失:服务端处于 SYN_RECV 状态,一直重传 SYN + ACK 直至最大次数后断开连接。客户端处于 Established 状态,由于 TCP 保活机制,可能持续 2 小时才会发现该连接已失效,而如果客户端已经发送数据了,会一直重传数据包直至最大次数(默认 15 次)
注:
- 所有重传次数都有
/proc/sys/net/ipv4/下的内核参数限定 - 网络包进主机顺序:Wire -> NIC -> tcpdump -> netfilter/iptables(防火墙)
- 网络包出主机顺序:iptables -> tcpdump -> NIC -> Wire
四次挥手
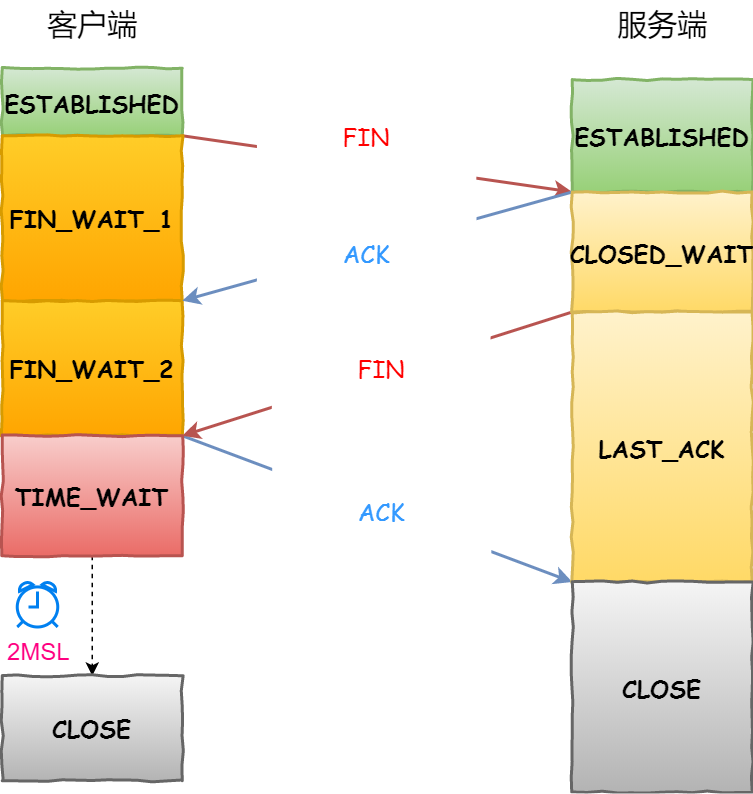
过程:
- 客户端打算关闭连接时,会发送一个 FIN 报文,之后客户端进入 FIN_WAIT_1 状态。
- 服务端收到该报文后,回复一个 ACK 应答,进入 CLOSE_WAIT 状态。
- 客户端收到服务端的 ACK 应答后,进入 FIN_WAIT_2 状态。
- 等服务端处理完数据后,也向客户端发送 FIN 报文,之后服务端进入 LAST_ACK 状态。
- 客户端收到服务端的 FIN 报文后,也回复一个 ACK 应答,之后进入 TIME_WAIT 状态
- 服务端收到了 ACK 应答报文后,就进入了 CLOSE 状态,至此服务端已经完成连接的关闭。
- 客户端在经过 2MSL(最大报文生存时间,Linux中为30s) 时间后,自动进入 CLOSE 状态,至此客户端也完成连接的关闭。
为什么需要四次挥手?
- 关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据。
- 服务端收到客户端的 FIN 报文时,先回一个 ACK 应答报文,而服务端可能还有数据需要处理和发送,等服务端把这些数据都处理发送完,才发送 FIN 报文给客户端来表示现在同意关闭连接。
也就是要等待服务端把手上的数据处理发送完再关闭。
为什么需要 TIME_WAIT 状态?
- 等待 2MSL 让两个方向上现有的数据包都被丢弃,使得旧连接的数据包在网络中都自然消失,防止被后面相同四元组的新连接错误的接收
- 等待足够的时间以确保第四次挥手的 ACK 能让服务端接收,从而帮助其正常关闭
TIME_WAIT 会占用系统资源,因此在高并发下可以适当调整该时间,避免资源浪费和连接延迟。例如开启 tcp_tw_reuse 重用处于 TIME_WAIT 状态的连接,并开启 PAWS 防回绕时间戳(双方维护最近一次收到数据包的时间戳)
三次挥手
如果第一次挥手后,如果被动关闭方接收到 FIN 且没有数据要继续发送,同时开启了 TCP 延迟确认机制,那么第二、三次挥手 ACK+FIN 可以合并传输,实现三次挥手。
TCP 延迟确认:没有响应数据要发送时,ACK 将延迟一段时间随数据一块发送,以提高网络效率。
重传机制
超时重传:
在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文(数据包丢失/确认应答丢失),就会重发该数据。
问题:超时重传时间 RTO 的设定,理论上应略大于 RTT。但RTT无法准确计算,Linux采用加权移动平均,采样估计。
快速重传:
当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。
问题:重传时是重传一个还是重传所有已经发出去的数据包,只重传一个可能造成延迟重传,重传所有可能浪费网络资源
SACK: Selective ACK
在 TCP 头部「选项」字段里加一个 SACK,将已收到的数据信息发给「发送方」,这样发送方就可以只重传丢失的数据。
Duplicate SACK:
使用 SACK 来告诉「发送方」有哪些数据被重复接收了,这样「发送方」就知道数据没有丢,是「接收方」的 ACK 确认报文丢了。
流量控制
流量控制是为了避免「发送方」的数据填满「接收方」的缓存,并不涉及整体网络中的流量。
滑动窗口:
为了提高网络的传输效率,引入滑动窗口,双方各自维护发送窗口和接收窗口。在发送窗口范围内的数据都可以发送出去,窗口后延之外的数据都是暂时不能发送的数据。随着接收到的数据,窗口会向后移动。
一般由接收方告诉发送方自己还有多少缓冲区可以用于接收数据,发送方根据接收方的处理能力调整窗口大小。但双方窗口只是近似相等,传输过程存在延迟,窗口也时刻在变化。发送窗口 = min(拥塞窗口,接收窗口)
优化点
- 为了防止资源紧张时,操作系统减小缓存,同时收缩窗口,导致丢包和窗口变负值的情况,TCP规定必须先收缩窗口,再减少缓存。窗口缩减为0后,需要定时发送窗口探测报文,确认当前窗口大小,避免双方持久等待。
- 糊涂窗口综合征:发送方为了填满接收方几个字节的窗口,发送一整个 TCP 报文,而 TCP + IP 首部就有40字节,会造成极大资源浪费。
- 接收方在窗口小于 min(MSS, 0.5*cache) 时,就发送0窗口通告
- Nagle 延迟处理算法:必须等窗口 >=MSS 且数据大小 >= MSS,或者收到之前发送数据的 ACK,才会继续发送;否则一直囤积数据。
- 接收方不通告小窗口 + 发送方开启 Nagle 算法,才能避免糊涂窗口综合症。
拥塞控制
拥塞控制是为了避免「发送方」的数据填满整个网络,由发送方维护,根据网络的拥塞程度动态变化。(以下窗口大小的单位都是 MSS,而不是个)
慢启动
指在刚刚加入网络的连接中,一点一点地提速,不要一上来就把链路占满。开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。每当收到一个ACK,cwnd+1;也就是说每经过一个RTT,cwnd = cwnd*2,呈指数上升。阈值ssthresh(slow start threshold)慢启动门限是一个上限,当cwnd >= ssthresh时,就会进入拥塞避免算法。
拥塞避免
cwnd超过慢启动门限后,每收到一个ACK,cwnd = cwnd + 1/cwnd;也就是说每经过一个RTT,cwnd = cwnd + 1。此时发包数呈线性增长,避免增长过快导致网络拥塞。
拥塞发生
一旦发生丢包、延时导致重传,进入拥塞发生阶段:ssthresh = 0.5 * cwnd,cwnd重置为1 (Linux初始值为10)
快重传
当接收方发现一个乱序到达的报文段,就会发送三次前一个包的 ACK。发送端接收到三个相同的ACK报文,就会进行快速重传,不必等到超时再重传。这时设置 cwnd /= 2,ssthresh = cwnd,进入快恢复。
快恢复
快速恢复算法是认为,如果还能收到 3 个重复的 ACK 说明网络也没那么糟糕,因此没必要像 RTO 超时那么强烈。此时发送方把 ssthresh 设为当前 cwnd 的一半
半/全连接队列
TCP 三次握手时,Linux 会维护两个队列:
- 半连接队列,也称 SYN 队列,底层是哈希表
- 服务端收到客户端的 SYN 后,内核会把该连接存储到半连接队列中,并响应 SYN + ACK
- SYN 洪泛攻击、DDos 都是半连接队列溢出
- 全连接队列,也称 accept 队列,底层是链表
- 服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列中移除,然后创建新的完全连接加入全连接队列,等待进程调用 accept 把连接取出
不管是半连接,还是全连接队列,都有最大长度限制,超过后会直接丢弃或返回 RST 包。需要注意,TCP 三次握手的过程是发生在 accept 调用之前的。
TCP 优化
三次握手
- 客户端:可以根据网络稳定性、目标服务器繁忙程度修改 SYN 重传次数,调整握手时间上限。例如在内网中降低重试次数,尽快把错误暴露给应用程序
- 服务端:调整半/全连接队列长度、SYN+ACK 报文重传次数
- 绕过三次握手:tcp_fastopen 减少一个 RTT
四次挥手
- 主动方:调整 FIN 报文重传次数、FIN_WAIT2 状态时间、孤儿连接上限
分片问题
如果TCP层不进行分片,仅在IP层分片,那么当一个TCP报文段的某个IP分片丢失,接收方的IP层无法组装成一个完整的TCP报文,也就不会响应ACK给发送方。于是发送方就会一直等待直到超时重传,因此由IP层进行分片传输效率很低。
所以,为了达到最佳的传输效能 TCP 协议在建立连接的时候通常要协商双方的 MSS 值,使得IP包长度不会大于MTU,也就不用IP分片了。这样即使一个IP分片丢失,进行重发时也是以 MSS 为单位。
粘包问题
对于UDP,OS不会对消息进行拆分,每个UDP报文就是一个完整的用户消息。
而对于TCP,消息可能会被操作系统分组成多个 TCP 报文,因此接收方的程序如果不知道发送方发送的消息长度/边界,就无法读出一个有效的用户消息。因此我们说 TCP 是面向字节流的协议。
当两个消息各自的部分内容被分到同一个 TCP 报文时,即产生 TCP 粘包问题,这时接收方如果不知道消息边界的话,无法读出有效的信息。
解决方法
- 固定长度的消息:不灵活
- 特殊字符作为边界:两个用户消息之间插入特殊字符,例如 HTTP 协议通过回车符+换行符作为报文的边界(注意转义)
- 自定义消息结构:分包头和数据,在包头里记录数据部分的长度,接收方通过解析包头就可以知道消息的边界了。
序列号和确认号
序列号
- 初始序列号:TCP 建立连接时,客户端和服务端基于时钟、源/目的 IP/端口 生成的随机数
- 序列号:TCP 头部的一个 32位 无符号数字段,到达 4G 后归零。标识了 TCP 发送端到 TCP 接收端的数据流的一个字节,用于传输确认、丢失重传、有序接收。
- 序列号 = 上一次发送的序列号 + 数据长度。如果上一次是 SYN/FIN,则改为上一次序列号 +1
客户端和服务端随机生成初始序列号,以避免历史报文被下一个相同四元组的连接接收。但也无法完全避免,可以开启 TCP 时间戳机制,防止序列号回绕。
- 合法的序列号:报文的序列号比
期望下一个收到的序列号要大 - 合法的时间戳:报文的时间戳比
最后收到的报文时间戳要大
确认号
指下一次「期望」收到的数据的序列号,发送端收到接收方发来的 ACK 确认报文以后,就可以认为在这个序号以前的数据都已经被正常接收。用来解决丢包的问题。
- 确认号 = 上一次收到的报文序列号 + 数据长度。如果收到的是 SYN/FIN,则改为上一次序列号 +1
保活机制
如果两端的 TCP 连接一直没有数据交互,达到了触发 TCP 保活机制的条件,并且开启了 TCP-keepalive 机制,那么内核里的 TCP 协议栈就会发送探测报文。
- 如果对端正常响应,那么 TCP 保活时间重置,等待下一次保活时机到来
- 如果对端连续几次没有响应,达到保活探测次数后,TCP 会报告该 TCP 连接已死亡
如果没有开启 TCP-keepalive,并且双方都没有进行数据传输,那么客户端和服务端的 TCP 连接将会一直保持存在。
关闭连接
关闭 socket 有两个系统调用:
- close() 同时关闭 socket 发送方向和读取方向,使得 socket 不再有发送和接收数据的能力。但如果多线程共享该 socket,则 close() 会让引用计数 -1,只要引用计数非0,其它线程还可以正常读写该 socket
- shutdown() 可以指定仅关闭 socket 发送方向/读取方向。如果多线程共享该 socket,则其它线程将受到影响
因此,close() 是一种粗暴的关闭方式,不会经历四次挥手的过程,等到对端发送数据恢复 RST 才能正确关闭连接。
粗暴的关闭进程可以关闭 TCP 连接,但不优雅。可以通过伪造 RST 报文来关闭连接,但要同时满足四元组相同、序列号是对方期望的两个条件。
killcx工具:- 主动向处于 Established 状态的服务端发送 SYN,接收 Challenge ACK,获得服务器期望的序列号和确认号
- 利用 Challenge ACK 信息伪造两个 RST 报文发送给客户端(序列号)和服务端(确认号),让它们优雅地释放连接
tcpkill工具:- 在双方进行 TCP 通信时,拿到对方下一次期望的序列号,然后伪造 RST 报文来关闭连接
- 仅适用于活跃的 TCP 连接
如果进程崩溃,OS 内核会自动发送 FIN 完成 TCP 四次挥手关闭连接;而如果主机宕机,对端是无法感知的,需要 TCP 保活机制来探测主机是否正常。在 Linux 中,需要至少 2H 11min 15s 才能发现一个死亡连接。
IP
IP 地址
- ABCDE 地址 -> CIDR 无分类地址
- IP 地址 & 子网掩码 = 网络号
- IPv4 地址 32 位,而 IPv6 地址 128 位,且支持自动分配 IP 地址,简化包头,提高传输性能,提升了安全性
- localhost 是一个域名,不过会解析成 127.0.0.1 本地回环地址
ping 127.0.0.1/本地IP最后都会走 本地回环接口(假网卡),然后插入input_pkt_queue链表后,通过软中断通知ksoftirqd接收数据,因此断网也能 Ping 通- 如果服务器 listen 的是 0.0.0.0,表示监听本机的所有 IPv4 地址
IP 和 MAC 地址
- MAC 地址的作用是实现「直连」的两个设备之间通信,在网络传输寻址过程中是一直变化的。
- 而 IP 则负责在「没有直连」的两个网络之间进行通信传输,源IP地址和目标IP地址在整个传输过程中是不会变化的(除非 NAT)
- 如果只用 MAC 地址,路由器就需要记住每个MAC地址所在的子网,而 MAC 地址有48位,路由器无法存储这么多子网信息
- IP 地址是设备上线以后,才能根据进入哪个子网来分配的,在设备还没有 IP 的时候需要用 MAC 地址来区分不同的设备
IP 地址类似住址门牌号,住在不同地方就有不同门牌号,快递根据门牌号找到所在位置。而 MAC 地址类似身份证号,设备出厂就固定写死了,但是知道身份证号是没法找到人的,身份证号和地理位置无关。
DNS
域名解析协议,域名 -> IP地址
查询顺序:
- 浏览器缓存 -> OS缓存 -> 本地DNS (主机和本地DNS服务器之间递归查询)
- 还没有就由本地DNS发出查询:根DNS -> 顶级DNS -> 权威DNS (DNS服务器之间迭代查询)
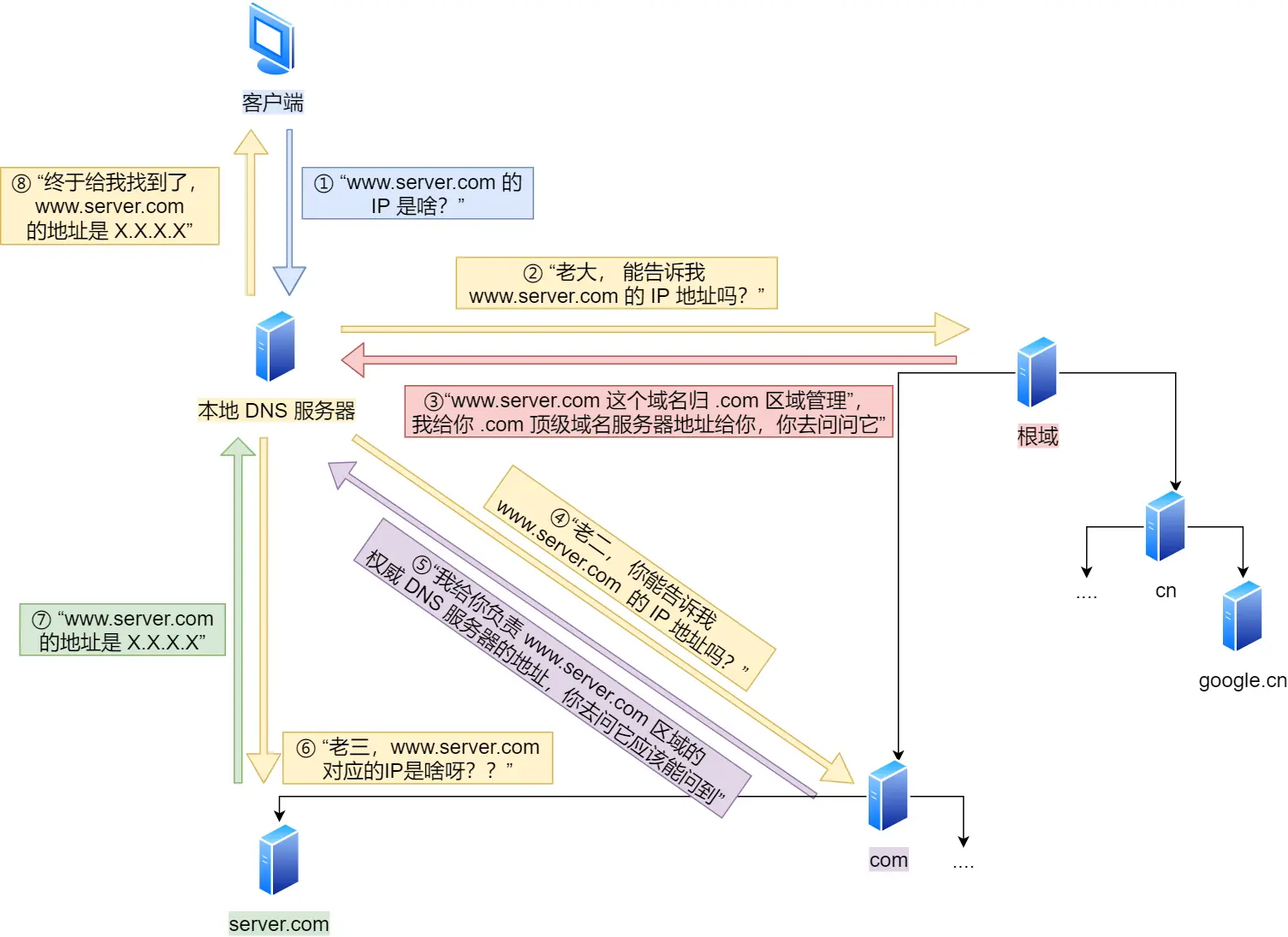
ARP
地址解析解析,IP -> MAC
原理:广播 ARP 请求 -> 解包匹配 -> 单播 ARP 响应 -> 有限缓存
RARP:MAC -> IP,用于打印机服务器等小型嵌入式设备接入网络
DHCP
动态主机配置协议,动态获取IP地址
原理(全程 UDP广播):
- 客户端(0.0.0.0:68)使用 UDP 广播(255.255.255.255:67),发起 DHCP DISCOVER
- DHCP 服务器响应 DHCP OFFER,携带可租约的 IP 地址、子网掩码、默认网关、DNS 服务器以及 IP 地址租用期等信息
- 客户端收到一个 DHCP OFFER 后,回复 DHCP REQUEST,回显配置的参数
- DHCP 服务器响应 DHCP ACK 确认配置信息
ICMP
互联网控制报文协议,用于确认 IP 包是否成功送达目标地址、报告发送过程中 IP 包被废弃的原因和改善网络设置等。
分类:
- 用于诊断的查询报文
- 如 Ping 命令利用 ICMP-回送请求、ICMP-回送应答 两类报文
- 用于通知出错原因的差错报文
- 如 Traceroute 命令利用 ICMP-超时消息 报文,通过设置特殊的 TTL 追踪沿途路由,以及一个不可能的端口号(ICMP-端口不可达)标记已到达目的主机
- 如 Traceroute 命令利用 ICMP-禁止分片 报文,通过设置不分片确定路径上合适的 MTU 大小
NAT
网络地址转换协议。基于转换表将 私有IP -> 公有IP(通常用 NAPT:网络地址和端口转化协议,私有IP + 端口 -> 共有IP + 端口)
缺点:外网无法主动连接、性能开销大、重启连接断开
解决:IPv6、NAT穿透(应用程序主动建立端口映射)
IGMP
因特网组管理协议。用于维护 IGMP 路由表,管理加入、离开组播组的主机
操作系统
硬件结构
冯诺依曼结构
运算器、控制器、存储器、输入设备、输出设备
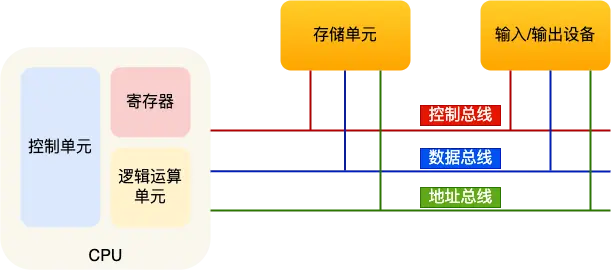
- CPU = 控制单元 + 逻辑运算单元 + 寄存器
- 寄存器分 通用寄存器、指令寄存器、程序计数器
- 总线分 地址总线(指定内存地址)、控制总线(指定读/写)、数据总线(传输数据)
指令
指令周期的四级流水线:Fetch -> Decode -> Execute -> Store
硬件32/64位指CPU位宽,软件32/64位指指令的位宽。
64位相比32位的优势:
- 64位CPU可以一次计算超过32位的数字,但很少有程序计算这么大的数字,只有计算大数字才能体现超过32位CPU的性能
- 64位CPU可以寻址更大的物理内存空间,32位最高寻址4G
多级存储器
- 寄存器: 一般在半个CPU周期内完成读写
- CPU Cache:RAM 静态随机存储器,断电丢失。
- L1:2-4个时钟周期,几十KB。分数据缓存、指令缓存
- L2:10-20个时钟周期,几百KB
- L3: 20-60个时钟周期,几十MB。多核共享
- 内存:DRAM 动态随机存取存储器,电容需要定时刷新。200-300个时钟周期
- SSD/HDD 硬盘:断电后数据不丢失,SSD比内存慢 10-1000 倍,HDD比内存慢 10W 倍
每个存储器只和相邻的一层存储器设备进行交互,形成缓存体系。
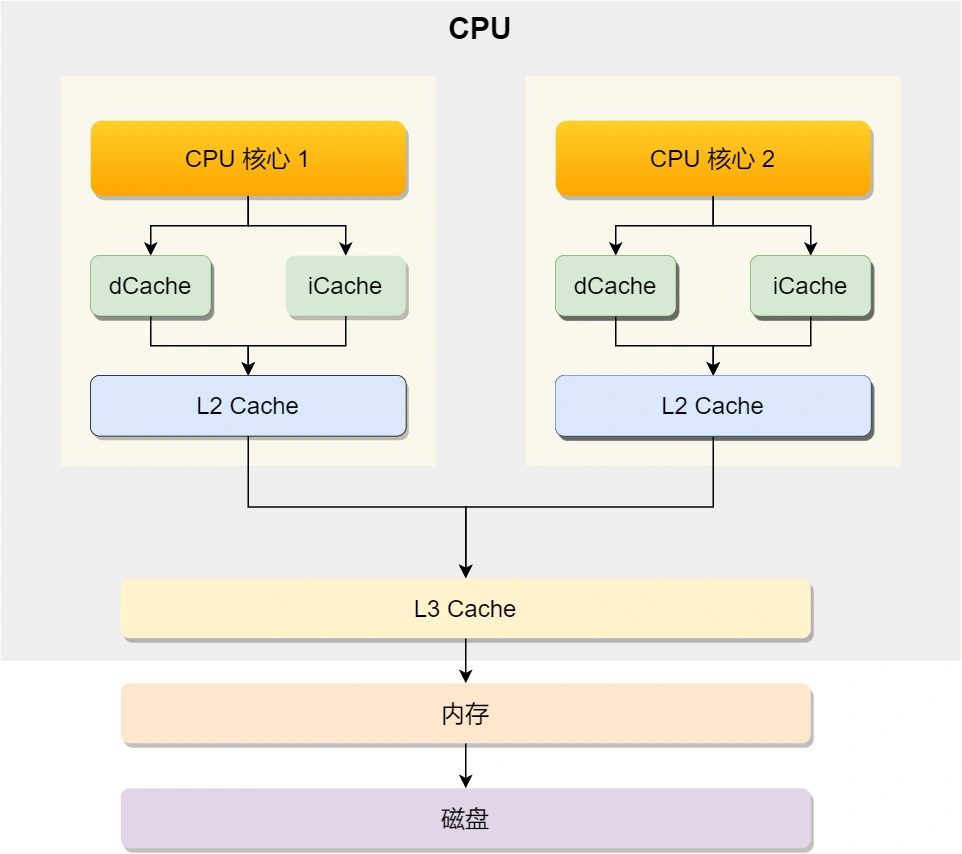
CPU Cache
CPU Cache 是由很多个 Cache Line 组成的,Cache Line 是 CPU 从内存读取数据的基本单位(例如一次载入 64Byte),由各种标志(Tag)+ 数据块(Data Block)组成。
直接映射
- 通过取模运算,计算内存块对应的 Cache Line 地址
- 组标记 Tag: 记录是否是对应的内存块(因为多个内存块会映射到同一个 Cache Line)
- 有效位 Valid Bit:标记数据是否还有效
- 偏移量 Offset:定位 CPU 读取 Cache Line 中哪个 Word 字
因此,一个内存的访问地址由 组标记、Cache Line 索引、偏移量 三者共同定位。其它映射例如全相联、组相联等类似。
提升缓存命中率
提升缓存命中率,也就可以提升程序执行速度,优化方法例如:
- 按内存布局顺序访问
- 有规律的条件分支语句可以充分利用 CPU 的分支预测器
- 当有多个同时执行的「计算密集型」线程,可以把线程绑定在某一个 CPU 核心上,避免线程在不同核心来回切换,影响缓存命中率。
写入数据
- 写直达 Write Through:把数据同时写入内存和Cache。每次写操作都会写回内存,消耗性能
- 写回 Write Back:将新数据写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中。
缓存一致性问题
由于 L1/L2 Cache 是多个核心各自独有的,因此可能带来多核心的缓存一致性问题。因此需要一种同步机制,能够实现:
- 写传播:某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache。
- 实现方法:总线嗅探,每个 CPU 核心监听总线上的广播事件,检查是否有相同的数据在自己的 L1 Cache 里,如果有事件就更新。会加重总线负载,且不能保证事务串行化
- 事务串行化:某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的
- 实现方法:MESI协议,标记 Cache Line 的四种不同状态
Modified:已修改。Cache 数据和内存中数据不一致,可以自由写入,被替换时需要写回内存。Exclusive:独占。仅一个核心存储该 Cache Line,可以自由写入,不需要通知其它核心。如果其它核心从内存读取了该 Cache Line,那么将转为共享状态Shared:共享。修改时需要向所有其它核心广播请求,要求把该 Cache Line 标记为无效,然后再更新Invalidated:已失效。数据不一致,不可以读取该状态数据。
伪共享
由于多个线程同时读写同一个 Cache Line 的不同变量,而导致 CPU Cache 失效的现象。
解决方案:
- Cache Line 大小字节对齐(空间换时间)
- 字节填充,例如 Disruptor 中的 RingBuffer 类数据前后填充 long,使得无论怎么加载 Cache Line,这整个 Cache Line 里都没有会发生更新操作的数据
CPU 调度
Linux 内核中,无论是进程还是线程,调度的都是 task_struct 结构体,区别在于线程的task_struct部分资源是共享了进程已创建的资源,如内存地址空间、代码段、文件描述符等。
调度器
- Deadline:对应 dl_rq 运行队列
- Realtime:对应 rt_rq。
- Fair: 对应 cfs_rq。完全公平调度,优先选择 vruntime 少的任务,用于普通任务,内部组织成红黑树结构
调度优先级从上到下,dl_rq -> rt_rq -> cfs_rq,也即实时任务总是先于普通任务被执行。
进程优先级可以通过 nice | renice 设置/更改,范围 -20~19,是一个修正值,nice 值越小优先级越高。
中断
中断是系统用来响应硬件设备请求的一种机制,操作系统收到硬件的中断请求,会打断正在执行的进程,然后调用内核中的中断处理程序来响应请求。中断是一种异步的事件处理机制,可以提高系统的并发处理能力。
Linux 为了解决中断处理程序执行过长和中断丢失的问题,将中断处理程序分成了两个阶段:
- 上半部:直接处理硬件请求,也就是硬中断。
- 负责耗时短的工作,特点是快速执行,一般会暂时关闭中断请求。例如处理跟硬件相关或时间敏感的事情。
- 下半部:由内核触发,也就是软中断。
- 负责上半部未完成的工作,特点是延迟执行,通常耗时较长。
另外,硬中断会打断 CPU 正在执行的任务,然后立即执行中断处理程序。每个 CPU 都对应一个软中断内核线程,名为ksoftirqd/CPU.no
watch -d cat /proc/softirqs 可以监控软中断变化,[]内的是内核线程
数值存储
负数用补码表示:统一和正数的加减法操作
十进制转二进制:整数除 2 取余并反转,小数乘 2 取整
浮点数存储:
$(-1)^\text{符号位} * (1 + \text{尾数}) * 2^{\text{指数} - 127}$
- 尾数位决定了浮点数的精度
- 指数位决定了浮点数的表示范围
由于计算机存储浮点数有位数限制,有的小数无法用「完整」的二进制来表示,所以只能以近似值保存。进而,两个近似数相加,得到的必然也是一个近似数。
OS 结构
内核态和用户态
内核具有很高的权限,可以控制 cpu、内存、硬盘等硬件,而应用程序具有的权限很小,因此 OS 把内存分成了两个区域:
- 内核空间:这个内存空间只有内核程序可以访问
- 用户空间:这个内存空间专门给应用程序使用
用户空间的代码只能访问一个局部的内存空间,而内核空间的代码可以访问所有内存空间。因此,程序使用用户空间即该程序在用户态执行,程序使用内核空间即程序在内核态执行。应用如果需要进入内核态,需要通过中断发起系统调用,内核处理完后再触发中断回到用户态。
内核设计
- Linux 是宏内核设计,包含多个模块,整个内核像一个完整的程序,且拥有最高的权限
- Windows 是混合型内核,微内核(内核只保留基本能力)基础上搭建其它模块
内存管理
虚拟内存
为了在多进程环境下,使得进程之间的内存地址不受影响,相互隔离,于是 OS 提供一种机制,将不同进程的虚拟地址和内存的物理地址映射起来。程序仅访问虚拟地址,由 OS 转换成不同的物理地址。
- 程序中使用的地址叫虚拟内存地址
- 硬件里的空间地址叫物理内存地址
每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
内存分段
程序由若干个逻辑段组成,例如代码分段、数据分段、栈段、堆段。不同的段有不同的属性,于是用分段的形式把这些段分离出来。
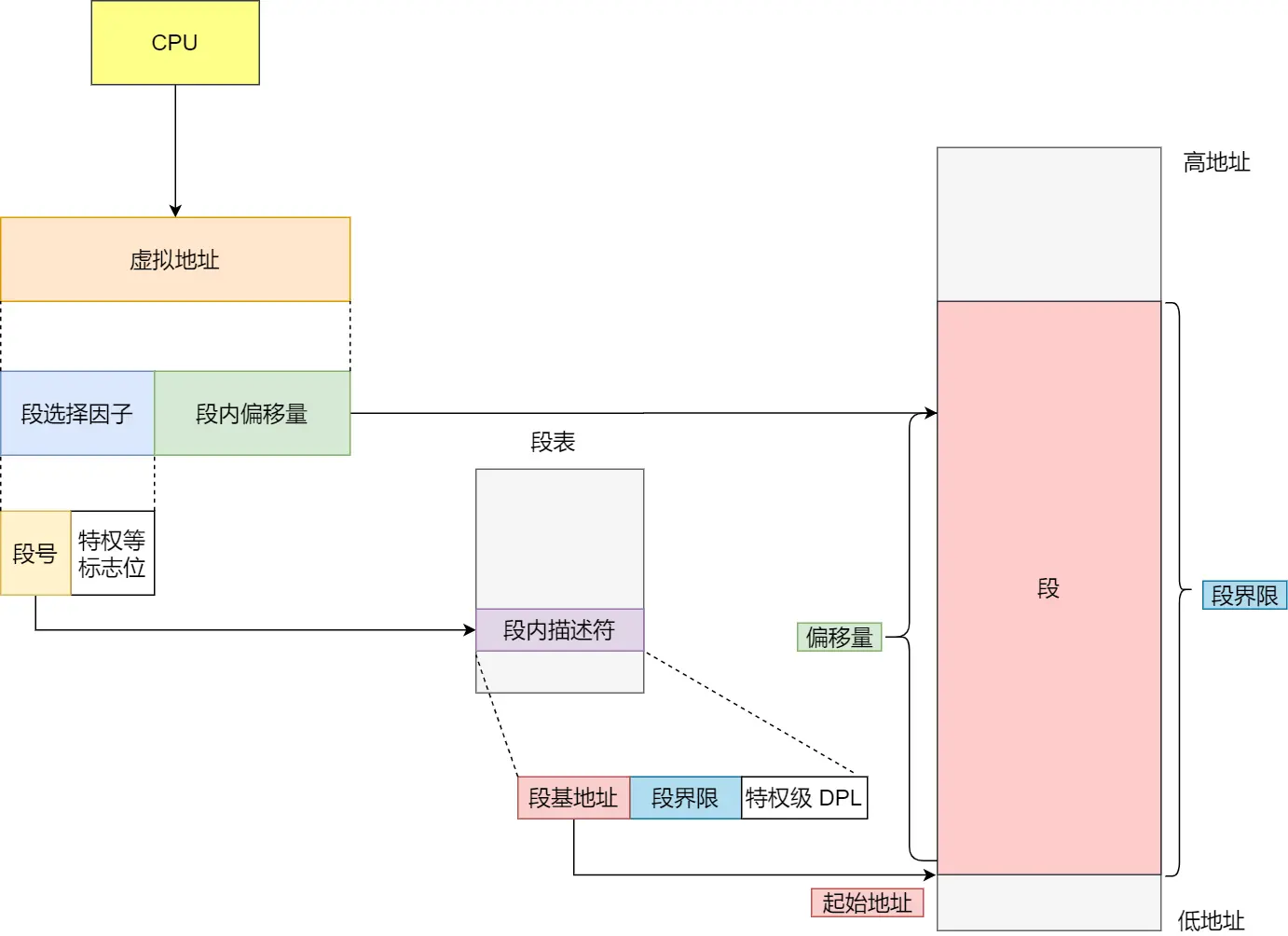
分段机制下的虚拟地址由两部分组成:
- 段选择因子: 保存在段寄存器里,包括两部分:
- 段号:段表的索引,段表 = 段基地址 + 段界限 + 特权等级
- 特权标志位
- 段内偏移量:段基地址 + 段内偏移量 -> 物理内存地址
缺陷:
- 内存碎片:主要是外部内存碎片,不连续内存空间导致无法加载一个新进程。可以通过内存交换解决(也就是Swap分区)
- 内存交换效率低:内存交换需要在硬盘和内存间交换数据,硬盘速度太慢,如果交换一个很大的空间,将造成卡顿
内存分页
为了解决内存分段的「外部内存碎片和内存交换效率低」的问题,就出现了内存分页。分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小,这样的一个连续且尺寸固定的内存空间叫页(Linux下一页4KB)。
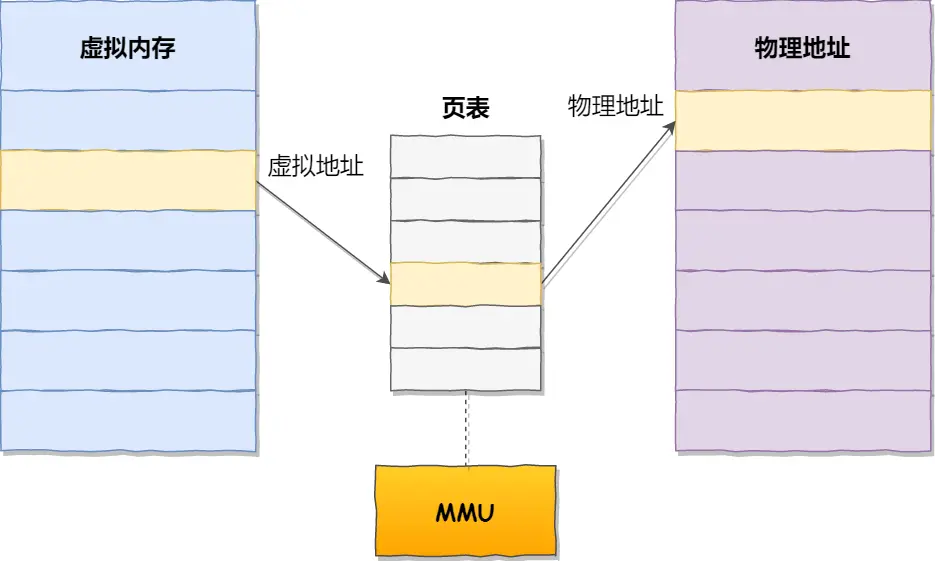
分页机制下的虚拟地址由两部分组成:
- 页号:作为页表的索引,页表包含物理页所在物理内存的基地址
- 页内偏移:页基地址 + 页内偏移量 -> 物理地内存址
优点:
- 由于每个页的大小固定,因此存在内部碎片问题。但碎片很小
- 内存不足时,OS 换出最近未使用的页面,需要时再换入。每次交换仅几个页面,因此效率较高
缺点:
- 每个程序都有自己的虚拟地址空间,因此页表占用空间大
解决办法:多级页表。充分利用程序的局部性原理,一级页表需要覆盖所有虚拟地址,而二级页表按需创建。对于 64 位系统,需要四级目录。
优化:TLB 快表。利用局部性原理,把页表项缓存在 CPU 的一个专门芯片 TLB (Translation Lookaside Buffer 转址旁路缓存)中。
段页式内存管理
段页结合,虽然增加了硬件成本和系统开销,但提高了内存的利用率。
- 先将程序划分为多个有逻辑意义的段,也就是前面提到的分段机制;
- 接着再把每个段划分为多个页,也就是对分段划分出来的连续空间,再划分固定大小的页;
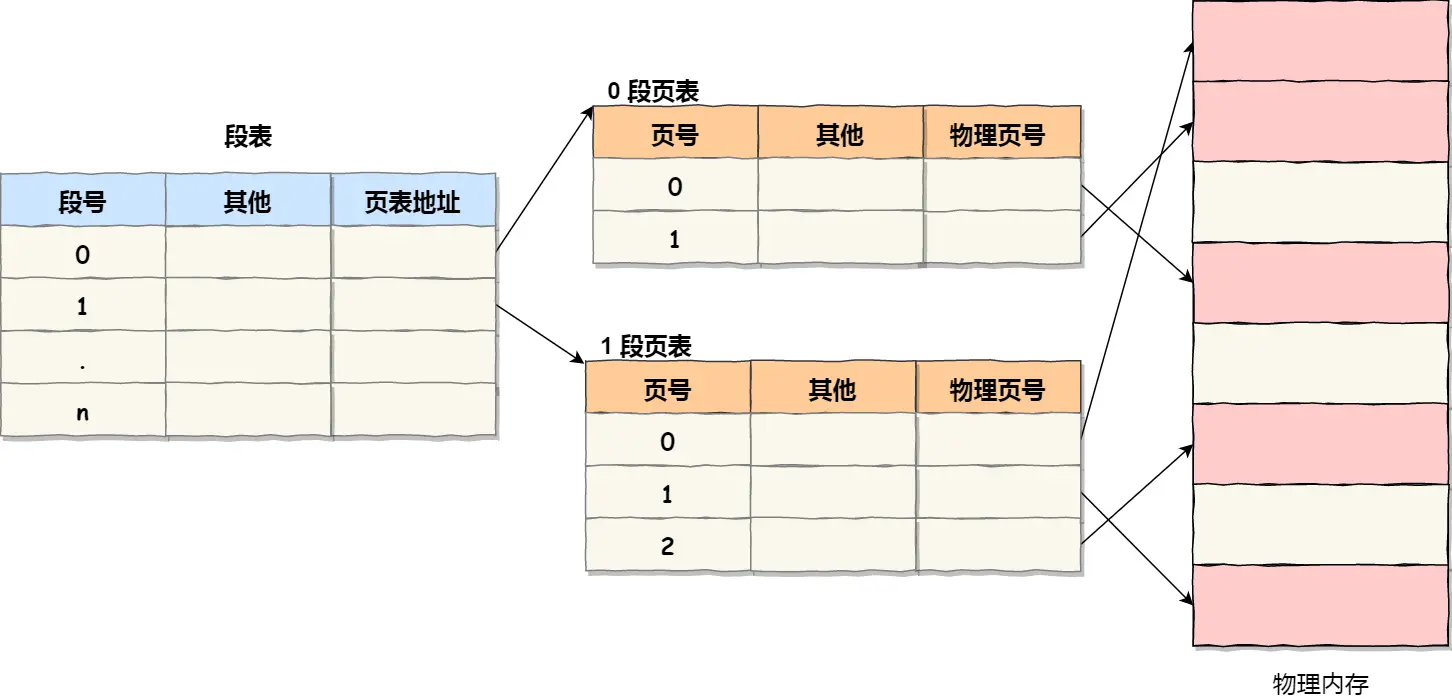
因此,访问内存地址时:
- 到段表中根据段号查询页表地址
- 到页表中查询物理页号
- 物理页基地址 + 页内偏移量 得到物理内存地址
虚拟内存优点
- 虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
Linux 内存管理
由于 Intel CPU 历史原因,Linux 不得不使用虚拟的段式内存,只用于访问控制和内存保护,主要还是页式内存管理。整个内存空间分为了内核空间和用户空间,每个进程的虚拟地址的内核部分都关联相同的物理内存,这样进程切换到内核态后就可以很方便地访问内核空间内存。
而用户空间内存分为:
- 代码段: 包括二进制可执行代码;
- 数据段: 包括已初始化的静态常量和全局变量;
- BSS 段: 包括未初始化的静态变量和全局变量;
- 堆段: 包括动态分配的内存,从低地址开始向上增长;
- 文件映射段: 包括动态库、共享内存等,从低地址开始向上增长
- 栈段: 包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。当然系统也提供了参数,以便我们自定义大小;
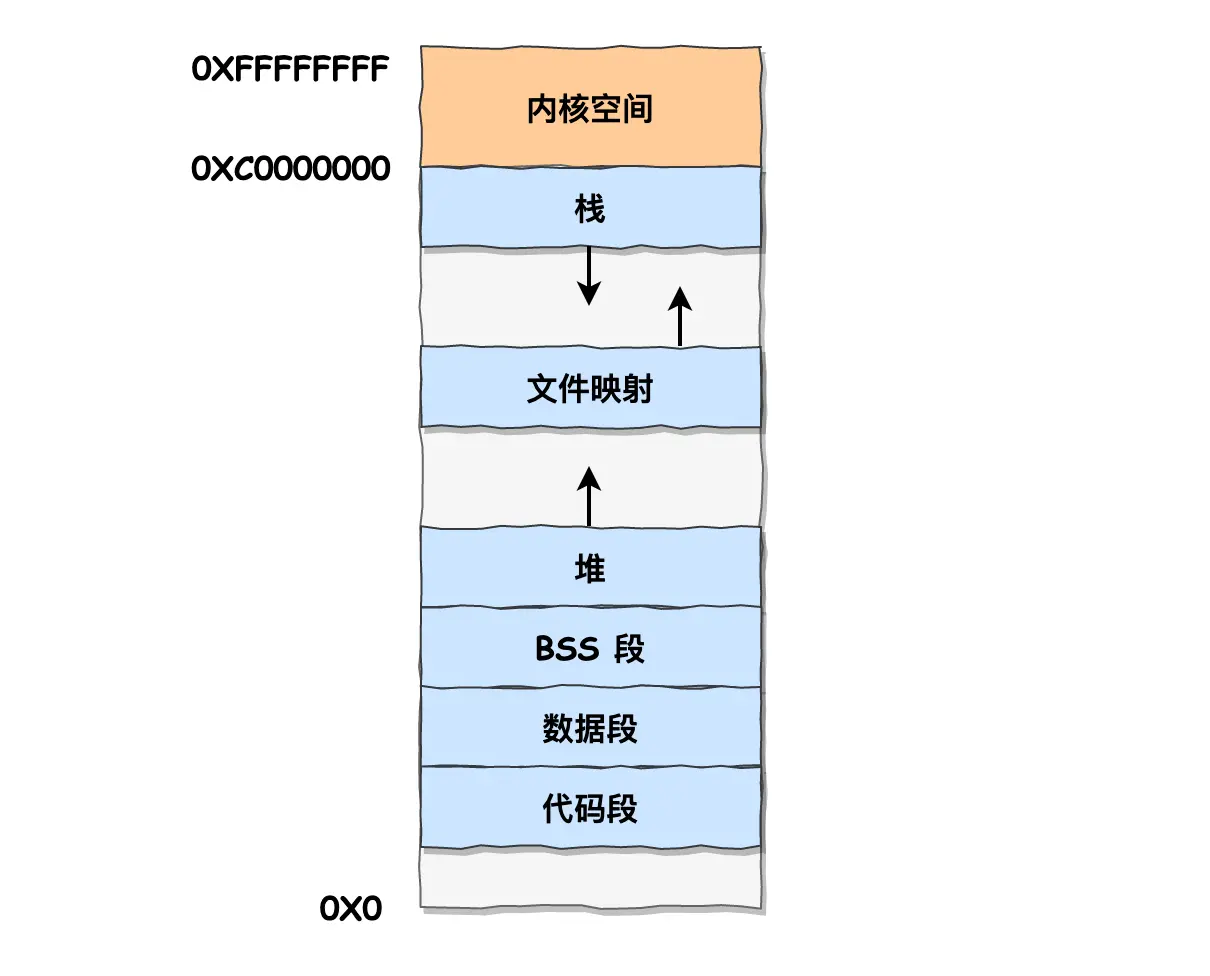
对于 32位 OS,内核空间占 1G,用户空间 3G,即理论上可以申请最大 3G 虚拟内存;
对于 64位系统,内核空间 128T,用户空间 128T,中间是未定义,即理论上可以申请最大 128G 虚拟内存。
内存分配
- malloc() 不是系统调用,而是 C 的库函数,用于动态分配内存。
- malloc() 分配的是虚拟内存,只有在初次访问时由 OS 触发缺页中断,建立实际的映射关系。(因此申请时可以超出物理内存限制)
- 分配空间时,malloc() 会预分配一定的空间作为内存池,例如 malloc(1) 会直接分配 132KB。
- 每次分配的内存块前有 16Byte 头信息,因此 free() 只需要知道起始地址就知道该释放多大的内存空间。
两种方式:
- 通过 brk() 系统调用从堆分配内存,堆顶指针上移。
- 用于小于 128KB 的内存申请。
- free() 时会先放进 malloc 内存池中以复用,等进程退出后再归还 OS
- 通过 mmap() 系统调用在文件映射区域分配内存。
- 用于大于 128KB 的内存申请。
- free() 后直接归还 OS
因此,mmap() 方式会频繁发生运行态的切换和缺页中断,而 brk() 通过内存池减少了系统调用和缺页中断。但是 brk() 不断分配小空间,回收后可能无法用于大内存的分配,进而产生内存碎片,导致内存泄漏。
内存泄露:程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
内存溢出:OOM,指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出。
内存回收
malloc() 分配虚拟内存后,程序初次访问时会触发缺页中断,进而中断处理程序会判断物理内存是否足够,不足时将进行内存回收。
回收流程:kswapd -> direct reclaim -> OOM Killer
- 后台内存回收 kswapd:在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,异步非阻塞
- 直接内存回收 direct reclaim:如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,同步阻塞
- OOM: 如果直接回收仍然无法满足程序的申请,内核将触发 OOM,由 OOM Killer 根据每个进程的内存占用情况和
oom_score_adj值进行打分,得分最高的进程会被杀掉,直到释放足够的内存(可通过/proc/[pid]/oom_score_adj调整被杀掉的概率)。
可回收内存
OS 通过页面置换算法得到以下两类可回收的内存:
- 文件页 File-backed Page:内核缓存的磁盘数据(Buffer)和内核缓存的文件数据(Cache)
- 可以直接释放,需要时重新从磁盘读取
- 脏页需要先写回
- 匿名页 Anonymous Page:像 堆、栈 这样的没有实际载体的数据
- 通过 Linux 的 Swap 机制,把不常用的内存写入磁盘,需要时重新载入
文件页、匿名页的回收都基于 LRU 算法,分别对应 active、inactive 两个双向链表(共四个链表),优先回收不常访问的内存。
性能优化
直接内存回收会阻塞线程,文件页、匿名页都需要磁盘 IO,因此频繁的内存回收会影响系统性能。优化措施:
- 减小
/proc/sys/vm/swappiness,使其倾向于回收文件页(干净页可以直接回收,好于 Swap 换入换出)。范围0-100 - 增大
/proc/sys/vm/min_free_kbytes,调整页阈值,及早触发后台回收,避免进入直接内存回收阻塞进程
- 内核定义了三个内存阈值:pages_min, pages_low, pages_high。后两者基于 pages_min 计算而得
- 内存处在 pages_min 和 pages_low 之间时会触发后台回收 kswapd
- 对于 NUMA 架构的 CPU,可以置
/proc/sys/vm/zone_reclaim_mode为 0,以支持访问远端 Node 内存
- SMP:也称 UMA(Uniform Memory Access),每个 CPU 地位平等,共享物理资源,因此访问内存时间都相同。但总线压力大,可用带宽小
- NUMA:非 UMA,对 CPU 分组,每组 Node 有独立的物理资源,通过总线访问其它 Node 内存,但耗时稍长(但收益高于内存回收)
Swap 机制
物理内存不够用时,需要将内存数据换出到磁盘,需要时再从磁盘换入内存,这个过程由 Swap 机制控制。一般回收像 堆、栈 这样的没有实际载体的匿名页数据
触发场景
- 内存不足:系统所需内存超过可用物理内存,内核会进行直接内存回收,保证正在执行进程的可用性。同步。
- 内存闲置:通过后台守护进程 kSwapd 将不再使用的内存回收。异步。
开启方法
- Swap 分区:硬盘上的独立区域,仅用于交换分区
- Swap 文件:文件系统中的特殊文件
缓存命中率
预读失效
Linux/MySQL 为读缓存提供了预读机制,通过一次磁盘顺序读将多个 Page (4KB)装入 Page Cache (16KB),减少磁盘IO,提高吞吐量。而如果预读的数据没有被访问,就是预读失效,占用了 LRU 链表前排的位置,大大降低了缓存命中率。
改进方法:让预读页停留在内存里的时间要尽可能短,因此可以划分冷数据和热数据。
- Linux:两个 LRU 链表,活跃 LRU 链表 active_list,非活跃 LRU 链表 inactive_list
- 预读页先加入 inactive_list 头部,待真正被访问时才插入 active_list 头部
- active_list 淘汰的页面降级到 inactive_list 头部
- MySQL:LRU 链表划分前半部分 young 区域和后半部分 old 区域
- 预读页先加入 old 区域头部,待真正被访问时才插入 young 区域头部
- young 区域淘汰的页面降级到 old 区域头部
缓存污染
批量读取数据时(例如 SQL 全表扫描),由于数据仅被访问一次,这些大量数据都会被加入到「活跃 LRU 链表」里,然后之前缓存在活跃 LRU 链表(或者 young 区域)里的热点数据全部都被淘汰了,如果这些大量的数据在很长一段时间都不会被访问的话,那么整个活跃 LRU 链表(或者 young 区域)就被污染了。
改进方法:提高进入活跃 LRU 链表(或者 young 区域)的门槛,避免热点数据不会被轻易替换掉。
- Linux:内存页第二次访问时才进行升级
- MySQL:内存页第二次被访问时,判断它停留在 old 区域的时间,超过 1s 就升级到 young 区域,否则停留在 old 区域
进程管理
进程
运行中的程序,就被称为「进程」(Process)。
- 运行状态(Running):该时刻进程占用 CPU
- 就绪状态(Ready):可运行,由于其他进程处于运行状态而暂时停止运行
- 阻塞状态(Blocked):该进程正在等待某一事件发生(如等待输入/输出操作的完成)而暂时停止运行,这时,即使给它CPU控制权,它也无法运行
- 创建状态(new):进程正在被创建时的状态
- 结束状态(Exit):进程正在从系统中消失时的状态
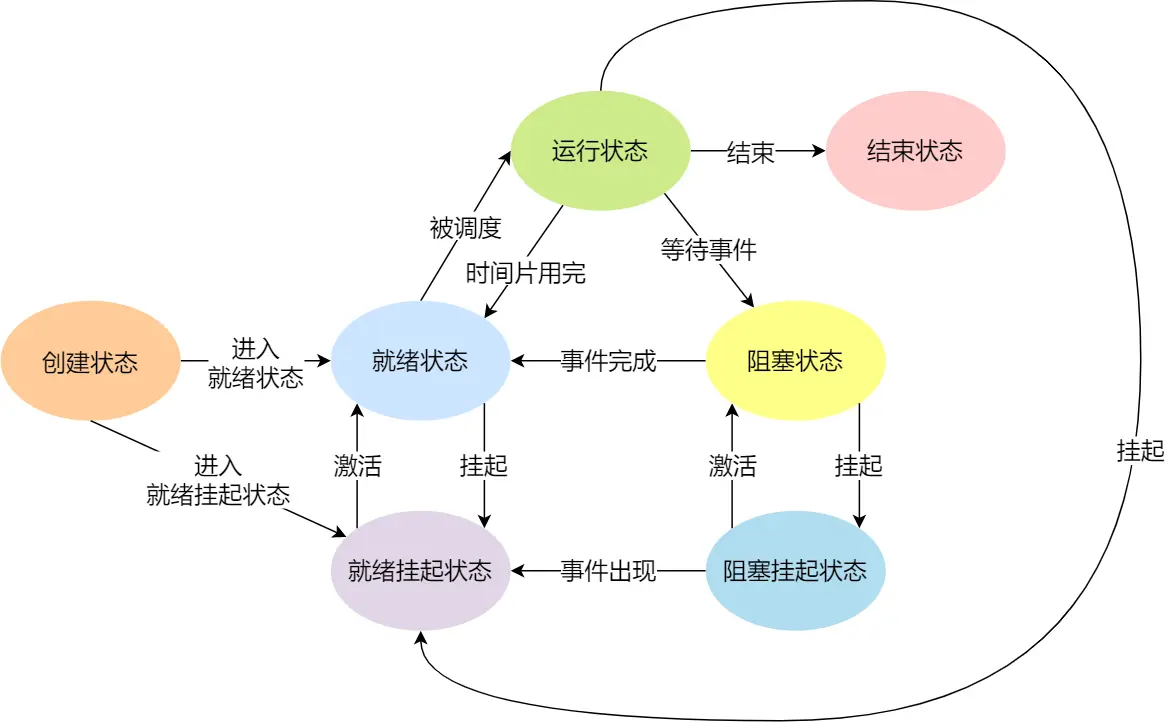
另外还有挂起状态,描述进程暂时被淘汰出内存的状态(sleep/换出等):
- 阻塞挂起状态:进程在外存(硬盘)并等待某个事件的出现;
- 就绪挂起状态:进程在外存(硬盘),但只要进入内存,立刻运行;
根据进程所处的不同状态,将进程对应的进程控制块 PCB 通过链表组织起来,例如就绪队列、阻塞队列等
线程
线程是进程当中的一条执行流程。同一个进程内多个线程之间可以共享代码段、数据段、打开的文件等资源,但每个线程各自都有一套独立的寄存器和栈,这样可以确保线程的控制流是相对独立的。
优点
- 一个进程中可以同时存在多个线程;
- 各个线程之间可以并发执行;
- 各个线程之间可以共享地址空间和文件等资源;
缺点
当进程中的一个线程崩溃时,会导致其所属进程的所有线程崩溃。(针对C/C++)
实现
- 用户线程:在用户空间实现的线程,不是由内核管理的线程,是由用户态的线程库来完成线程的管理
- 内核线程:在内核中实现的线程,是由内核管理的线程
- 轻量级进程:在内核中来支持用户线程
进程和线程对比
- 进程是资源分配的基本单位,而线程是处理器调度的基本单位。
- 进程拥有自己的地址空间,因此不会相互影响;而线程共享进程的地址空间,包括内存和资源。
- 线程是轻量级的进程,由于涉及资源少,而且相同的地址空间不需要切换页表,线程的创建、销毁以及切换所需的开销都比进程小。
线程和协程对比
协程是一种运行在线程之上的用户态模型,也称纤程,在线程的基础上通过时分复用的方式运行多个协程。
- 一个线程可以有多个协程,一个进程也可以单独拥有多个协程
- 线程进程都是同步机制,而协程则是异步
- 协程切换不需要内核态/用户态的转换,可以直接在用户态切换上下文
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
上下文切换
CPU 上下文切换:先把前一个任务的 CPU 上下文(CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
根据任务的不同,分三种:
进程上下文切换
- 在内核态完成,交换信息存储在 PCB 中
- 不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括内核堆栈、寄存器等内核空间的资源。
线程上下文切换
- 当两个线程不是属于同一个进程,则切换的过程就跟进程上下文切换一样;
- 当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的寄存器状态和栈数据
- 涉及资源少,开销比进程低得多
中断上下文切换
- 响应硬件中断时发生
- 比进程和线程上下文切换更快,因为通常涉及极少的的状态信息
进程间通信
每个进程的用户地址空间都是独立的,不能互相访问,但内核空间是所有进程共享的,因此进程之间要通信必须通过内核。
管道(Pipe)
- 特点:一种用于父子进程之间的单向通信方式,通过
pipe创建,仅存在于内存。 - 优点:简单、轻量级、适用于一对一通信。
- 缺点:单向通信,不适用于无亲缘关系的进程之间的通信。
命名管道(Named Pipe)
- 特点:一种允许无亲缘关系的进程之间进行双向通信的方式。通过
mkfifo创建。 - 优点:支持双向通信,适用于多个进程之间的通信。
- 缺点:需要显式创建和命名,效率低,不适合进程间频繁交换数据
消息队列(Message Queue)
消息队列解决了管道通信效率低的问题。
- 特点:允许不同进程之间进行异步通信,通过消息传递数据。
- 优点:支持多对多通信、异步通信,消息具有格式化结构。
- 缺点:需要额外的编程工作来管理消息队列,消息拷贝开销大,不适合大数据的传输
共享内存(Shared Memory)
共享内存解决了 MQ 的消息拷贝导致额外开销的问题,是速度最快的 IPC 方式,因为不需要在内核和用户空间之间复制数据。前提是处理好多进程并发访问的问题。
- 特点:允许多个进程访问同一块内存区域,实现高效的数据共享。
- 优点:高效、快速,适用于大量数据共享。
- 缺点:需要额外的同步机制来保证数据一致性,对内存管理要求较高。
信号量(Semaphore)
信号量机制防止了多进程竞争共享资源而造成数据错乱的问题。
- 特点:用于控制多个进程对共享资源访问的方式,本质上是一个整型的计数器,可用于同步和互斥。
- 原子 P 操作:用于进入共享资源前,信号量减 1,然后如果信号量 < 0,则表明资源已被占用,进程需阻塞等待;否则表明还有资源可使用,进程继续正常执行
- 原子 V 操作:用于离开共享资源后,信号量加 1,然后如果信号量 <= 0,则表明当前有阻塞中的进程,会将该进程唤醒运行;否则表明当前没有阻塞中的进程
- P、V必须成对出现。
- 如果信号量初始值为1,即互斥信号量,任何时刻仅有一个进程访问,很好的保护了共享内存。
- 如果信号量初始值为0,即同步信号量,保证进程执行的先后,例如生产者-消费者模型
- 优点:支持进程同步和互斥,可用于多种通信场景。
- 缺点:编程复杂性较高,容易引入死锁等问题。
套接字(Socket)
- 特点:基于网络协议的IPC方式,用于不同主机上的进程之间进行通信。
int socket(int domain, int type, int protocal)- domain: 协议族,如 UPv4 对应 AF_INET, IPv6 对应 AF_INET6, 本地通信 AF_LOCAL/AF_UNIX
- type:类型,如 TCP 对应 SOCKET_STREAM, UDP 对应 SOCKET_DGRAM, SOCK_RAW
- protocol:协议,基本废弃,填0
- 对于 TCP,需要 bind, listen, accept, write, read… 服务端监听和传送数据使用的是两个socket(门卫和员工)
- 对于 UDP,只要 bind, sendto, recvfrom
- 优点:支持跨网络通信,可用于分布式系统。
- 缺点:相对复杂,需要网络协议支持。
信号(Signal)
对于异常情况下的工作模式,需要用「信号」的方式来通知进程。例如 Ctrl+Z 产生 SigSTP 信号,Ctrl+C 产生 SigINT 信号
- 特点:用于通知进程发生事件(来自软件/硬件)的轻量级方式,通常用于处理异步事件。
- 优点:简单、快速,用于处理异步事件。
- 缺点:只能传递简单的信息,不适合大量数据交换。
线程间通信
临界区:访问共享资源的代码片段,产生来自多线程间的竞争条件导致程序运行的不确定性。
互斥:保证一个进程/线程在临界区执行时,其他进程/线程应该被阻止进入临界区
同步:并发进程/线程在一些关键点上可能需要互相等待与互通消息,这种相互制约的等待与互通信息称为进程/线程同步
通常使用 锁/信号量 实现进程/线程互斥,信号量功能更强大,还能实现同步。
- 互斥锁(Mutex):用于控制对共享资源的访问,保证多个线程访问共享资源时的互斥性。底层可以基于
测试并设置/等待队列 - 信号量(Semaphore):一种同步工具,用于保证多个线程之间的顺序性和互斥性。P操作减1,小于0阻塞;V加1,小于等于0唤醒线程。初始置 1 即互斥,置 0 即同步。
- 条件变量(Condition Variable):用于线程间的等待和唤醒,一个线程可以等待某个条件变量满足后被唤醒。
- 屏障(Barrier):用于多个线程之间的同步,当所有线程到达屏障时,才能继续执行后续操作。
- 自旋锁(Spinlock):一种忙等待的同步工具,它会不断地检测共享资源是否可用,直到资源可用后才能继续执行后续操作。
线程创建数量
受限于进程的虚拟内存空间上限和系统参数限制
- 每分配一个线程需要分配一定的虚拟内存,例如对于 32位 系统,用户空间3G,每个线程占 10M 虚拟内存,则能创建约 300 个线程
- /proc/sys/kernel/threads-max 表示系统支持的最大线程数,默认 14553
- /proc/sys/kernel/pid_max 表示系统全局的进程/线程 PID 号数值的限制,默认 32768
- /proc/sys/vm/max_map_count 表示限制一个进程可以拥有的VMA(虚拟内存区域)的数量,默认 65530
关闭进程
线程崩溃
一般来说,如果线程因为非法访问内存引起崩溃,那么进程也会崩溃。因为各个线程的地址空间是共享的,非法访问会导致内存的不确定性。
进程崩溃
进程结束是由于 OS内核 发起的系统调用,向进程发送信号,例如 SIGKILL,然后执行自定义/默认的信号处理函数(除SIGKILL),执行完毕后结束进程。
因此,对于 JVM 这种自己定义了信号处理函数的进程,可以发送 SIGTERM(kill 的默认信号)命令,执行一些资源清理后再 exit 优雅地退出。而像 StackOverFlowError、NPE 等非法访问内存,JVM 自定了 SIGSEGV 信号处理函数,内部通过栈回溯恢复线程执行并抛出异常。而其它的 SIGSEGV 信号 JVM 不做特殊处理,生成崩溃日志并退出。
死锁
死锁:多个线程互相持有对方所需要的资源,并且都在等待对方释放资源,导致这些线程都被阻塞,无法继续执行,进而陷入了一种僵局的状态。Java 程序可以使用 jstack 工具检查死锁。
死锁条件
- 互斥:多个线程不能同时使用同一个资源。
- 请求与保持:线程持有资源后不会主动释放已经持有的资源
- 不可抢占:线程已经持有的资源不会被其它线程剥夺
- 循环等待:两个线程获取资源的顺序构成了环形链
预防死锁
- 破环互斥:资源非独占,即多个进程可以同时访问一个资源
- 破环请求与保持:可以一次性请求所有所需的资源,或运行过程中逐步释放掉已使用完毕的资源
- 破坏不可抢占:已持有资源的进程在提出新的资源请求没有得到满足时,它必须释放已经保持的所有资源
- 破坏循环等待条件:通过对资源进行排序,按编号顺序申请,保证资源申请不形成环路(最常用,将稀缺资源设置较大的编号,按从小到大的序号申请)
避免死锁
银行家算法:在分配资源时判断是否会出现死锁,只在不会出现死锁的情况下才分配资源。但是进程必须事先声明每个进程请求得最大资源数。
- Available:可利用资源向量
- Max:最大需求矩阵
- Allocation: 已分配矩阵
- Need:需求矩阵
经典同步问题
哲学家进餐问题
- 拿筷子前加上互斥信号量
- 偶数编号哲学家先拿左边筷子,后拿右边筷子;奇书编号哲学家先拿右边筷子,后拿左边筷子
- state 数组记录每位哲学家的 进餐/思考/饥饿 状态
读者/写者问题
- 读者有限:wMutex 写互斥,rCount 读个数,rCountMutex 对rCount的互斥
- 写者优先:rMutex 读互斥,wDataMutex 写互斥,wCount 写数量,wCountMutext 对wCount的互斥
- 公平策略:读写互斥、优先级相同、一个写者访问临界区、多个读者同时访问临界区
锁机制
为了避免资源竞争而导致数据错乱,共享资源访问前需要加锁,
- 互斥锁:
- 加锁失败后,线程会释放 CPU,并被内核置为睡眠状态
- 等到锁被释放后,内核在合适的时机唤醒线程
- 加锁失败/唤醒线程会进行用户态和内核态的上下文切换,存在性能开销。因此如果被锁住的代码执行时间很短应选择自旋锁
- 自旋锁:
- 加锁失败后,线程会忙等待,直到它拿到锁
- 底层基于 CAS,在用户态完成加锁和解锁,开销较小。忙等通过 while循环/PAUSE指令 来实现,推荐PAUSE,加锁失败时cpu睡眠 30 clock 降低了读频率
- 对于单核CPU,需要配合抢占式的调度器,否则自旋的线程永远不会放弃 CPU
加锁失败时,互斥锁进行线程切换,自旋锁则忙等
- 读写锁:
- 读取共享资源用读锁,修改共享资源用写锁。可以基于互斥锁/自旋锁
- 根据实现还分为读优先锁和写优先锁,但存在饥饿问题,以及公平读写锁
- 适用于能明确区分 read/write,且读多写少的场景
以上三种锁都是悲观锁,即认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁。
而乐观锁,也叫无锁编程,假定冲突的概率很低,先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有那么操作完成,否则放弃本次操作,并进行重试来解决冲突。乐观锁适用于冲突概率很低,且加锁成本非常高的场景。
调度算法
进程调度
也即线程调度。根据如何处理时钟中断 ,把调度算法分抢占式和非抢占式。
调度原则
- CPU 利用率:调度程序应确保 CPU 是始终匆忙的状态,这可提高 CPU 的利用率;
- 系统吞吐量:吞吐量表示的是单位时间内 CPU 完成进程的数量,长作业的进程会占用较长的 CPU 资源,因此会降低吞吐量,相反,短作业的进程会提升系统吞吐量;
- 周转时间:周转时间是进程运行+阻塞时间+等待时间的总和,一个进程的周转时间越小越好;
- 等待时间:这个等待时间不是阻塞状态的时间,而是进程处于就绪队列的时间,等待的时间越长,用户越不满意;
- 响应时间:用户提交请求到系统第一次产生响应所花费的时间,在交互式系统中,响应时间是衡量调度算法好坏的主要标准。
调度算法
- 先来先服务 FCFS:非抢占式,先来的进程一直运行到退出或阻塞。不利于短作业,适用于 CPU 繁忙型作业,不适合 I/O 繁忙型作业的系统
- 最短作业优先 SJF:优先选择运行时间最短的进程。不利于长作业,甚至饥饿
- 高响应比优先 HRRN:响应比 = (等待时间 + 要求服务时间) / 要求服务时间。权衡了短作业和长作业,但要求服务时间是不可预知的,因此只是理想算法
- 时间片轮转 RR:Round-Robin,关键在于时间片的设定,过短导致怕频繁的上下文切换,过长会引起短作业进程的响应时间变长
- 最高优先级 HPF:分抢占式和非抢占式,还分静态优先级和动态优先级(运行时间增加降低优先级,等待时间增加提高优先级)。可能导致低优先级饥饿
- 多级反馈队列 MFQ:
- 多级:多个优先级队列,优先级越高时间片越短
- 反馈:如果有新进程加入优先级高的队列,立刻停止当前运行进程,转而去运行优先级高的队列;
- 新进程放入第一级队列,时间片用完放入下一级队列,被强占则放入原队列末尾
- 兼顾了长短作业,同时有较好的响应时间
页面调度
缺页中断和一般中断的区别:
- 缺页中断在指令执行「期间」产生和处理中断信号,而一般中断在一条指令执行「完成」后检查和处理中断信号。
- 缺页中断返回到该指令的开始重新执行「该指令」,而一般中断返回到该指令的「下一个指令」执行。
当出现缺页异常,需调入新页面而内存已满时,选择被置换的物理页面:
- 最佳页面置换:理想算法,置换未来最长时间不访问的页面
- 先进先出置换:换出驻留时间最长的页面
- 最近最久未使用 LRU:换出最长时间未被访问的页面。实现开销会比较大
- 时钟页面置换:所有页面保存在一个环形链表中,维护指向最老的页面。发生缺页时,顺时针找到一个访问位为 0 的页面置换
- 最不常用置换 LFU:换出访问次数最少的页面。但没有考虑时间问题,可以定期减少已访问次数。
磁盘调度
- 先来先服:简单粗暴,磁道分散,性能低
- 最短寻道时间优先:优先选择从当前磁头位置所需寻道时间最短的请求,存在饥饿
- Scan:磁头在一个方向上移动,访问所有未完成的请求,直到磁头到达该方向上的最后的磁道,才调换方向。中间磁道访问频率高
- CScan:磁头朝一个方向移动时处理请求,返回时直接复位不处理请求。对各个位置磁道响应频率比较平均
- LOOK:类似 Scan,但磁头在移动到最远的请求位置时就立即反向移动。
- C-LOOK:类似 CScan,也是最远请求时就返回,且返回途中不处理请求
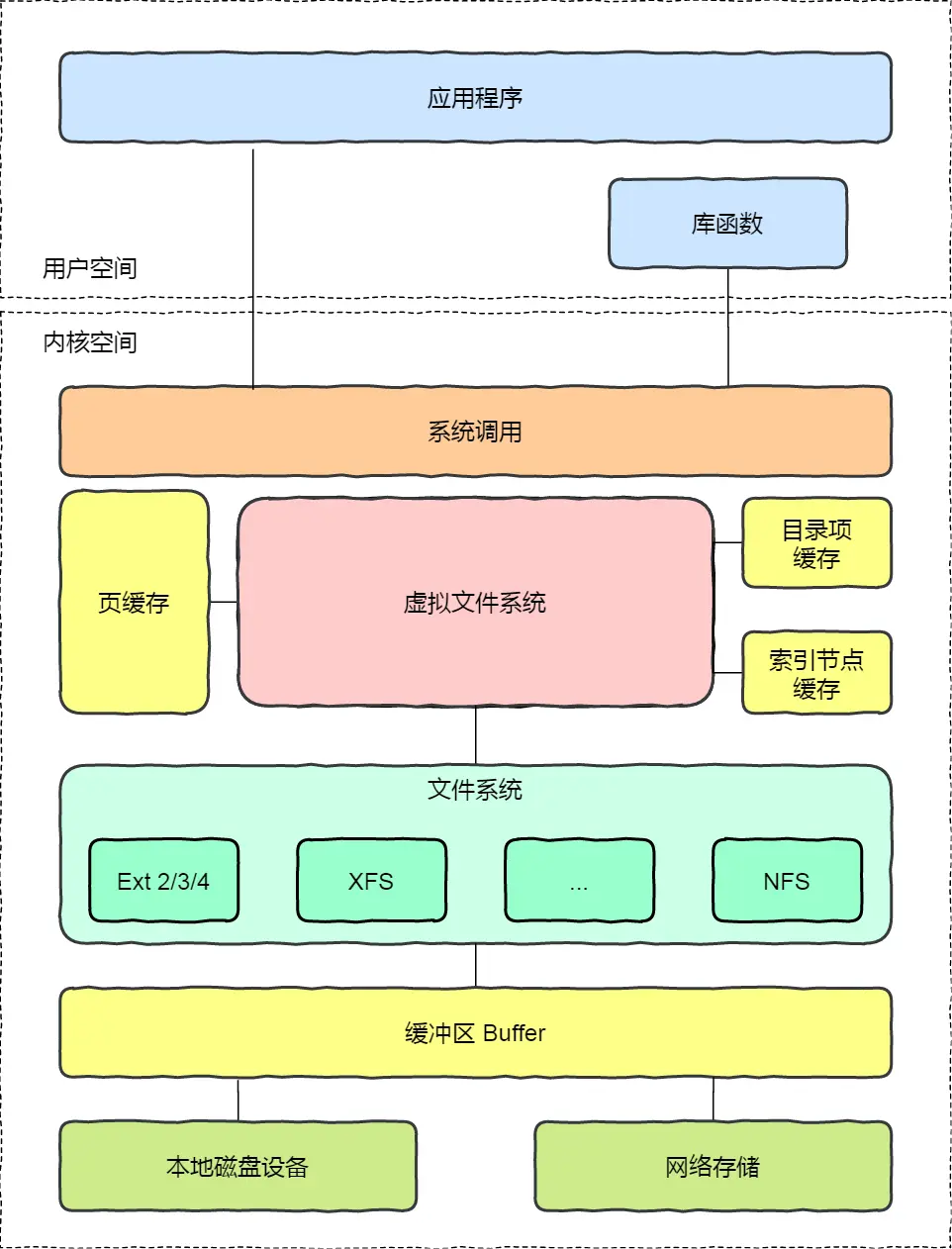
文件系统
Linux 一切皆文件,包括普通文件、目录、块设备、管道、Socket 等等
基本组成
Linux 为每个文件分配两个数据结构:
- inode:索引节点,文件的唯一标识,记录文件元信息,例如 inode 编号、文件大小、访问权限、创建/修改时间、磁盘位置等
- dentry:目录项,多个目录项关联起来形成目录结构。记录文件的名字、inode 指针、其他目录项层级关联等。本质是内核在内存中维护的数据结构,不存放于磁盘。
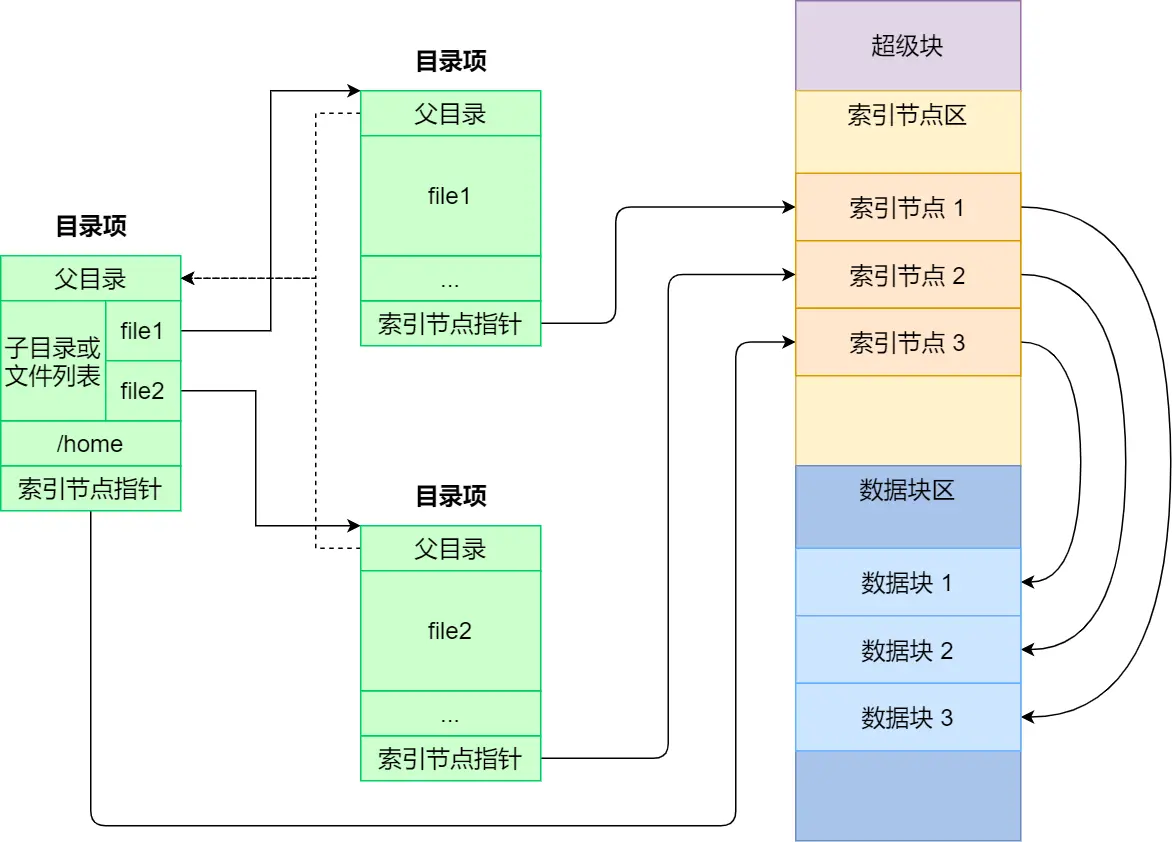
磁盘格式化时会被分成三个存储区域:
- 超级块:用来存储文件系统的元信息,比如块个数、块大小、空闲块等等。挂载文件系统时进入内存
- 索引节点区:用来存储索引节点。当文件被访问时进入内存
- 数据块区:用来存储文件或目录数据。当文件被访问时进入内存
目录
目录项记录着文件名,和索引节点是多对一的关系,即文件可以有别名,例如硬链接的实现。而目录也是磁盘上的文件,记录子目录和文件。目录项既可以表示文件,也可以表示目录项。
存储
磁盘读写的最小单位是扇区,默认 512B,而文件系统把多个扇区构成一个逻辑块,默认 4KB,以逻辑块为单位读写磁盘。
虚拟文件系统
VFS 位于用户层和文件系统中间,为用户提供一个统一的接口。根据存储位置的不同,分为磁盘文件系统(Ext2/3/4)、内存文件系统(/proc, /sys)、网络文件系统(NFS, SMB)
硬/软链接
- 硬链接:多个目录项中的索引节点指向一个文件
- 不可用于跨文件系统,每个文件系统有各自的 inode 结构和列表
- 只有删除文件的所有硬链接以及源文件时,系统才会删除该文件
- 软链接:重新创建一个有独立 inode 的文件,其内容是另一个文件的路径
- 可以跨文件系统
- 即使目标文件删除了,软链接仍在,只不过找不到目标文件
文件使用
open -> write/read -> close
- 打开文件后,OS 为每个进程维护一个打开文件表,每一项代表一个文件描述符 FD,包括:
- 文件指针:跟踪读写位置
- 打开计数器:打开该文件的进程数,计数器为0时才关闭文件,删除该条目
- 文件磁盘位置
- 访问权限
文件存储
连续存放
- 文件存放在磁盘连续的物理空间中
- 文件数据紧密相连,读写效率高(一次磁盘寻道就可以读出整个文件)
- 但会产生磁盘碎片、文件长度不易扩展的问题
非连续存放
- 链表方式:
- 数据离散不连续,分隐式链表(指针相连)、显式链接(链接表存储块地址)
- 可以消除磁盘碎片,文件长度也可以动态扩展
- 但隐式链表无法直接访问数据块,只能通过指针顺序访问,而且指针还消耗额外存储空间
- 而显式链接通过文件分配表,提高了检索速度,减少磁盘访问次数,但不适用于大磁盘
- 索引方式
- 为每个文件创建一个索引数据块,存放指向文件数据块的指针列表。文件头中保存索引数据块的指针
- 文件的创建、增大、缩小都很方便,没有碎片问题,支持顺序读写和随机读写
- 但存储索引占用额外空间。对于大文件,需要链式索引块/多级索引块
Unix 系统对于不同大小的文件,采取链表、一级索引、二级索引、三级索引等方式。
空闲空间管理
空闲表
- 维护一张表,包括空闲区的第一个块号和空闲块个数
- 适用于少量空闲区场景,否则表项太多查询效率低
空闲链表
- 空闲块构成链表
- 简单,但不能随机访问,IO 多效率低,指针消耗了块的存储空间
位图法
- Linux 文件系统采用了位图法,用二进制的一位来表示磁盘中一个块的使用情况
- inode 空闲块也是位图法管理
文件 IO
缓冲/非缓冲 IO
根据是否利用标准库缓冲,分:
- 缓冲 IO:利用标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件
- 非缓冲 IO:直接通过系统调用访问文件,不经过标准库缓存
直接/非直接 IO
根据是否利用操作系统的缓存,分:
- 直接 IO:不会发生内核缓存和用户程序之间数据复制,而是直接经过文件系统访问磁盘
- 非直接 IO:读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘
触发写回的场景有:
- 在调用 write 的最后,当发现内核缓存的数据太多的时候,内核会把数据写到磁盘上;
- 用户主动调用 sync,内核缓存会刷到磁盘上;
- 当内存十分紧张,无法再分配页面时,也会把内核缓存的数据刷到磁盘上;
- 内核缓存的数据的缓存时间超过某个时间时,也会把数据刷到磁盘上;
阻塞/非阻塞 和 同步/异步 IO、
- 阻塞 IO:程序执行 read 时线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,拷贝过程完成 read 才会返回
- 非阻塞 IO:read 请求在数据未准备好的情况下立即返回,程序可以继续往下执行。但应用程序会不断轮询内核,直到内核将数据准备好并将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果(针对轮询的优化:IO 多路复用 select/poll/epoll)
无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用都是同步调用,因为它们在 read 调用时,内核将数据从内核空间拷贝到应用程序空间的过程都是需要等待的,也就是说这个过程是同步的。
而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待,例如 aio_read()
Page Cache
Page Cache 本质上是由 Linux 内核管理的内存区域,通过 mmap/buffered IO 将文件读取到内存空间实际上都是读取到 Page Cache 中。
- 由多个 Page(4KB) 构成,但不是所有 Page 都构成 Page Cache,例如匿名页
- Page Cache 用于缓存文件的页数据,buffer cache 用于缓存块设备(如磁盘)的块数据。
- 可以加快数据访问,同时基于预读,可以减少IO,提高磁盘吞吐量
- 但需要占用额外物理内存空间,物理内存紧张时可能导致频繁的 swap
数据一致性问题
两方面:数据一致 + 元数据一致
- fsync(fd):将文件的脏数据和脏元数据全部刷新至磁盘
- fdatasync(fd):将文件脏数据刷新至磁盘,同时只刷新必要的元数据,如文件大小
- sync():刷新回脏的文件元数据
对比 Direct IO
- Page Cache 在内核空间开辟缓冲区
- mmap:用户空间做内存映射,指向 Page Cache
- Direct IO:去掉 Page Cache,交由 DMA,直接在用户空间开辟缓冲区
设备管理
IO 设备分两大类:
- 块设备:数据存储在固定大小的块中,每个块有自己的地址。如硬盘、USB等
- 字符设备:以字符为单位收发数据,不可寻址。例如鼠标、键盘等
设备控制器
每个设备都有一个设备控制器,来屏蔽设备之间的差异。它包括:
- 芯片:执行逻辑
- 寄存器:
- 状态寄存器:告诉 CPU 工作是否已经完成
- 命令寄存器:保存要执行的命令
- 数据寄存器:保存需要传输的数据
块数据通常传输的数据量大,因此设备控制器设立了可读写的数据缓冲区。
设备控制器和 CPU 的通信方式包括:
- 端口 IO:每个控制寄存器分配一个 I/O 端口,通过特殊汇编指令操作
- 内存映射 IO:将所有控制寄存器映射到内存空间中,这样就可以像读写内存一样读写数据缓冲区
IO 控制方式
- 轮询:傻瓜式,占用CPU
- 中断:软中断/硬中断,CPU 经常被打断占用
- DMA:直接内存访问,由硬件完成数据读写内存,CPU 仅在传输开始和结束时干预
设备驱动程序
设备控制器属于硬件,而设备驱动程序属于 OS。提供 OS -> 设备驱动程序 -> 设备控制器的中间层接口,初始化时需要注册中断处理函数。
IO 完成 -> 控制器发起中断 -> 保护被中断进程的 CPU 上下文 -> 执行中断处理函数 -> 恢复中断进程上下文
通用块层
针对块设备,Linux 通过通用块层管理不同的块设备,提供文件系统和驱动程序之间的抽象接口:
- 向上为文件系统/应用程序提供访问块设备的标准接口
- 向下把各种磁盘设备抽象为统一的块设备
- 并且进行 IO请求 的调度,以提高读写效率
调度算法
- 无调度:不做任何处理。通常用于虚拟机,将 IO 交由物理机负责
- 先入先出
- 完全公平:每个进程维护一个 IO 调度队列,按时间片均匀分布每个进程的 IO请求
- 优先级调度:适合大量进程的系统,如桌面环境、多媒体应用等
- 最终期限调度:分读、写IO队列,并确保达到最终期限的请求被优先处理。适用于 IO压力大的场景。如 DB
Linux IO 分层
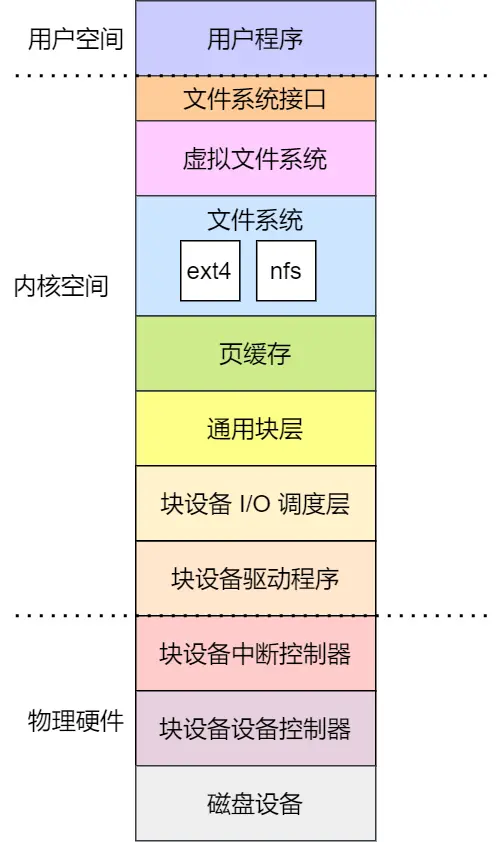
- 文件系统:虚拟文件/其它文件系统的具体实现,向上提供统一的文件访问接口,向下通过通用块层访问设备
- 通用块层:包括块设备的 I/O 队列和 I/O 调度器,选择 IO请求 发给设备层
- 设备层:包括硬件设备、设备控制器和驱动程序,负责最终物理设备的 I/O 操作
Linux 提供了页缓存、索引节点缓存、目录项缓存、缓冲区等来提高 IO效率。
网络系统
零拷贝
DMA:Direct Memory Access 直接内存访问,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,CPU 不再参与任何与数据搬运相关的事情,从而处理别的事务。如今每个 I/O 设备里都有自己的 DMA 控制器。
以文件传输的场景为例,数据从磁盘 -> 内核缓冲区(磁盘高速缓存 PageCache)-> 用户空间 -> Socket 缓冲区 -> 网卡。
整个过程需要产生4次内核态和用户态的上下文切换(read/write 2次系统调用),以及4次数据拷贝(CPU 和 DMA 各负责2次),效率很低。可以通过零拷贝技术减少这两个开销,实现方式有两种:
- mmap + write:
mmap()系统调用直接把内核缓冲区里的数据映射到用户空间,减少了一次数据拷贝 - sendfile:用一次
sendfile()系统调用替代read() + write(),并且直接把内核缓冲区数据拷贝到 socket 缓冲区里,减少了2次上下文切换和1次数据拷贝 - Zero-Copy: 如果网卡支持 SG-DMA 技术,网卡可以直接从内核缓冲中拷贝数据,全程不需要 CPU 拷贝,减少了2次上下文切换和2次数据拷贝
也因此,零拷贝技术不允许对数据内容做进一步的加工。
PageCache
PageCache 的优化包括
- 缓存最近被访问的数据
- 预读功能
但对于大文件,PageCache 会被大文件占满,优化失效带来性能问题。因此高并发场景下,针对大文件的传输,尽量使用异步IO,绕开 PageCache(也称直接 IO,而使用 PageCache 的叫做 缓存IO)。另外,如果应用程序已经实现了磁盘缓存,可以使用 直接IO,减少额外性能损耗。
I/O 多路复用
基本 Socket 模型
通过 Socket 建立 TCP 连接时,监听和传输数据的是两个 Socket,OS 内核为每个 Socket 维护了两个队列:
- TCP 半连接队列:保存还没有完成三次握手的连接,此时服务端处于 syn_rcvd 的状态;
- TCP 全连接队列:保存完成了三次握手的连接,此时服务端处于 established 状态;
这种模式基于同步阻塞,只能一对一通信
多进程模型
服务器的主进程负责监听客户的连接,一旦与客户端连接完成,通过 fork 创建子进程服务客户。但是,子进程退出后可能保留一些信息成为僵尸进程消耗资源,需要主进程通过 wait/waitpid 回收资源。
由于进程上下文切换开销(虚拟内存、栈、全局变量等用户空间资源,以及内核堆栈、寄存器等内核空间资源)很大,因此这种模式并发量不能很高。
多线程模型
当服务器与客户端 TCP 完成连接后,通过 pthread_create() 函数创建线程,然后将「已连接 Socket」的文件描述符传递给线程函数,接着在线程里和客户端进行通信,从而达到并发处理的目的。但是频繁创建和销毁线程,系统开销也是不小的,可以通过线程池进行优化,但是注意需要对存放 Socket 的队列同步加锁。
无论基于进程还是线程,对于一台机器想要达到 C10K 的并发量还是很困难的。
I/O 多路复用
一个进程处理每个请求如果仅需 1ms,那么多个请求复用一个进程就可以实现高并发,也叫时分多路复用。select/poll/epoll是内核提供给用户态的多路复用系统调用,进程可以通过这些系统调用函数从内核中获取多个事件。
- select
- 将已连接的 Socket 放到一个文件描述符集合,然后调用 select 将文件描述符集合拷贝到内核里,由内核遍历判断是否有事件,标记可读/可写
- 接着再把整个描述符集合拷贝回用户态,用户态再遍历一次找到可读/可写的 Socket,取出进行处理
- 需要 2 次遍历文件描述符集合,用固定长度的 BitsMap 表示描述符集合,个数受限
- poll
- 以链表形式组织一个动态数组表示文件描述符集合,和 select 一样也要在内核态和用户态各遍历 1 次
- epoll
- 先用 epoll_create 创建一个 epoll 文件描述符 epfd,通过 epoll_ctl 将需要监视的 socket 添加到 epfd 中,最后调用 epoll_wait 等待数据
- 内核中使用红黑树来跟踪进程所有待检测的文件描述符,CRUD 效率很高
- 使用事件驱动的机制,内核中维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数,内核会将其加入到这个就绪事件列表中。用户调用 epoll_wait 得到有事件发生的描述符个数。只将有事件发生的 Socket 集合传递给应用程序,因此只在 epoll_wait 期间发生了一次内存拷贝,大大提高了效率
两种事件触发模式:
- 边缘触发:
- 当被监控的 Socket 描述符上有可读事件发生时,服务器端只会从 epoll_wait 中苏醒一次
- 因此程序要保证一次性将内核缓冲区的数据读取完;
- 一般和非阻塞 I/O 搭配使用,效率要高于水平触发
- 水平触发:
- 当被监控的 Socket 上有可读事件发生时,服务器端不断地从 epoll_wait 中苏醒,直到内核缓冲区数据被 read 函数读完才结束
- select/poll 仅有水平触发,epoll 默认是水平触发
网络模式
Reactor 模式
一种非阻塞同步网络模式,对事件反应,来了一个事件,Reactor 就有相对应的反应/响应。核心部分有两个:
- Reactor:负责监听和分发事件,事件类型包含连接事件、读写事件;
- 处理资源池:负责处理事件,如 read -> 业务逻辑 -> send;
单 Reactor 单进程/线程
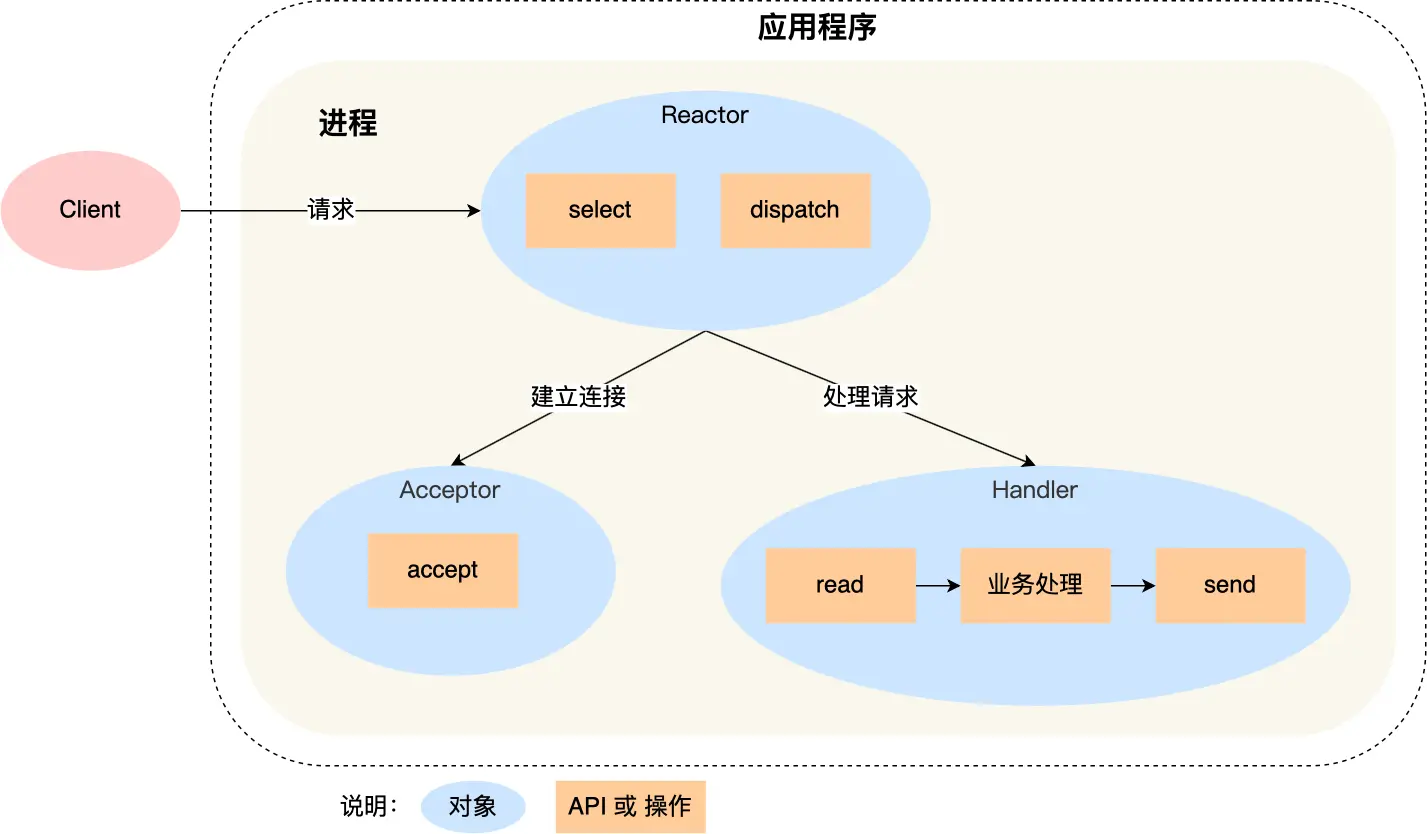
Reactor 对象通过 select(IO 多路复用接口)监听事件,将事件通过 dispatch 分发给 Acceptor / Handler。Acceptor 负责建立连接,并创建一个 Handler 对象来处理后续的响应事件。
缺点:
- 无法充分利用多核 CPU 性能
- Handler 处理业务时无法处理其它事件
实现简单,但仅适用于业务处理非常快速的场景,不适用计算机密集型的场景。例如 Redis 6.0 之前的版本就是 单 Reactor 单进程。
**单 Reactor 多进程/线程
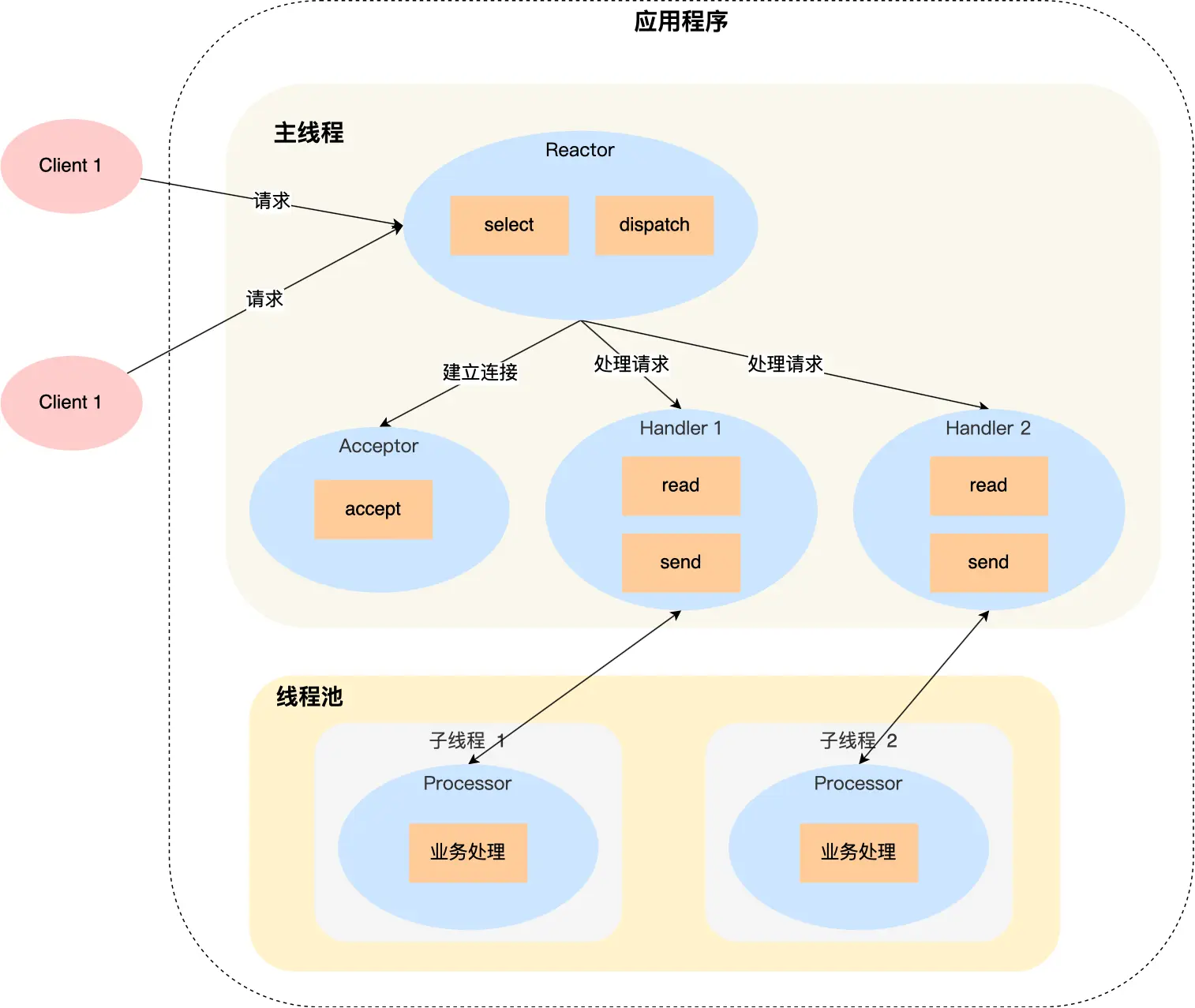
Handler 对象不再直接负责业务处理,只负责数据接收和发送,read 读取到数据后交给子线程里的 Processor 进行业务处理,处理完后再发回 Handler。
缺点:只有一个 Reactor 承担所有事件的舰艇和响应,且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
多 Reactor 多进程/线程
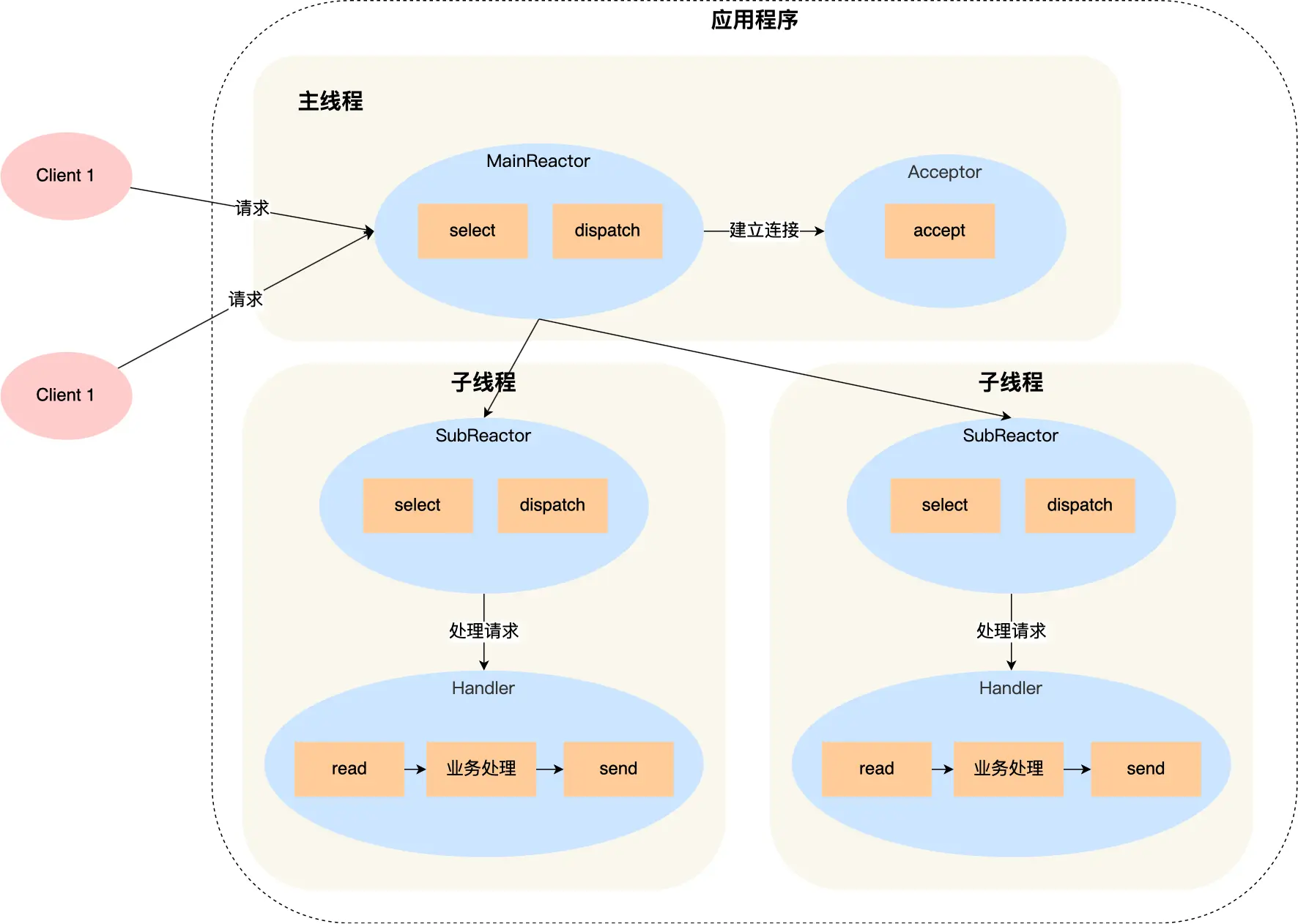
MainReactor 收到事件后将新连接分配给 SubReactor 继续监听,再次发生事件时由 SubReactor 调用相应的 Handler 响应。
主线程只负责接收新连接,子线程负责完成后续的业务处理,且无须返回数据。
例如著名的 Netty、Memcache 都是多 Reactor 多线程,Nginx 是多 Reactor 多进程。
Proactor
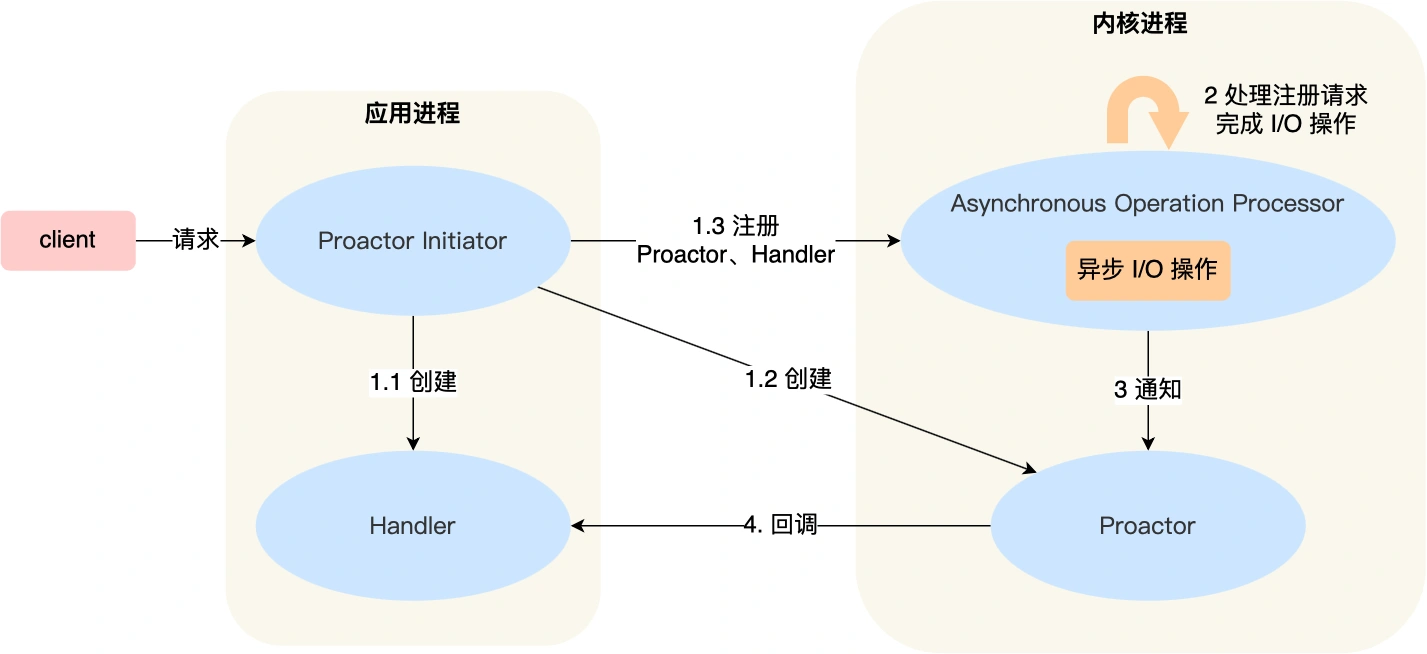
Proactor 是异步网络模式,不用等待 数据准备 和 数据拷贝 两个过程,完全由内核完成并通知。
Reacto 和 Proactor 都是一种基于事件分发的网络编程模式,区别在于 Reactor 感知的是就绪可读写(待完成)事件,Proactor 感知的是已完成的读写事件。
然而,Linux 下的 AIO 系列函数都是用户空间模拟的异步,且仅支持本地文件 AIO,不支持网络 Socket,因此基于 Linux 的高性能网络程序都是 Reactor 方案。
一致性哈希
不同的负载均衡算法适用的业务场景也不同的,例如轮询策略只适用于每个节点数据一致的场景,但是不适合分布式系统,可能访问不到需要的数据。
哈希算法可以建立数据和节点的映射关系,但节点变化时,所有数据需要进行迁移,开销过大。
一致性哈希
将「存储节点」和「数据」都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
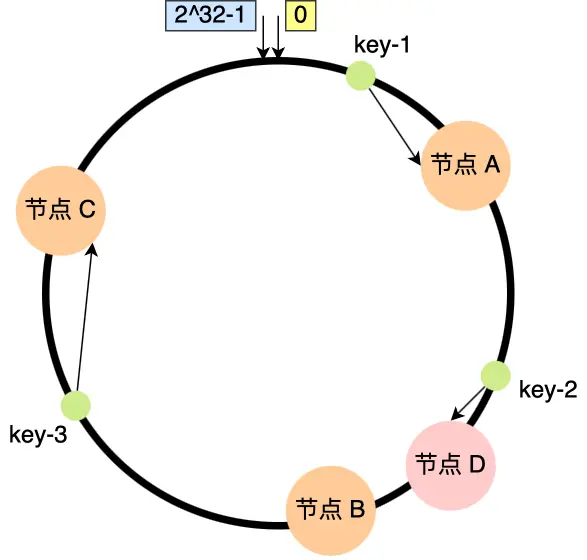
虚拟节点
一致性哈希算法不能保证分布均匀,可能大量请求集中在一个节点。
因此可以引入虚拟节点,对一个真实节点做多个副本,并将虚拟节点也映射到哈希环上。以此提高节点的均衡度和稳定性。带虚拟节点的一致性哈希适合硬件配置不同的节点的场景,以及节点规模会发生变化的场景。
网络性能
指标
- 带宽:链路的最大传输速率
- 延时:请求数据包发送后,收到对端响应,所需要的时间延迟
- 吞吐量:单位时间内成功传输的数据量
- PPS:Packet Per Second 发包速率
- 网络可用性、并发连接数、丢包率、重传率
查看网络信息
- ifconfig/ip 查看网络配合和收发数据包的统计信息
- ss/netstat 查看 socket、网络协议栈、网口、路由表信息
- sar 查看当前网络的吞吐率和 PPS
Java
集合
ArrayList
- ArrayList底层是可以动态扩展的 Object 数组,默认初始容量是10。
- 当添加元素超过当前的 capacity 时,就会触发扩容机制,扩容机制主要由内部的 grow() 方法实现。
- 首先会根据默认容量和存储所需容量的较大者确定一个最小扩容容量
minCapacity - 然后将现在的容量扩大1.5倍左右,确定一个新容量
- 接着开辟一个新数组,容量为上面两个容量的较大者,将所有元素复制到新数组中完成扩容
- 首先会根据默认容量和存储所需容量的较大者确定一个最小扩容容量
- 最后把新添加元素放到扩容后的数组末尾
HashMap
- JDK 1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表是为了用拉链法解决哈希冲突。
- JDK 1.8 之后 HashMap 在解决哈希冲突时,如果链表长度大于8,并且数组长度超过64,就会把链表转化为红黑树,以减少搜索时间。
- 如果 HashMap 存储元素超过一个阈值,阈值等于当前容量 * 0.75(负载因子),就会将数组扩容至当前的2倍,然后进行rehash,把数据放到新的位置。
默认大小是 16,负载因子 0.75 是统计学上 Hash 后遵循泊松分布的结果。扩容 $2^n$是为了在确定索引时index = hashcode % capacity可以利用位运算。
HashTable/TreeMap
HashTable 也实现了 Map 接口,基于锁机制实现了线程安全,因此效率低,多线程环境下推荐使用 ConcurrentHashMap。
TreeMap 是基于红黑树实现的有序键值对集合。
Set
- HashSet 底层基于 HashMap,使用哈希表存储元素,具有快速的查找性能,但不保证元素的顺序。
- LinkedHashSet 底层使用哈希表存储元素,并通过链表维护元素的插入顺序。
- TreeSet 底层实现是基于红黑树(TreeMap),支持元素自动排序
ConcurrentHashMap
JDK 7 以前的ConcurrentHashMap使用分段锁,每个segment上同时只有一个线程操作。JDK 8后理想情况下,每个table元素都可以并发:
- 结构上是数组+链表/红黑树,当冲突链表达到一定长度时,链表会转换成红黑树。
- ConcurrentHashMap 通过 CAS 和 Synchronized 实现并发安全
- put放入元素的时候
- 首先根据 key 计算哈希定位 Node,如果对应位置的 Node 为 null,尝试 CAS 写入,失败就进入下次循环重试(最外层是个无限循环)
- 如果要放的位置为 MOVED(-1),说明其它线程正在扩容,参与一起扩容。
- 否则的话,通过 Synchronized 对 Node 加锁,判断是链表还是红黑树,写入数据,实现并发安全
- 最后进行检查,如果是链表,且长度超过阈值 8,就扩容数组/转换成红黑树(数组超过64)
- get获取元素的时候
- 直接根据哈希值,找对指定位置,如果头节点就是要找的直接返回
- 否则按链表/红黑树查找所要的元素
- get 操作不需要加锁,因为 Node 的元素 val 和指针 next 都是 volatile 修饰的,可以保证多线程下并发的可见性。
- 扩容的时候:
- 先根据运算得到需要遍历的次数i,然后利用tabAt方法获得i位置的元素f,初始化一个forwardNode实例fwd
- 如果f == null,则在table中的i位置放入fwd,否则采用头插法的方式把当前旧table数组的指定任务范围的数据给迁移到新的数组中。然后给旧table原位置赋值fwd。
- 直到遍历过所有的节点以后就完成了复制工作,把table指向nextTable,并更新sizeCtl为新数组大小的0.75倍,扩容完成。
- 在此期间如果其他线程的有读写操作都会判断head节点是否为forwardNode节点,如果是就帮助扩容。
CopyOnWriteArrayList
在读写锁(仅写操作排他)的基础上,更进一步,读取完全不用加锁,仅写写互斥需要同步。
- CopyOnWriteArrayList 类的所有可变操作,如add、set等,都是创建底层数组的副本,修改完后再替换原有数据实现的
- 对于读操作,内部array不会发生修改,只会被替换,因此无需任何同步控制就可以保证数据安全
- 对于写操作,加锁保证同步,避免多线程写的时候拷贝多份副本
并发安全的 Queue
Java 提供的线程安全的 Queue 分为阻塞队列、非阻塞队列。
非阻塞队列 - ConcurrentLinkedQueue
- 通过 CAS 实现线程安全
- 底层使用链表,在高并发环境下性能非常好
阻塞队列 - BlockingQueue
- 通过加锁实现线程安全
- 广泛用于生产者-消费者模型,队列容器已满时,生产者线程阻塞,队列容器为空时,消费者线程阻塞,直至队列非空
- 继承自 Queue,实现类有:
- ArrayBlockingQueue:数组实现的有界队列,创建时指定容量。采用 ReentrantLock 控制并发,默认非公平
- LinkedBlockingQueue:基于单向链表的无界/有界队列,可指定大小.采用 ReentrantLock 控制并发
- PriorityBlockingQueue:基于堆的无界队列,支持优先级,内部自动扩容。采用 ReentrantLock 控制并发
- SynchronousQueue:容量固定为 1 的同步队列,内部没有使用 AQS,而是通过 CAS 控制并发,生产和消费必须一一配对
- DelayedWorkQueue:基于堆的优先级阻塞队列
ConcurrentSkipListMap
利用空间换时间的思想,通过维护多层链表实现的 Map,查询时间复杂度 O(logN)。内部通过 CAS 实现并发安全。
IO
Java IO 体系
顶层两大类四个接口:
- InputStream/OutputStream:字节输入输出流
- FileInputStream/FileOutputStream: 文件输入输出流
- BufferedInputStream/BufferedOutputStream: 缓冲输入输出流,每次批量读/写字节到缓冲区,减少IO,提高重复单字节读写场景的效率
- ObjectInputStream/ObjectOutputStream: 对象序列化/反序列化流
- PrintStream:字节打印流
- Reader/Writer:字符输入输出流
- InputStreamReader/OutputStreamWriter: 字节 -> 字符的转换流
- FileReader/FileWriter: 文件字符输入输出流
- BufferedReader/BufferedWriter:缓冲字符字符输入输出流
- PrintWriter: 字符打印流
IO 中的设计模式
- 装饰器模式
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(fileName), "UTF-8"));
通过组合替代继承,在不改变原有对象的情况下扩展原始类的功能。 - 适配器模式
InputStreamReader对字节解码,将字节流转化为字符流,OutputStreamWriter对字符编码,将字符流转换为字节流
不同区装饰器侧重于动态增强原始类的功能,适配器专注解决接口不兼容,不能交互的类,让它们能够一起工作。 - 工厂模式
如Files::newInputStream创建InputStream对象,Paths::get创建Path对象… - 观察者模式
NIO中的文件目录监听服务基于WatchService接口、Watchable接口,内部通过一个守护线程定期轮询检测文件变化实现。
IO 模型
Unix中的五种IO模型:同步阻塞 I/O、同步非阻塞 I/O、I/O 多路复用、信号驱动 I/O 和异步 I/O
Java中的三种常见IO模型:
- BIO:同步阻塞IO,用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间
- NIO,同步非阻塞IO,准备数据阶段不阻塞,只有拷贝阶段才阻塞,应用程序要不断轮询数据是否准备好。而IO多路复用通过 select/epoll 等系统调用减少CPU使用。Java使用Selector、Channel、Buffer等抽象实现。
- AIO:异步IO,基于事件和回调机制
并发
线程安全的三大特性
- 原子性:若干个操作要么全部执行,要么全部不执行
- 可见性:当一个线程修改了共享变量的值,其他线程能够立即看到这个修改。(原因在于 Java 的共享内存模型,线程直接操作的都是缓存)
- 有序性:程序的执行顺序与代码的顺序相同(原因在于指令重排序)
Synchronized 保证了原子性和可见性:加互斥锁 -> 清空工作内存 -> 拷贝最新数据到工作内存 -> 执行代码 -> 刷新工作内存到主内存 -> 释放互斥锁
Volatile 保证了可见性和有序性:通过 store/load 指令保证对 volatile 变量的读写都是最新的,且通过内存屏障禁止指令重排序
Volatile 关键字
Volatile关键字的作用有两个:
- 保证变量的可见性:每次对 volatile 修饰的本地变量修改时,会立刻刷新回主内存,读取时也会先从主内存读入本地内存再访问
- 通过插入特定的内存屏障,禁止指令重排序
创建线程的方式
- 继承 Thread 创建线程类,重写 run 方法。
- 实现 Runnable 接口实现 run 方法,并作为参数来创建 Thread。
- 实现 Callable 接口实现 call 方法,并作为参数来创建 FutureTask。Callable可以获取到返回值
- 除此之外,还可以使用线程池来创建线程
线程生命周期
Java 线程在运行的生命周期中有 6 种不同状态:
- NEW:线程刚被创建的初始状态
- RUNNABLE:调用start后的运行状态
- BLOCKED:阻塞状态,需要等待锁释放
- WAITING:等待状态,等待其它线程的一些特殊事件,如notify(), join()
- TIMED_WAITING:有限等待
- TERMINATED:线程执行完毕的终止状态
其中,Java中的Runnnable状态包含OS层面线程的Ready和Running两个状态
减少线程切换
- 无锁并发编程
- CAS 算法
- 使用最少线程
- 协程
线程池
优点:
- 降低资源消耗
- 提高响应速度
- 提高线程的可管理性
Executor 框架:
JDK 5 引入的管理线程池的框架,包括三大部分:
- 任务 Runnable / Callable
- Callable可以返回结果/抛出异常
- 执行者 Executor
- 实现类 ThreadPoolExecutor,通过 execute/submit 提交执行
- 异步计算结果 Future
- 实现类 FutureTask
submit 和 execute 区别
submit可以获得执行结果。实现上是将 Runnable/Callable 对象封装成 RunnableFuture 传递给 execute 执行,而 RunnableFuture 继承自 Runnable 并且可以保存执行结果。execute只能执行 Runnable,因此不能获得执行结果
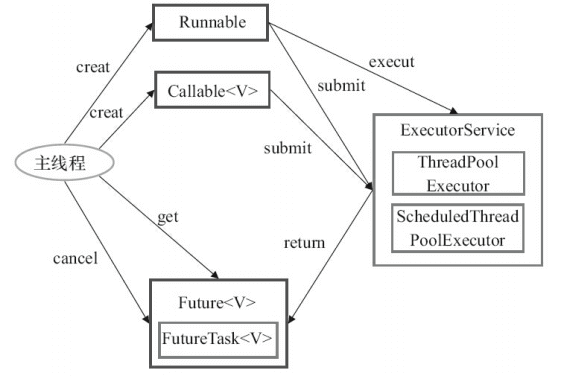
ThreadPoolExecutor
ThreadPoolExecutor(int corePoolSize, // 指定常驻线程数量
int maximumPoolSize, // 指定允许的最大线程数量
long keepAliveTime, // 当线程数量超过corePoolSize后,多余的空闲线程的存活时间
TimeUnit unit, // keepAliveTime单位
BlockingQueue<Runnable> workQueue, // 任务队列,保存被提交但尚未被执行的任务
ThreadFactory threadFactory, // 线程工厂,用于创建线程
RejectedExecutionHandler handler // 任务过多时的拒绝策略
)
- 任务队列 - BlockingQueue:指被提交但未执行的任务队列,一个BlockingQueue接口的对象,仅用于存放Runnable对象。常用的队列实现有:
SynchronousQueue: 直接提交的队列,没有容量,来一个任务执行一个,没有多余线程则执行拒绝策略ArrayBlockingQueue: 有界任务队列,构造时指定容量LinkedBlockingQueue: 无界任务队列,任务繁忙时会一直创建线程执行,直至资源耗尽PriorityBlockingQueue: 带有执行优先级的无界队列
- 拒绝策略 - RejectedExecutionHandler:指定当任务数量超过系统实际承载能力时的策略,通常是线程池中的线程已经用完,达到了最大线程数,排队队列也已满的情况。ThreadPoolExecutor提供了以下策略:
AbortPolicy: 默认策略,丢弃并抛出RejectedExecutionException异常CallersRunsPolicy: 绕过线程池,由主线程直接调用任务的run()方法执行DiscardOldestPolicy: 抛弃队列中等待最久的任务,然后尝试再次提交当前任务DiscardPolicy: 丢弃且不抛异常
线程数量设定
线程池的大小应该根据应用程序的负载进行调整,如果线程池太小,可能会导致应用程序的性能下降,因为没有足够的线程来处理所有的请求。如果线程池太大,也会导致程序的性能下降,因为线程之间的上下文切换会消耗大量的CPU时间。
- CPU 密集型:设置一个较小的线程数量,比如 N + 1,N 是 CPU 核心数,使得处理任务时充分利用 CPU
- IO 密集型:设置一个较大的线程数量,比如 2N + 1,使得 CPU 等待 IO 完成时可以处理其它任务
线程执行逻辑
在底层实现上,是不区分核心/非核心线程的,所有线程统一放在 Condition 的等待队列中,因此线程调度时执行的是轮询策略,线程池中的空闲线程依次执行任务。而过期销毁非核心线程是根据当前活跃的线程数来判断的。
sleep()和wait()对比
共同点:两者都可以暂停线程的执行
区别:
- sleep()不释放锁,而wait()会释放对应的对象锁
- wait()方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的notify()或者notifyAll()方法。除非使用 wait(long timeout) 超时后线程会自动苏醒。
- sleep()方法执行完成后,线程会自动苏醒
因此,wait()定义在Object类中,通常被用于线程间交互/通信,而sleep()是Thread类的静态方法,用于简单地暂停执行。
另外,yield() 方法是暂停当前正在执行的线程对象,并执行其他线程。join() 方法可以使得一个线程在另一个线程结束后再执行
CAS 底层实现
CAS 是一种通过硬件实现的乐观锁并发安全的技术,基本思想是,给定一个内存地址,一个期望值和一个新值,如果该地址的当前值和期望值相等,就用新值替换它,否则不做任何操作。底层实现依赖于 CPU 的 CAS 指令,保证了操作的原子性,Java 中可以通过 Unsafe 类的方法调用 CAS 指令。
CAS 存在 ABA 问题,可以通过版本号/标记位解决。
ThreadLocal 原理
每个线程内部都有一个 ThreadLocalMap 对象,本质上是一个键值对(key-value)映射,其中 key 是 ThreadLocal 实例对象本身的弱引用,value 是该线程内部的变量值。在不同线程中访问同一个 ThreadLocal 对象时,实际上是访问了各自线程内部的 ThreadLocalMap 对象中的不同 value,从而避免了多线程之间对变量的共享和访问冲突。
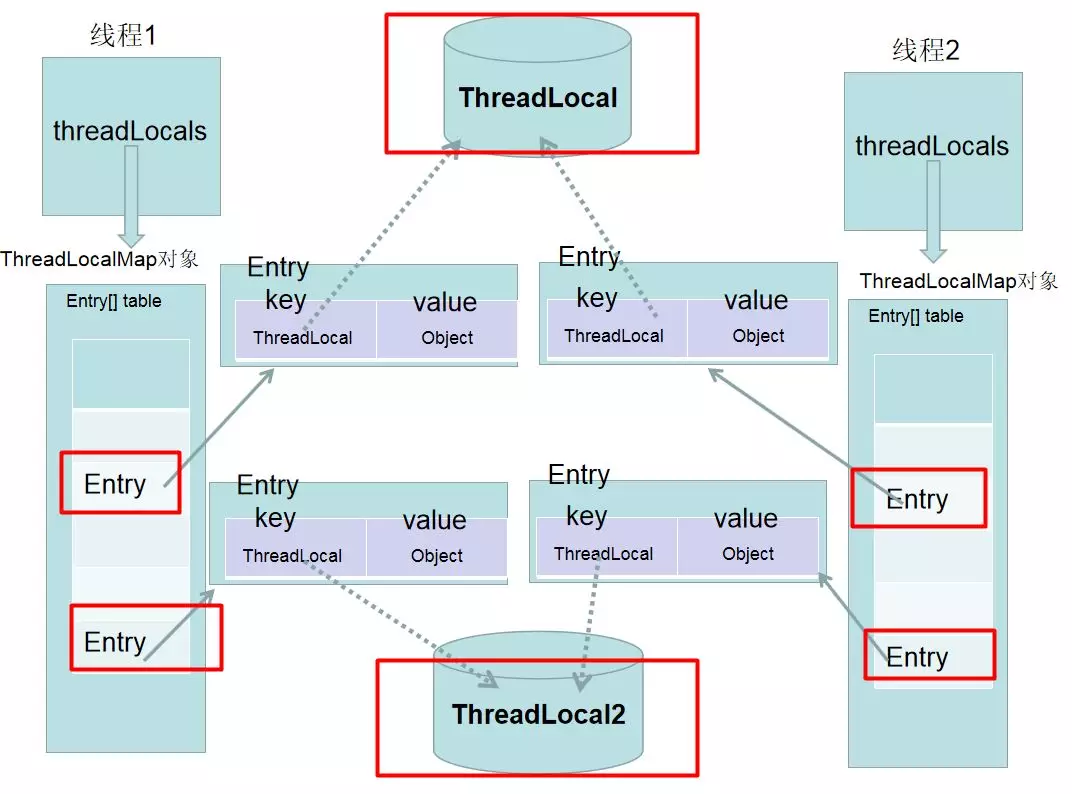
使用场景
- 例如 SimpleDateFormat/Random 这样的工具类,每个线程都要用到,如果每个线程都 new 一个很麻烦,因此可以改成static共用。但是可能会线程不安全,因此可以使用 threadLocal 每个线程分配一个,保证线程安全
- 对于同一个线程内所有方法需要共享的资源,比如用户信息,为了避免参数一层层显式传递,同时保证线程的安全,可以使用 threadLocal 保存。这样每个线程内访问的都是相同的资源,不同线程访问的是不同资源。
为什么是弱引用
假如使用强引用,当ThreadLocal不再使用需要回收时,发现某个线程中ThreadLocalMap存在该ThreadLocal的强引用,无法回收,从而造成内存泄漏。
使用弱引用可以防止长期存在的线程(通常使用了线程池)导致ThreadLocal无法回收造成内存泄漏。
内存泄漏问题
TheadLocalMap 的 key 所关联的 ThreadLocal 实例是弱引用,因此如果 key 没有其它关联的强引用,那么 key 就会被 GC 自动回收,而 value 是强引用不会被自动回收,导致 value 一直存在,产生内存泄漏。因此 ThreadLocal 在底层实现上会进行过期 Entry 的清理。
Set() 实现
- 根据当前线程获取 ThreadLocalMap 对象,没有的话就新建
- 计算 key 的哈希,内部的 nextHashCode() 每次添加时自增一个斐波那契数/黄金分割数,来和数组/槽容量相与(使得哈希分布更均匀)
- 如果哈希对应的槽为空,直接放入
- 如果槽非空
- 并且 key 为 null,即该 Entry 的 key 弱引用已被 GC,说明这是个过期的槽 staleSlot,执行 replaceStaleEntry() 然后返回
- 并且 key 和当前 ThreadLocal 一致,直接更新;不一致就向后遍历直到找到空槽
- 这时找到了一个空槽,创建一个新 Entry 放入
- 执行 cleanSomeSlots() 启发式清理;
- 启发式清理结束后,如果 size 超过阈值(容量2/3),进行探测式清理 expungeStaleEntry()
- 探测式清理结束后,如果 size 超过 3/4 * thresh 就执行 rehash()
过期 key 的清理
replaceStaleEntry()
- 从 staleSlot 向前迭代找过期槽,更新 slotToExpunge,直到空槽
- 从 staleSlot 向后迭代找 key 相同的,执行更新,直到空槽
- 最后从 slotToExpunge 开始执行启发式过期数据清理
启发式清理 - cleanSomeSlots()
- 当容量/2的位置开始探测式清理
探测式清理 - expungeStaleEntry()
- 以当前 Entry 往后清理,遇到值为 null 则结束清理,属于线性探测清理
get() 实现
- 计算 key 的哈希定位槽位
- 如果槽的 key 一致直接返回,否则向后迭代查找
- 迭代过程中如果发现空槽,触发探测式数据回收 expungeStaleEntry()
InheritableThreadLocal
ThreadLocal 无法在异步场景下给子线程共享父线程中创建的线程副本,可以使用 InheritableThreadLocal,在 Thread 构造方法中传递数据。
但一般异步处理都使用线程池复用,存在数据不一致问题,可以用阿里开源的 TransmittableThreadLocal 组件。
Synchronized 锁机制
指定对象/用于普通方法上是对实例对象加锁,指定类对象/用于静态方法就是对类加锁。本质上是竞争对象关联的 Monitor 对象的 Owner 身份。
JDK6 之前是基于监视器 Monitor 的重量级锁机制,在 JDK6 引入了偏向锁、轻量级锁等优化机制。
- 偏向锁:当一个线程访问同步块并获得锁时,会在对象头和栈帧的锁记录里存储锁偏向的线程 ID,然后下一次这个线程再次访问同步块时,如果该对象没有被其它线程竞争,就可以直接进入,不需要获取锁资源。目的是在无竞争的情况下,减小锁的获取和释放的操作,提高程序的性能。
- 轻量级锁:用于多线程交替执行同步块的场景。如果一个线程试图进入同步块,但是发现对象头里锁偏向的线程 ID 不是自己,就会引发竞争,这时偏向锁就会升级成轻量级锁。轻量级锁使用 CAS 操作来尝试获取锁。如果CAS操作失败,表示有竞争,锁就会膨胀为重量级锁。
- 重量级锁:使用操作系统的互斥量(Mutex)来实现锁。在重量级锁的状态下,线程会被阻塞,直到获取到锁。
除此之外,整个过程中还有自旋、自适应自旋等等的优化措施。
AQS
AbstractQueuedSynchronizer 抽象队列同步器,为建锁和同步器提供了一些通用功能的是实现,能简单且高效地构造出应用广泛的大量的同步器
核心思想
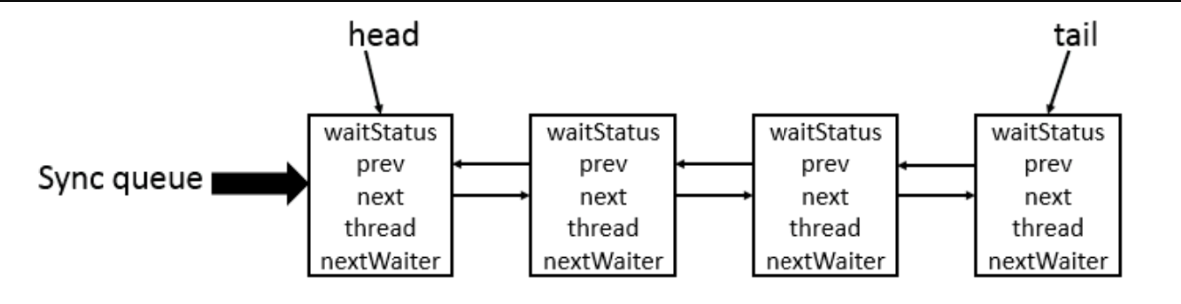
如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是基于 CLH 锁实现的。
CLH 锁是对自旋锁的一种改进,是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系),暂时获取不到锁的线程将被加入到该队列中。AQS 将每条请求共享资源的线程封装成一个 CLH 队列锁的一个结点(Node)来实现锁的分配。在 CLH 队列锁中,一个节点表示一个线程,它保存着线程的引用(thread)、 当前节点在队列中的状态(waitStatus)、前驱节点(prev)、后继节点(next)。
实现
AQS 使用 int 成员变量 state 表示同步状态,通过内置的 线程等待队列 来完成获取资源线程的排队工作。
两种资源共享方式:Exclusive 独占、Share 共享。
基于AQS的同步工具类:Semaphore, CountDownLatch, CyclicBarrier…
ReentrantLock 原理
ReentrantLock 属于乐观锁类型,默认非公平的,多线程并发情况下。能保证共享数据安全性,线程间有序性。它通过原子操作和阻塞实现锁机制,一般使用 lock 获取锁,unlock 释放锁。
ReentrantLock 的可重入功能基于 AQS 的同步状态 state 实现的。当某一线程获取锁后,将 state 值+1,并记录下当前持有锁的线程,再有线程来获取锁时,判断这个线程与持有锁的线程是否是同一个线程,如果是,将 state 值再 +1,如果不是,阻塞线程。
公平锁和非公平锁的实现
公平锁和非公平锁是两种不同的锁的实现方式,它们的区别在于是否保证等待锁的线程按照先来后到的顺序获取锁。公平锁会让线程进入一个队列中排队等待,每次只有队首的线程能够获取锁,这样可以避免线程饥饿,但是会增加线程切换的开销。非公平锁则不考虑等待顺序,每个线程都有机会抢占锁,这样可以提高响应速度,但是可能导致某些线程长时间得不到锁。
以基于 AQS 的 ReentrantLock 为例,如果是公平锁,会先判断队列中是否有其他等待的节点,如果有,则直接加入到队尾;如果没有,则尝试修改state变量的值。非公平锁则不管队列中是否有其他等待的节点,直接尝试修改 state 变量的值,如果成功,则获取到了锁;如果失败,则再判断队列中是否有其他等待的节点,如果有,则加入到队尾;如果没有,则再次尝试修改state变量的值。
JVM
内存区域
对象创建
创建过程:
- 类加载检查
- 遇到new指令时,先检查对应的类是否已经加载、解析和初始化,如果没有先执行类加载过程
- 分配内存
- 从堆中分配内存
- 分配方式:规整的碰撞指针法 或 不规整的空闲列表法(取决于GC算法)
- 并发问题:CAS+失败重试 或 TLAB预先分配的缓冲内存
- 初始化零值
- 设置对象头
- Mark Word:HashCode、GC分代年龄、锁状态、偏向标记等
- kClass Pointer:指向类元数据的指针
- 执行对象的
<init>方法(父类<init>-> 实例域语句 -> 构造方法)
对象内存布局:
- 对象头
- Mark Word:HashCode、GC分代年龄、锁状态、偏向标记等
- kClass Pointer:指向类元数据的指针
- 实例数据:对象真正存储的有效信息
- 对齐填充:8Byte对齐
对象访问定位:
栈帧的局部变量表中的reference引用 --> 堆中对象实例 和 方法区中对象类型
- 句柄:堆中划分句柄池,记录对象实例指针和对象类型指针。优点是稳定,对象移动时只要改变句柄
- 直接指针:直接指向堆中对象实例。优点是速度快,节省一次指针定位。
对象存活判断
判断方法
- 引用计数法:计数器加减。无法解决循环依赖问题
- 可达性分析:GC Roots 引用链分析,如果一个对象到 GC Roots 没有任何引用链相连,即不可达对象,可以被回收。GC Roots 通常包括:
- 虚拟机栈/本地方法栈 中引用的对象。
- 方法区中类静态属性引用的对象。
- 方法区中常量引用的对象。
引用类型
- 强引用
Strongly Reference:任何情况下都不回收此对象,甚至抛出OOM - 软引用
Soft Reference:可有可无,内存足够就不回收,内存溢出前才回收 - 弱引用
Weak Reference:弱于软引用,GC扫描到就立即回收 - 虚引用
Phantom Reference:也叫幻影引用,任何时候都可能被回收,主要用于跟踪对象被垃圾回收的活动
GC 算法
类文件结构
魔数、Class文件版本号、常量池、访问标志、当前类、父类、接口的索引集合、字段表集合、方法表集合、属性表集合 十大块。
类加载过程
- 加载(Loading): 类的加载阶段是指将类的字节码数据从文件或其他途径读取到内存中,并且在内存中创建一个代表该类的
java.lang.Class对象。类加载器负责完成加载阶段的工作。加载条件:仅当有类主动去使用该Class。包括new、反射、克隆、反序列化、调用类静态方法、调用其子类、main方法等等。 - 链接(Linking): 链接阶段包括三个子阶段:验证(Verification)、准备(Preparation)、解析(Resolution)。
- 验证: 确保被加载的类的正确性,包括文件格式的验证、元数据的验证、字节码的验证、符号引用的验证。
- 准备: 在方法区中为类的静态变量分配内存,并将其初始化为默认值。
- 解析: 将常量池内的符号引用替换为直接引用,得到类/接口/字段/方法在内存中的指针或偏移量
- 初始化(Initialization): 调用类对象的
<clinit>()方法,对类变量赋值。<clinit>是编译器自动收集类中所有类变量的赋值动作和静态代码块(static{}块)中的语句合并产生的。当初始化一个类时,其父类尚未初始化,则需要先触发其父类的初始化。虚拟机会保证一个类的初始化过程是线程安全的。 - 使用
- 卸载:该类的
Class对象被GC,要求:
- 该类的所有的实例对象都已被 GC,也就是说堆不存在该类的实例对象。
- 该类没有在其他任何地方被引用
- 该类的类加载器的实例已被 GC(所以JDK自带类加载器加载的类不会被回收)
类加载器
内置类加载器:
BoostrapClassLoader启动类加载器:C++实现的顶层加载器,负责加载java/base下的核心系统类ExtentionClassLoader扩展类加载器:负责加载扩展目录下的jar包和类。JDK 9 移除。PlatformClassLoader模块加载器:JDK9引入取代Ext,负责加载非核心模块类AppClassLoader应用程序类加载器:负责加载用户应用classpath下的所有jar包和类
双亲委派模型:
- 除 BootstrapClassLoader 外,每个类加载器都有对应的父类加载器。如果父类加载器为 null,默认就是 BootstrapClassLoader(自定义加载器继承ClassLoader)
- 任意一个 ClassLoader 在尝试加载一个类的时候,都会先自底向上尝试调用父类的
loadClass()方法去加载类,如果父类不能加载该类,再自顶向下交由子类去完成。 - 好处:避免类的重复加载,限制使用者对JVM系统的影响。保证了Java程序的稳定运行
内存排查工具
JMeter 压测
添加线程组 -> 查看结果树和汇总报告 -> 分析异常比例、吞吐量、响应时间等。
JConsole
Java 监视和管理控制台,根据 PID 连接查看进程信息,可以查看虚拟机内存使用情况,包括堆空间、Eden、Survivor等,包括 Young GC、Old GC 时间,以及线程数量等信息
jmapjstack 查看堆栈信息,以及排查死锁问题jhsdb jmap --heap --pid 20536 查看进程使用的GC算法、堆配置信息和各内存区域内存使用信息jstat -gc -h3 31736 1000 10 查看 GC 情况,各个空间的使用量jmap -dump:format=b,file=dump.hprof 20536 生成堆转储快照 heap profile -> VisualVM/JProfile 查看内存占用情况 -> 定位大对象 -> 定位代码中创建的位置 -> 排查 BUG
其它
反射机制
反射可以在运行时分析类以及执行类中方法,通过反射可以获取任意一个类的所有属性和方法,还可以调用这些方法和属性。例如 Spring、MyBatis 等框架大量使用反射机制,动态代理的实现也依赖于反射。
反射可以让代码更加灵活,为各种框架开箱即用提供便利;但也增加了安全问题,比如无视泛型参数的安全检查,性能也会稍差一点。
获取Class对象的四种方法:
- Target.class
- Class.forName(…)
- instance.getClass()
- ClassLoader::loadClass(…)
代理模式
代理模式是一种使用代理对象来代替对真实对象访问的设计模式,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。
静态代理
- 对目标对象每个方法的增强都手动完成。(创建接口,实现类和代理类,将目标对象注入进代理类,在代理类的对应方法调用目标类中的对应方法并做增强)
- JVM层面上,静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。
- 缺点:不灵活且麻烦
动态代理
- JVM 层面上,动态代理是在运行时动态生成类字节码,并加载到 JVM 中。更加灵活。
- JDK 动态代理:
Proxy.newProxyInstance(ClassLoader, Class[], InvocationHandler)获得某个类的代理对象- 当动态代理对象调用一个方法时,这个方法的调用就会被转发到实现 InvocationHandler 接口类的
invoke(ProxyObject, Method, args)方法来调用 - 缺点:只能代理实现了接口的类
- CGLIB 动态代理
- 一个基于ASM的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。通过继承方式实现代理。
- 例如 Spring 的 AOP 模块,如果目标对象实现了接口,则默认采用 JDK 动态代理,否则采用 CGLIB 动态代理。
- Enhancer 类用于动态获取被代理类
- 自定义
MethodInterceptor::intercept(Object, method, args, proxy)实现增强。当代理类调用方法的时候,实际调用的是 MethodInterceptor 中的 intercept 方法。
JDK 动态代理基于接口实现,只能代理实现了接口的类,而 CGLIB 基于继承,可以代理任何类。
异常机制
异常分类
Throwable是所有异常和错误的超类Error错误:一般是与 JVM 相关的问题,如系统崩溃,内存空间不足,方法调用栈溢出等。Error 一般会导致程序中断,并且无法恢复和预防。例如 OutOfMemoryError, StackOverFlowErrorException异常:程序运行中可以预料的意外情况,并且应该被捕获进行处理,使程序恢复运行RuntimeException运行时异常:都是非检查异常,例如 NullPointerException, ArrayIndexOutOfBounds, IllegalArgument…- 非运行时异常:都是检查异常/编译时异常,例如 IOException, NoSuchMethodException
检查异常在编译前需要手动处理,要么在方法上通过 throws 抛出,由调用该方法的方法处理异常,要么 try-catch 捕获异常自己处理。检查异常会在方法调用链上显式传递,因此推荐使用非检查异常。
finally 块原理
- 字节码层面上,会把 finally 语句复制到 try 和 catch 块的末尾。
- 如果 finally 块有 return 语句,那么 try/catch 块中的 return 都会失效。
- 如果 finally 块没有 return 语句,那么无论在 finally 块中是否修改返回值,返回值都不会改变,仍然是执行 finally 代码块之前的值。
- try-with-resources 语法糖经过编译后转换为 try-catch-finally 语句
static 关键字
static 关键字可以修饰 类、方法、变量和代码块。
- 修饰类:被 static 修饰的类称为静态内部类。静态内部类可以访问外部类的静态成员变量和方法,但不能访问外部类的非静态成员。
- 修饰方法:被 static 修饰的方法称为静态方法。静态方法可以直接通过类名调用,不需要实例化对象。静态方法只能访问类的静态成员变量和方法,不能访问非静态成员变量和方法。
- 修饰变量:被 static 修饰的变量称为静态变量,也称为类变量。静态变量在类加载时被初始化,并且所有对象共享同一个静态变量的值。静态变量可以通过类名直接访问,也可以通过对象名访问。
- 修饰代码块:被 static 修饰的代码块称为静态代码块。静态代码块在类加载时被执行,只执行一次。静态代码块通常用于初始化静态成员变量。
另外,子类不能覆写父类的静态方法(@Override会报错),但是可以定义相同方法将其隐藏。
equals() 和 hashcode()
- 在Java中,如果两个对象的 equals() 返回 true,则它们的 hashcode() 必须返回相同的值。
- 因为在 Java 中,hashcode() 用于获取对象的哈希值,而哈希值用于确定对象在哈希表中的索引位置。如果索引位置上已经有元素了,会调用 equals() 判断两个对象是否相同,相同就添加失败,不相同就散列到其它位置上。
- 如果重写了 equals(), 但没有重写 hashcode(),会导致所有对象的 hashcode 都不相同,都能添加成功,那么基于哈希的集合就会出现很多重复元素
String 类型
存储位置
// 在方法区的常量池中,引用存储的也是常量池中的地址(常量池在编译期间就会生成)
String str1 = "hello";
String str2 = "hello";
System.out.println(str1==str2); //true
// 堆中,引用存储的也是堆中的地址
String str3 = new String("高大天");
String str4 = new String("高大天");
System.out.println(str3==str4); //false
在进行字符串拼接时,如果都是静态字符串相加,结果会加入常量池;如果含有变量则不会进入常量池。String::intern() 会将该字符串对应的常量加入常量池,并返回在常量池中的地址。
不可变对象
String 底层是 final 修饰的 char[] 数组,因此是不可变的。好处是便于实现字符串常量池,使多线程安全,避免安全问题,以及加快字符串处理速度。StringBuilder不是线程安全的,而StringBuffer是线程安全的
MySQL
三范式
- 第一范式: 要求任何一张表必须有主键,每个字段都不可再分。
- 第二范式: 建立在第一范式的基础之上,要求所有非主键字段完全依赖主键,不要产生部分依赖。
- 第三范式: 建立在第二范式的基础之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。
SQL 注入
所谓SQL注入,就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
- 尽量用预编译机制 prepareStatement,少用字符串拼接的方式传参,它是sql注入问题的根源。
- 要对特殊字符转义,比如 % 作为 like 语句中的参数时,要对其进行转义处理
- 对所有的异常情况进行捕获,不要在接口直接返回异常信息,因为有些异常信息中包含了sql信息,比如库名,表名,字段名等。攻击者拿着这些信息,就能通过sql注入随心所欲的攻击你的数据库了。
- 使用sqlMap等代码检测工具,它能检测sql注入漏洞。
- 需要对数据库sql的执行情况进行监控,有异常情况,及时邮件或短信提醒。
- 对生产环境的数据库建立单独的账号,只分配DML相关权限,且不能访问系统表。切勿在程序中直接使用管理员账号。
- 建立代码review机制,能找出部分隐藏的问题,提升代码质量。
- 对于不能使用预编译传参时,要么开启druid的filter防火墙,要么自己写代码逻辑过滤掉所有可能的注入关键字。
架构
主要分为两层:Server 层和存储引擎层。
- Server 层:负责 MySQL 的所有核心服务,包括连接管理、安全认证、SQL 解析与执行、事务管理、并发控制、日志记录等。Server 层与存储引擎层之间通过 API 进行通信。
- 存储引擎层:负责 MySQL 数据的存储和读取。MySQL 支持多种存储引擎,如 InnoDB、MyISAM、Memory、CSV 等。每个存储引擎都有其独特的数据存储和索引结构,可以根据不同的场景选择不同的存储引擎,提高数据访问效率。
在架构上,MySQL 的 Server 层和存储引擎层是相互独立的,用户可以通过替换存储引擎来改变 MySQL 的数据存储方式,而不会影响 MySQL Server 层的其他功能。
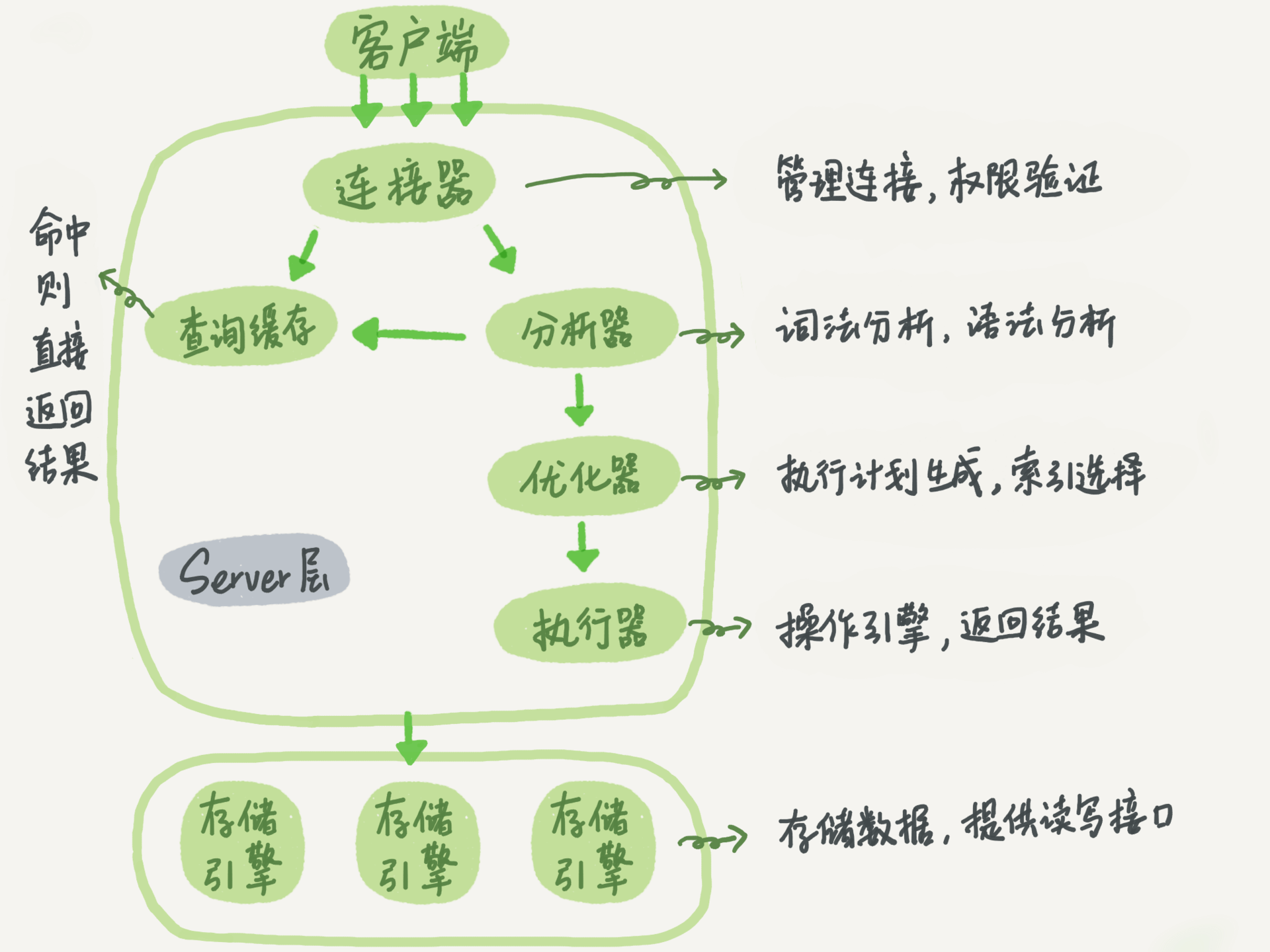
InnoDb 和 MyISAM 区别
- InnoDB 支持事务和 MVCC,MyISAM 不支持
- InnoDB 支持外键,MyISAM 不支持
- InnoDB 支持行级锁和表级锁,并且默认就是行级锁,MyISAM 只支持表级锁
- InnoDB 是聚集索引,数据即索引,MyISAM 只有二级索引,数据和索引是分离的
- InnoDB 不支持全文检索,MyISAM 支持
MyISAM 的优势
- 快速:MyISAM 存储引擎使用表级锁,因此在读写操作时不会出现死锁问题,且在读操作时不需要加锁,因此读取速度较快,适合于以读操作为主的应用场景。
- 索引:MyISAM 存储引擎支持全文本索引和空间索引,能够满足一些特殊的查询需求。
- 低存储空间:MyISAM 存储引擎对数据存储的方式非常紧凑,数据文件大小通常比 InnoDB 存储引擎小,因此对于存储空间有限的应用场景来说,MyISAM 更为适合。
对比 NoSQL
- 关系型数据库基于表的结构,适用于处理结构化数据;NoSQL 通常是键值对、文档、图形等数据结构,适合存储半结构化/非结构化数据
- MySQL 数据表需要严谨的设计;NoSQL 数据库不需要事先设计好,支持动态添加字段和修改结构,灵活性和扩展性更好
- MySQL 使用 SQL 语句进行查询,支持复杂的关系查询和聚合操作;NoSQL 则使用各种不同的查询语句进行查询,不支持复杂关系查询,但读取和写入效率更高
使用场景需要基于应用的实际需求、数据处理量、数据类型和数据访问模式等考虑。MySQL 适合数据结构固定、需要处理事务、处理海量数据、高度关联的应用。NoSQL 适合处理非结构化数据、高扩展性和高并发、实时查询、数据分析的场景。
索引
索引类型
- 聚集索引:按表中的主键建立的索引,叶子节点存放的就是实际的行数据。(主键索引)
- 非聚集索引:按表中的非主键建立的索引,叶子节点存放的是主键值,如果需要其他列信息需要进行回表查询。(非主键/二级索引)
B+树 对比
- 使用哈希表可以把检索单个数据的复杂度近似为O(1),但是哈希表不支持排序和范围查找,如果是带条件的批量检索数据就得一次次 IO 去查找
- 红黑树在大数据量的情况下,层级较深,可能导致检索速度慢的问题
- B 树(B- 树),一种多路平衡查找树,它的所有节点既放键,也放数据,所以一个数据页中存储的键值对比较少,因此空间利用率较低,进而导致 IO 次数增加,性能降低
- 而 B+ 树,仅在叶子节点存放数据,非叶子节点只存放下一层的索引,因此查询效率比较稳定;在大数据量的情况下,树的高度较小,查询性能好;同时还支持排序和范围查找。
注:InnoDB 的数据是按数据页为单位来读写的,当需要读一条记录的时候,并不是将这个记录本身从磁盘读出来,而是以页为单位,将其整体读入内存。在 InnoDB 中,每个数据页的大小默认是 16KB。
索引失效情况
- 使用 SELECT * 进行查询;
- 创建了联合索引,但查询条件没有遵循最左匹配原则;
- 在索引列上进行计算、函数、(显式/隐式)类型转换等操作(可能破坏索引值的有序性,因此优化器直接放弃使用索引);
- 以 % 开头的 LIKE 查询比如 like ‘%abc’;
- 查询条件中使用 or,且 or 的前后条件中有一个列没有索引,涉及的索引都不会被使用到;
索引优化
- 在经常用于查询的列上建立索引
- 尽量使用覆盖索引(索引覆盖了查询需求),避免回表
- 避免索引失效
- 索引也不能过多,造成写入性能降低(自增的主键对写入性能影响小,而非自增主键可能引起页分裂导致写性能降低)
- 对字符串可以使用前缀索引(如身份证这样的长字符串不适合做主键,索引空间占用过多。但要合理选择前缀的长度,可以根据区分度来选择)
- 索引下推优化:在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数(而不是每条记录都回表再判断是否符合条件)
- 考虑区分度:区分度指的是索引列中不同值的个数与总记录数之比,用于衡量索引列的区分度。区分度越高,索引效果越好,查询速度越快。
- 使用缓存、分库分表、优化硬件和系统
事务
四个特征
- 原子性:事务中包含的操作要么全部执行,要么全部不执行
- 一致性:事务执行前后,数据库的完整性没有被破坏,即满足所有的约束条件和业务规则
- 隔离性:事务间互不干扰,一个事务的执行不受其他事务的影响,也不影响其他事务。
- 持久性:事务一旦提交,其对数据库的修改就会永久保存,即使发生系统故障或崩溃也不会丢失
并发问题
- 脏写:一个事务修改了另一个未提交事务修改过的数据
- 脏读:一个事务读到了另一个事务还未提交的数据
- 不可重复读:一个事务先后读取同一条记录,期间另一个事务修改了数据,导致第一个事务两次读取的数据不一致
- 幻读:一个事务按照某些条件查询,期间另一个事务插入了新的数据,导致第一个事务再次查询时发现多出一些记录
隔离级别
Read_Uncommited: 读未提交,允许读取并发事务尚未提交的数据。可能产生脏读、不可重复读、幻读等问题Read_Commited: 读已提交,允许读取并发事务已经提交的数据,可以阻止脏读Repeatable_Read: 可重复读,对同一字段的多次读取结果都一致,可以阻止脏读、不可重复读问题Serializable: 可串行化,所有事务依次执行,可以阻止所有并发问题。
MySQL默认是 RR,并且通过 MVVC 机制阻止了幻读问题。
三大日志
一个事务的日志操作顺序:加载数据页 -> 写 Undo Log -> 写 Redo Log -> 写 Bin Log -> 提交 Redo Log
Undo Log
更新行记录时,首先将数据页加载到 BufferPool,然后将旧值写入 Undo Log,存储事务执行之前的数据版本。作用有二:
- 当事务回滚或者发生其他异常时,可以利用 Undo Log 将数据恢复到事务开始之前的状态。
- 用于 MVVC,读取记录时判断版本是否对当前事务可见,以此实现非锁定读
分类:
- insert undo log:insert操作仅对本事务可见,因此在事务提交后可直接删除
- update undo log:update/delete操作,需要提供MVVC,因此分两阶段 delete_mark -> purge
Redo Log
执行器更新完 BufferPool 里的数据页后,写入 Redo Log 重做日志,记录事务对数据库所做的修改,保证在发生数据库故障时,可以通过重做日志将数据库恢复到事务提交后的状态。
原因:
数据库按页面从磁盘读取数据加载到 Buffer Pool 中,后续的操作都是对 Buffer Pool 进行,因此需要定时把 Buffer Pool 写回磁盘,但是
- 刷新整个页面过于浪费
- 写入磁盘是随机IO,速度慢
因此,MySQL 在事务执行过程中利用 Redo Log,记录修改的具体信息,这样即使系统崩溃也能快速恢复数据,而且:
- 占用空间小
- 写入是顺序IO,速度快
刷盘时机:
每条 redo 记录由"表空间号+数据页号+偏移量+修改数据长度+具体修改的数据"组成。innodb_flush_log_at_trx_commit参数控制刷盘策略:
- 0:事务提交时不立即向磁盘同步redo日志,交给后台线程
- 1:默认值,事务提交时立即同步 (fsync)
- 2:事务提交时将redo日志写入OS缓冲区,不保证立即刷新到磁盘。这种方式除非DB和OS都挂了,否则是能够保证持久性的
日志文件组:
硬盘上的Redo Log文件有多个,构成一个环形日志文件组,循环写入。
日志组维护两个属性,一个 write_pos 是当前记录的位置,一个 checkpoint 是已经刷盘的位置。
Bin Log
执行器写完 Redo Log 后,开始写 Bin Log,最后再写 Redo Log 完成两阶段提交。binlog 是一种逻辑日志,记录数据库中所有的修改操作,用于数据备份、主从复制以及数据恢复。
三种格式:
- statement:记录SQL原文。可能产生数据不一致,例如时间函数now()
- row: 默认。记录SQL原文以及操作的具体数据。占空间,而且消耗IO资源
- mixed:混合前两种,根据是否可能引起数据不一致采用row/statement
写入时机:
事务执行时,先写入 binlog cache,提交时再写入磁盘上的 binlog 文件。sync_binlog 变量控制刷盘时机:
- 0:每次提交事务仅 write(写入系统缓存),由OS负责 fsync (写入磁盘)
- 1:每次提交任务都 fsync
- N:每次提交任务仅 write,累积 N 个事务后 fsync
两阶段提交:
redo log 让 InnoDB 存储引擎拥有了崩溃恢复能力。binlog 保证了 MySQL 的数据持久性。因此需要确保两份日志的一致性,为此采用两阶段提交机制:
- 将 redo log 拆分成 prepare 和 commit 两阶段,事务写入 Redo Log 后就处于 prepare 状态
- 事务写入 binlog 后,再将 redo log 设为 commit 状态,最后提交事务
- 事务期间如果发生异常
- 查询 redo log 处于 commit 则直接提交就行
- 查询 redo log 处于 prepare,且 redo log 里面的 XID 和 bin log 里面的 XID 一致,说明两份日志逻辑一致,可以直接提交
- 否则回滚事务
如果不使用两阶段提交,无论是先写 Redo Log 再写 Bin Log 还是反过来,一旦期间发生崩溃,都会导致用日志恢复出来的数据和原库不一致。

MVVC 机制
MVVC 基于 Undo Log 实现了非锁定读。
- 快照读:也叫非锁定读,读取操作不会去等待行上锁的释放,而是读取行的一个快照数据,根据版本号/时间戳判断可见性
- 当前读:也叫锁定读,通过加锁,总是读取数据的最新版本
行记录的隐藏字段
- row_id: 可选,没有主键/Unique字段的记录,引擎默认生成该隐藏列作为主键
- transaction_id: 最后一次插入或更新该行的事务 id
- roll_pointer: 回滚指针,指向该行的 undo log(构成的版本链)
ReadView
| 字段 | 含义 |
|---|---|
| m_ids | 生成 ReadView 时系统中活跃的读写事务的id列表 |
| min_trx_id | 生成 ReadView 时系统中活跃的读写事务最小id |
| max_trx_id | 生成 ReadView 时系统应分配给下一个事务的id值(最大活跃事务id+1) |
| creator_trx_id | 生成该 ReadView 的事务id(仅实际增删改时才分配,只读事务id默认0) |
访问规则
有了 ReadView 后,查询过程会顺着版本链遍历,根据ReadView的访问规则,直到找到一条可访问的版本,或不含该记录。其中,trx_id 为被访问版本的 transaction_id 属性值:
| 条件 | 是否可以访问 | 说明 |
|---|---|---|
| trx_id == creator_trx_id | 可以访问该版本 | 成立,说明数据是当前事务自己更改的 |
| trx_id < min_trx_id | 可以访问该版本 | 成立,说明该版本在当前事务生成 ReadView 前已经提交 |
| trx_id > max_trx_id | 不可以访问该版本 | 成立,说明该版本在当前事务生成 ReadView 后才开启 |
| min_trx_id <= trx_id <= max_trx_id | 如果trx_id在m_ids中,不可以访问;否则可以访问 | m_ids存在trx_id则说明该事务还是活跃的,不存在则说明该事务已提交 |
不同隔离级别
- Read_Uncommited: 读取记录时直接查看最新版本,没有视图概念
- Read_Commited: 事务每次 SELECT 查询前都会生成独立的 ReadView,因此导致不可重复读
- Repeatable_Read: 事务只在第一次 SELECT 查询前生成一个 ReadView,整个事务期间共享该 ReadView,因此可以避免不可重复读的问题
- Seriablizable:加锁来避免并发访问
RR 防止幻读
- 对于 普通的select,RR使用 MVVC 快照读 解决幻读问题
- 对于 select…for update/lock in share mode 等当前读,InnoDB使用临键锁对查询范围加锁以防止幻读
锁机制
InnoDB 支持多粒度锁,特定场景下,行级锁可以与表级锁共存。
全局锁
flush tables with read lock 对整个库加只读锁,常用于全库的逻辑备份。
mysqldump -single-transaction 适用于支持事务的引擎的逻辑备份。
表级锁
表级锁对整张表上锁,实现简单粒度粗,因此并发性能差。
lock tables ... read/write
意向锁:一种不与行级锁冲突的表级锁,由引擎维护,无法手动操作的。分:
- 意向共享锁 S:事务有意向对表中的某些行加共享锁
- 意向排他锁 X:事务有意向对表中的某些行加排他锁
意向锁不会与行级的共享 / 排他锁互斥。一个事务想要对一个数据行加锁时,会先获取该数据行所在表的意向锁。这样其它事务对表加排他锁时可以直接检测表的意向锁,而不用检测每一行是否有排他锁。
行级锁
行级锁对一个行记录上锁,粒度细,并发性能好。
细分的话,行级锁分三种:
- 记录锁,锁定单个行记录
- 间隙锁,对索引记录的间隙上锁,确保索引记录间隙不变,防止其他事务在这个间隙插入新记录
- 临键锁,是记录锁和间隙锁的组合,同时锁住行记录和记录前面的间隙
加行锁时,实行两阶段协议:需要时上锁,事务结束 commit 时才释放。因此,一般要把容易产生锁冲突、影响并发度的加锁语句放在后面。默认情况下,InnoDB在查询时使用临键锁来保证数据的一致性和避免幻读问题,不同隔离级别使用的锁不一样。
加锁语句
-- 快照读,不加锁
select ...
-- 对满足查询条件的行加上行级写锁
select ... for update
-- 加共享读锁
SELECT ... LOCK IN SHARE MODE
select ... for share
-- 加表锁
LOCK TABLES
UNLOCK TABLES
主从同步
主从同步指多个从服务器实时将主服务器上的数据同步到从服务器上,以实现数据备份、负载均衡、容灾等功能。
- 主服务器将更改记录到二进制日志(binlog)中,记录所有更改数据的日志。
- 从服务器通过 change master 设置主库的 IP、端口、用户名、密码、日志文件位置等
- 从服务器执行 start slave 命令,启动两个线程,一个 I/O 线程,一个 SQL 线程
- IO 线程请求主库的 binlog,写入自己的 Relay Log 中继日志中。而主库会生成 Log Dump 线程负责给从库 IO 线程传输 BinLog
- SQL 线程读取 Relay Log,并解析成具体的操作,实现主从操作的一致性,最终数据保持一致
show master status;查看 Master 状态show slave status查看 Slave 状态
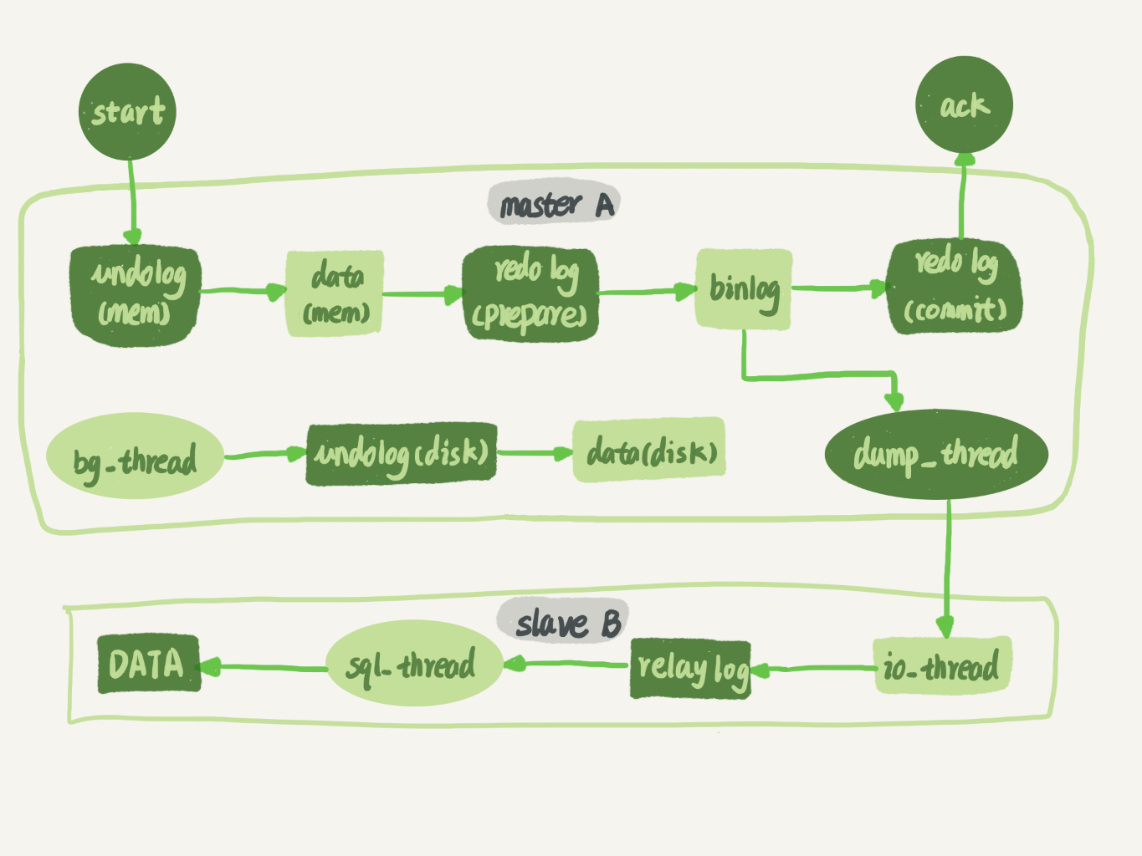
主从复制原理
- 主库将数据库中数据的变化写入到 binlog
- 从库连接主库
- 从库创建一个 I/O 线程向主库请求更新的 binlog
- 主库创建一个 binlog dump 线程来发送 binlog ,从库中的 I/O 线程负责接收
- 从库的 I/O 线程将接收的 binlog 写入到 relay log 中
- 从库的 SQL 线程读取 relay log 同步数据本地(也就是再执行一遍 SQL )。
但是由于主从同步延迟,可能导致数据不一致的问题,解决方案:
- 强制将读请求路由到主库处理:例如 Sharding-JDBC,实现简单但会增加主库压力
- 延迟读取
读写分离
读写分离主要是为了将对数据库的读写操作分散到不同的数据库节点上,可以小幅提升写性能,大幅提升读性能。
通过多台数据库服务器,配置主从复制,然后写请求发给 Master,读请求发给 Slaves。具体实现方法:
- 代理方式:例如 MyCat,MySQL Router等
- 组件方式:Sharding-JDBC
分库分表
见:MySQL01
SQL 语句
执行过程
- 语法解析:数据库会首先对 SQL 语句进行语法解析,确定查询的语义和执行的操作,如果语法不正确,会直接返回错误信息。
- 查询优化:数据库会对 SQL 语句进行查询优化,包括表选择、连接方式、索引使用等等,以找到最优的查询执行计划。
- 编译执行计划:优化器找到最优的执行计划后,会将该执行计划编译成可执行的机器码。
- 执行查询:数据库引擎开始执行编译后的机器码,按照执行计划从存储引擎中获取数据,并进行筛选、排序、聚合等操作,最终生成结果集。
- 返回结果:执行完毕后,数据库将结果集返回给客户端应用程序。
优化:创建索引、数据分区、避免全表扫描、合理使用缓存
语法语句
执行顺序:from -> where -> group by -> having -> select -> order by -> limit (MySQL 中 group by / having 可以使用 select 指定的别名)
-- 表清空,并重置自增计数器.
truncate ta_name;
-- 仅重置自增计数器
ALTER TABLE tb_name auto_increment=1;
-- count(*) 会统计所有非 null 个数,包括 0
-- sum(if(exp, 1, 0)) 可以排除 0 值求和
-- case 条件语句
select CASE
when age < 25 then '25岁以下'
when age >= 25 then '25岁及以上'
END as age_cnt, count(*) number
from ...
-- if 条件语句
select if(1 < 2, 1, 0) ...
-- 日期格式化
select date_format(date, "%Y-%m") from ...
select year(date)/month(date) from ...
-- 日期增加函数
SELECT DATE_ADD(orderDate, INTERVAL 2 DAY) from ...
-- 日期差,以 MINUTE/SECOND/HOUR 等返回
select TIMESTAMPDIFF(MINUTE, start_time, end_time) ...
-- 取后面一行的 timestamp 列
select lead(timestamp, 1, null) over (
-- 按 trace_id 水平分片
parition by trace_id
order by timestamp
) as toTime from ...;
-- 截取子串, start 从 1 开始
select substr(str, start, len) from ...
-- 将字符串 str 按 , 分割,选取第n个前的字符
select substring_index(str, ",", 1) from ...
-- 删除 str 中 前后/前导/尾随 的 "xxx"
select trim( {BOTH/LEADING/TRAILING} "xxx" from str) from ...
select concat(s1, s2, ...) from xxx;
select upper(s)/lower(s) from xxx;
-- 组内拼接字符串
select group_concat(distinct concat_ws(':', date(start_time), tag) SEPARATOR ';') as detail
-- 窗口函数,用于对数据实时分析处理,即本行以及之前的行进行计算
-- 如 rank(), dense_rank(), row_number() 以及 聚合函数
-- group by 分组后每个类别聚合成一行,而窗口函数不会减少行数
select <窗口函数> over (partition by <分组列> order by <排序列>) from ...
-- 索引
CREATE [UNIQUE | FULLTEXT] INDEX index_name on tb_name(col1, col2);
ALTER TABLE <表名> ADD [UNIQUE | FULLTEXT] [INDEX] index_content(content);
DROP INDEX <索引名> ON <表名>
ALTER TABLE <表名> DROP INDEX <索引名>
-- 重新统计索引信息
analyze table t;
-- 重建表,使得索引紧凑,节约存储空间
alter table t engine = InnoDB;
optimize table t;
-- 强制使用索引 a
select * from t force index(a) where ...
count 效率
count(字段) < count(主键id) < count(1) ≈ count(*)
InnoDB 计数时需要先获取所需字段,然后判断是否可能为空,如果不可能为空计数器直接+1,否则还要取出字段判断是否为空再修改计数器,影响性能。因此应尽量使用 count(*)。
Redis
数据结构
- 5 种基本数据结构:
- String 字符串:基于 SDS 简单动态字符串的结构,记录了当前长度,修改时可以根据字符串长度动态扩展
- List 列表:基于双向链表的实现
- Hash 散列:基于压缩列表或哈希字典,是一个 String 类型键值对的映射表
- Set 集合:基于压缩列表或整数集合实现的无序集合,其中的的元素没有先后顺序但都唯一,底层用哈希表实现
- Zset 有序集合:基于压缩列表或跳表,相比于 Set,Zset 增加了一个分数 score,使得集合中元素可以按分值进行有序排列
- 3 种特殊数据结构:
- HyperLogLogs 基数统计
- Bitmap 位存储:连续的二进制位,每个bit表示某个元素的对应值或状态
- Geospatial 地理位置
速度快的原因
- 内存存储:In-Memory 存储,没有磁盘 IO 开销
- 单线程模型:使用单个线程处理请求,避免了多个线程之间切换和锁资源的开销
- 非阻塞IO:Redis 使用基于 epoll 多路复用技术,提高了网络 IO 的性能
- 优化的数据结构
- 底层模型:Redis 自己构建了 VM 虚拟内存机制(冷热数据分离)
另外,Redis 的事务模型主要关注原子性和隔离性,而不提供传统数据库的一致性(在一个 MULTI/EXEC 事务块中发生错误可能产生不一致)和持久性(依赖持久化机制)。
线程模型
Redis 服务器是基于 Reactor 模式的单线程事件驱动程序,处理文件事件和时间事件。
- 时间事件:定时/周期性操作,目前是只有serverCron一个时间函数
- 文件事件:Redis 通过 IO 多路复用程序 来监听多个socket,每当一个socket准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件。然后文件事件分派器会接收I/O多路复用程序传来的套接字,并根据套接字产生的事件的类型调用相应的事件处理器,也就是与不同任务的套接字关联的一个个函数。
Redis 6 引入了多线程模型,但是仅用于网络数据的读写这类耗时操作上,来提高网络IO的读写性能,执行命令仍然是单线程顺序执行。
过期删除策略
- 惰性删除 :只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
- 定期删除 : 每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 定期删除+惰性删除 结合的方式,在一定时间内分多次遍历服务器中的各个数据库,从expires字典中随机检查一部分键的过期时间,并删除过期键。
缓存淘汰机制
- volatile-lru(least recently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru(least recently used):当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0 版本后增加以下两种:
- volatile-lfu(least frequently used):从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
- allkeys-lfu(least frequently used):当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
持久化机制
RDB - 快照
将某一时刻的内存数据,以二进制的方式写入磁盘。可以将快照复制到其他服务器从而创建具有相同数据的服务器副本,也可以将快照留在原地以便重启服务器的时候使用。
两种命令:
- save 命令:主线程执行,会阻塞主线程;
- bgsave : 子线程执行,不会阻塞主线程,默认选项。
RDB 默认的保存文件为 dump.rdb,优点是以二进制存储的,因此占用的空间更小、数据存储更紧凑,与 AOF 相比,RDB 具备更快的重启恢复能力。但是有数据丢失的风险。
AOF - 仅追加文件
指将所有的操作命令,以文本的形式追加到文件中。appendfsync 决定何时写入磁盘,appendfsync 选项值:
- always:每次有数据修改发生时都会写入AOF文件。效率最慢,安全性最高
- everysec:默认,每秒钟同步一次,显式地将多个写命令同步到硬盘。效率适中
- no:由 OS 决定何时进行同步。效率最高安全性最差
AOF重写:
为了避免大量写命令造成AOF文件体积过大,以及还原时间过长,需要用 BGREWRITEAOF 命令,通过读取数据库中的键值对,对AOF文件重写。在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
优点是存储频率更高,因此丢失数据的风险就越低,并且 AOF 并不是以二进制存储的,所以它的存储信息更易懂。缺点是占用空间大,重启之后的数据恢复速度比较慢。
缓存三大问题
缓存穿透
大量请求的 key 不合理,既不存在于缓存,也不存在于数据库 。导致这些请求直接到达数据库服务器,根本不经过缓存这一层,从而对数据库造成了巨大的压力。
解决方法:
- 接口层进行校验,如用户鉴权,id 做基础校验,id 不合法的直接拦截
- 缓存中设置无效的 key,例如
set <key> nullObject - 布隆过滤器(多个 hash 函数,key 对应的 hashCode 都存在,该元素才可能存在)
缓存击穿
请求的 key 对应的是热点数据 ,该数据存在于数据库中,但可能由于缓存过期,不存在于缓存中。进而导致瞬时大量的请求直接打到了数据库上,对数据库造成了巨大的压力。
解决方法:
- 针对热点数据提前预热,设置热点数据永不过期
- 通过分布式锁,保证只有第一个请求会落到数据库上,并将数据存入缓存。后续的请求可以直接从缓存中取数据,减少数据库的压力
- 接口限流、熔断、降级
缓存雪崩
缓存在同一时间大面积的失效,或缓存服务器宕机,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。
解决方法:
- 搭建高可用的 Redis 集群,避免单点故障(主从、哨兵、集群)
- 设置不同的失效时间,防止同一时间大量 key 失效。例如随机设置过期时间。
分布式锁
原理:基于 Redis(单线程)的原子操作 set <key> <random_value> NX EX 30,仅当 key 不存在时才会设置成功,否则返回 nil。
优化:
- 防止解锁失败(掉线/宕机)造成程序死锁,key 必须设置过期时间。且和加锁应是原子的
- 为了防止锁过期后解锁操作误删了其它线程加的锁,因此可以给 value 设为该线程唯一的 UUID,解锁时先获取锁的值,和自己的 UUID 相等才删除。
- 为了防止网络请求的延迟,造成误删其它线程加的锁,获取 value 进行对比和 删除 key 必须是原子的,可以使用 Lua 脚本实现。
- 为了防止业务还未完成锁已经过期释放了,需要对锁进行自动续期,或直接设置一个很长的过期时间,例如业务中可以设 300s
缓存一致性问题
指缓存与数据库的一致性问题,一般不要求强一致性,都是追求最终一致性。
更新数据库 -> 删除缓存
- 并发时可能有暂时的脏数据
- 解决方法:
- 重试机制,例如配合 MQ/Canal
- 加分布式锁,原子地更新数据库和缓存。但是存在缓存资源浪费、性能降低的问题
删除缓存 -> 更新数据库
- 并发时依然有不一致的问题(A删除缓存,B查缓存不存在取数据库,然后又把旧数据存入缓存)
- 解决方法:延迟双删,即删除缓存后更新数据库,然后等一段时间再删除缓存。但延迟时间很难评估
设计思路
- 缓存数据不应该是实时性、一致性要求超高的,所以缓存 + 过期时间,足够解决大部分业务对于缓存的要求
- 性能和一致性不能同时满足,为了性能考虑,通常会采用「最终一致性」的方案
- 遇到实时性、一致性要求高的数据,即使速度慢点,也应该查数据库
- 我们不应该过度设计,增加系统的复杂性
高可用模式
主从复制
- 将一个 Redis 实例作为主节点,多个 Redis 实例作为从节点,主节点将自己的数据同步到从节点。(数据的完整副本)
- 从节点可以提供读取服务,实现读写分离。
- 当主节点宕机时,可以在从节点中选举出一个新的主节点来保证服务的可用性。
- 优点是部署简单,并且由于保存了数据的完整副本,因此降低了数据丢失的风险。
- 缺点是主节点宕机后,需要人工介入手动恢复,造成服务的不可用
哨兵模式
- Sentinel 是一个专门用于监控 Redis 实例的工具,通过 PING 自动检测 Redis 实例的状态,自动进行故障转移,选举新的主节点,保证服务的可用性。
- 优点是实现了自动故障转移,无需人工干预
- 缺点是在发生故障转移时可能会出现数据丢失的情况。
集群模式
- 将数据分散到多个节点上进行存储和管理,降低系统对单主节点的依赖,并且大大提高 Redis 服务的读写性能
- 除了主从和哨兵的功能外,集群模式下不同的 key 放到不同的 Redis 中,每个 Redis 实例负责一部分的槽,可以实现数据分片。
- 优点是可以水平扩展,提高了并发读写的能力
- 缺点是配置较为复杂。
Spring
IoC
IoC 理解
IoC 的思想就是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理,由 Spring 容器(本质上就是个Map)完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。
声明 Bean
@Component:通用的注解,可标注任意类为 Spring 组件。通过类路径扫描来自动侦测以及自动装配到 Spring 容器中@Repository: 对应持久层,主要用于数据库相关操作。@Service: 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。@Controller: 对应控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面@Bean: 作用于方法上,表示方法返回的实例装配到Spring容器中。常用于第三方库的类装配@Configuration:声明配置类
框架启动时,Spring 通过扫描各种注解,把需要交给 Spring 管理的 Bean 初始化为 BeanDefinition 的列表,进而创建 Bean 的实例。
注入 Bean
@Autowired: Spring 内置注解- 默认 byType,根据接口类型去匹配注入接口实现类
- 当一个接口存在多个实现类,转为 byName,即变量名和类名匹配
- 建议
@Qualifier(value = "serviceImpl1")显式指定名称
@Resource:JDK 提供的注解- 默认 byName,否则 byType
- 建议通过 name 属性显式指定名称
@Inject基本不用
Bean 作用域
- singleton:默认,容器中只有唯一实例。
- prototype: 每次获取都会创建一个新实例。
- request(Web):每一次 HTTP 请求都会产生一个新实例,且仅在当前 HTTP 请求内有效。
- session(Web):每一次来自新 session 的 HTTP 请求都会产生一个新实例,且仅在当前 session 内有效。
- application/global-session(Web):每个 Web 应用在启动时创建一个实例,且仅在当前应用启动时间内有效。
- websocket(Web):每一次 WebSocket 会话产生一个新实例
Bean 生命周期
- 实例化:通过反射或者工厂方法创建 Bean 对象。
- 属性注入:通过配置文件或者注解给 Bean 对象的属性赋值。
- 初始化:调用 Bean 对象的初始化方法,比如
@PostConstruct注解的方法,或者实现了InitializingBean接口的afterPropertiesSet方法,或者配置文件中指定的init-method方法。 - 销毁:调用 Bean 对象的销毁方法,比如
@PreDestroy注解的方法,或者实现了DisposableBean接口的destroy方法,或者配置文件中指定的destroy-method方法。
其它扩展点:BeanPostProcessor, BeanFactoryPostProcessor, InstantiationAwareBeanPostProcessor, SmartInstantiationAwareBeanPostProcessor…
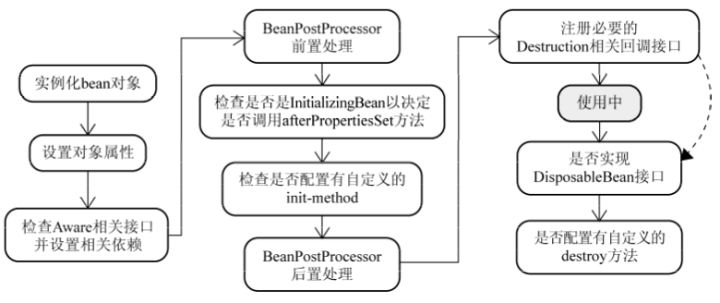
自动装配
Spring 的自动装配通过注解或者一些简单的配置就能在 Spring Boot 的帮助下自动导入一些Bean来实现某些功能。
- 整个SpringBoot项目的启动类都是添加
@SpringBootApplication注解的,这个注解主要包括三个子注解:- @SpringBootConfiguration 表示当前是个配置类
- @ComponentScan 包扫描(并且可以排除一些包/类)
- @EnableAutoConfiguration 自动装配的关键注解
- @EnableAutoConfiguration 分两部分:
- selectImports 方法首先会判断是否开启了自动装配,如果开启的话继续。
- 接着调用 SpringFactoriesLoader::loadMetaData 扫描所有依赖项目的 META-INF 目录下的 spring.factories 文件里,定义的 Key 为 EnableAutoConfiguration 的类的全类名,也就是所有需要装配的 Bean
- 然后调用 getAutoConfigurationEntry 来加载这些 Bean,具体的:
- 判断自动装配是否开启
- 获取 EnableAutoConfiguration 注解中的 exclude 和 excludeName 做一个过滤并且去重,然后返回一个需要加载的 Bean 的结果集
- 然后根据 Bean 上添加的 Conditional 条件注解再做一次过滤
- 最后就可以把这些剩下的 Bean 装入容器了
解决循环依赖
循环依赖就是循环引用,指两个或多个bean互相持有对方,形成一个闭环。分:
- 构造器循环依赖:无法解决
- Setter 循环依赖:
- 对于 Singleton 的 Bean,可以提前暴露一个单例工厂方法,使得其它Bean能够引用到(去掉本身的 @Bean)
- 对于 Prototype 的 Bean,无法解决。spring容器不缓存prototype作用域的bean,因此无法提前暴露一个正在创建中的bean。
原理
Spring 通过三级缓存解决循环依赖:
- 一级缓存:单例池,限制 bean 在 beanFactory 中仅存一份
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); - 二级缓存:早期曝光对象
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16); - 三级缓存:早期曝光对象工厂
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
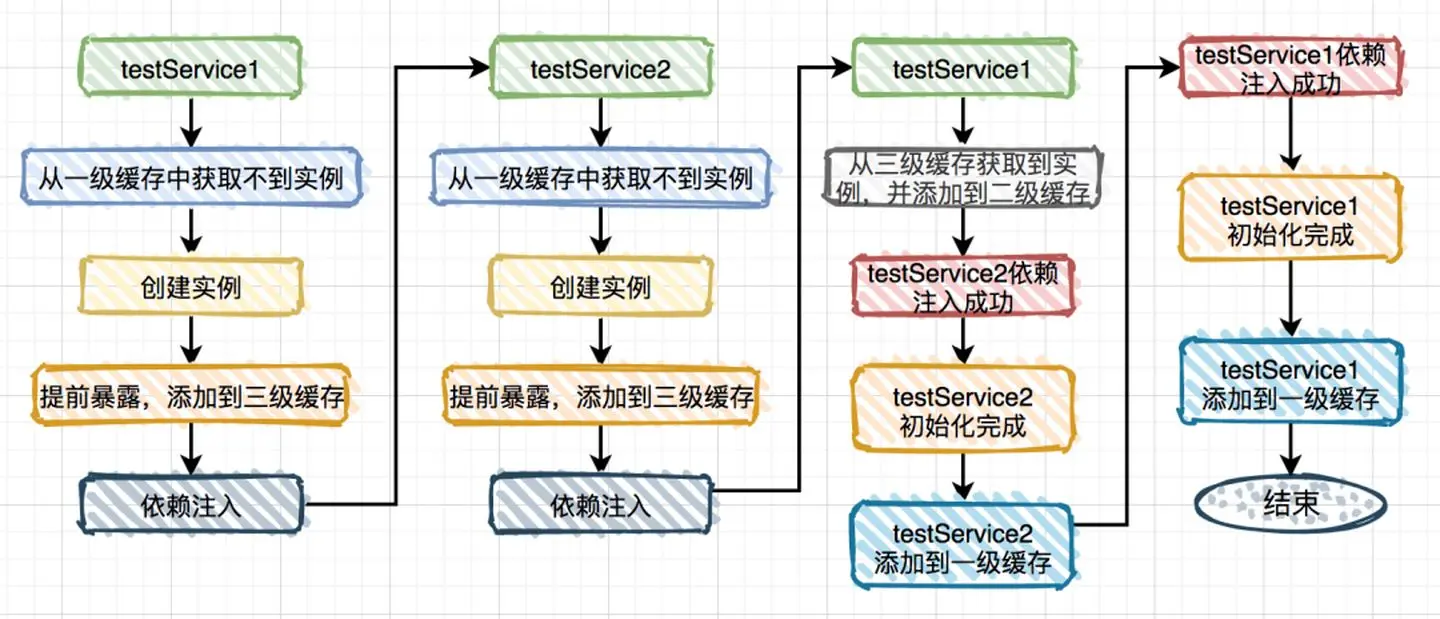
当 A、B 两个类发生循环引用时,在 A 完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果 A 被 AOP 代理,那么通过这个工厂获取到的就是A代理后的对象,如果 A 没有被 AOP 代理,那么这个工厂获取到的就是 A 实例化的对象。当 A 进行属性注入时,会去创建 B,同时 B 又依赖了 A,所以创建 B 的同时又会去调用getBean(a) 来获取需要的依赖,此时的 getBean(a) 会从缓存中获取。
- 首先从一级缓存中获取,但 A 没有填充和初始化完成,因此不存在一级缓存中;接着去二级缓存获取,也不存在;最后去三级缓存获取,可以获取到。
- 第二步,调用对象工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。
- 紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。
至此,循环依赖结束!
为什么不用二级缓存?
如果要使用二级缓存解决循环依赖,意味着所有Bean在实例化后就要完成AOP代理,这样违背了Spring设计的原则,Spring在设计之初就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来在Bean生命周期的最后一步来完成AOP代理,而不是在实例化后就立马进行AOP代理。
AOP
AOP 理解
Spring AOP 就是基于动态代理(如果实现了接口使用基于实现的JDK Proxy,否则使用基于继承的CGLib代理),能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,有利于未来的可拓展性和可维护性。
通知类型
Around::before -> Before -> target::proceed -> Around::after -> AfterReturning / AfterThrowing -> After
MVC
MVC 理解
MVC 是模型(Model)、视图(View)、控制器(Controller)的简写,其核心思想是通过将业务逻辑、数据、显示分离来组织代码。
Spring MVC 下我们一般把后端项目分为:
- Entity层:实体类
- Dao层:操作数据库
- Service层:处理业务
- Controller层:返回数据给前台页面
核心组件和原理
DispatcherServlet:核心的中央处理器,负责接收请求、分发,并给予客户端响应。HandlerMapping:处理器映射器,根据 uri 去匹配查找能处理的 Handler ,并会将请求涉及到的拦截器和 Handler 一起封装。HandlerAdapter:处理器适配器,根据 HandlerMapping 找到的 Handler ,适配执行对应的 Handler;Handler:请求处理器,处理实际请求的处理器。ViewResolver:视图解析器,根据 Handler 返回的逻辑视图/视图,解析并渲染真正的视图,传递给 DispatcherServlet 响应客户端
其它
Spring 启动流程
- 首先从main找到run()方法,在执行run()方法之前new一个SpringApplication对象
- 进入run()方法,创建应用监听器SpringApplicationRunListeners开始监听
- 然后加载SpringBoot配置环境(ConfigurableEnvironment),然后把配置环境(Environment)加入监听对象中
- 然后加载应用上下文(ConfigurableApplicationContext),当做run方法的返回对象
- 最后创建Spring容器,refreshContext(context),实现starter自动化配置和bean的实例化等工作。
常用注解
- @SpringBootApplication: 启动类,是@SpringBootConfiguration, @EnalbeAutoConfiguration, @ComponentScan三个注解的集合
- @Autowired:自动装配,被注入的类要被Spring容器管理
- @Compoent, @Repository, @Service, @Controller:声明 Bean
- @RestController: @Controller + @ResponseBody 的集合,REST风格的控制器,将函数的返回值直接写入HTTP响应体
- @Scope 声明作用域
- @Configuration 声明配置类
- @GetMapping 获取资源,@PostMapping 创建新资源,@PutMapping 更新资源,@DeleteMapping 删除资源
- @PathVariable 获取路径参数,@RequestParam 获取查询参数,@RequestBody 获取请求体参数并自动绑定到Java对象(利用HttpMessageConverter,且一个请求方法中仅能有一个)
- @Value(“${…}”) 读取简单配置信息,[@ConfigurationProperties(prefix ](/ConfigurationProperties(prefix ) = “…”) 读取配置并绑定到 Bean, @PropertySource(“xxx”) 读取指定配置文件
- 参数校验:@Validate 加在Controller上开启校验,具体规则有 @NotEmpty, @NotBlank, @Pattern, @Max, @Size… (加在 Entity 实体类的属性上)
- 全局异常:@ControllerAdvice 定义全局异常处理类,@ExceptionHandler 声明异常处理方法
- JPA 相关:@Entity 实体类,@Table 表名, @Id 声明主键,@GeneratedValue 主键生成策略, @Column 声明字段, @Transient 声明不持久化字段(或用static/final修饰),@Lob 大字段,@Enumerated 枚举类型字段,@@EnableJpaAuditing 开启JPA审计,@Transactional 开启事务
- Json数据处理:@JsonIgnoreProperties 过滤特定字段不返回/不解析,@JsonFormat 格式化Json数据,@JsonUnwrapped 扁平化对象
- 测试相关:@ActiveProfiles 声明生效的Spring配置文件,@Test 测试方法,@WithMockUser 模拟真实用户和权限
SpringBoot 优势
- SpringBoot 依靠大量注解实现自动化配置,只需要添加相应的场景依赖,就可以快速构建出一个独立的 Spring 应用
- 通过自动 starter 依赖,简化了构建配置
- 内嵌服务器使得应用程序可以直接运行,不需要单独部署
- SpringBoot 整合了大量第三方功能,并提供了默认配置,例如 mybatis、redis等,实现开箱即用
- SpringBoot 提供了一些用于生产环境运行时的特性,例如指标、监控检查和外部化配置。
SpringBoot 缺点
- 缺少灵活性,有时需要在项目中扩展一些功能就需要手动配置
- 集成度较高,使用过程中不太容易了解底层;
- 难以适应较为复杂的场景,一旦项目变得复杂,就需要考虑功能的划分和更加细致的配置
事务传播行为
Spring 管理事务有两种方式:编程式(手动硬编码)、声明式(基于@Transactional的AOP)
Propagation_Required: @Transactional 默认模式,如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。Propagation_Requires_New: 总是创建新事务,如果当前存在事务则挂起。开启的事务相互独立,互不干扰Propagation_Nested: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;否则新建事务Propagation_Mandatory: 如果当前存在事务就加入;否则抛出异常
另外还有三种可能不回滚的事务:
Propagation_Supports: 如果当前存在事务就加入;否则以非事务的方式继续运行Propagation_Not_Supported: 以非事务方式运行,如果当前存在事务则把当前事务挂起Propagation_Never: 以非事务方式运行,如果当前存在事务则抛出异常
事务隔离级别
Isolation_Default: 使用后端数据库默认的隔离级别,例如 MySQL 默认 REPEATABLE_READIsolation_Read_Uncommited: 最低级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读Isolation_Read_Commited: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生Isolation_Repeatable_Read: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。Isolation_Serializable: 最高级别,完全服从 ACID,所有事务依次执行,可以防止脏读、不可重复读、幻读等问题,当严重影响性能。
Spring Cache
Spring 支持多种缓存的实现方式,例如 SimpleCache(ConcurrentMap实现), RedisCache, EhCache, CaffeineCache… 有两个核心接口:
org.springframework.cache.Cache:用于定义缓存的各种操作org.springframework.cache.CacheManager:用于管理各个cache缓存组件
原理
- 缓存的自动配置类 CacheAutoConfiguration 向容器中导入了 CacheConfigurationImportSelector
- CacheConfigurationImportSelector 的 selectImports() 导入所有缓存类型的配置类,默认启用 SimpleCacheConfiguration
- SimpleCacheConfiguration 配置类向容器中注入了一个 ConcurrentMapCacheManager 实例
- ConcurrentMapCacheManager 底层创建一个 ConcurrentMapCache 管理缓存
缓存注解
@EnableCaching:用于 SpringBoot 的启动类开启注解功能@CacheConfig:用于对类进行配置,对整个类的缓存进行配置,可用 @Cacheable 取代@Cacheable:通常用于配置方法,将方法的返回结果注入到缓存对象中- value/cacheNames: 指定缓存名(跟在 key-prefix 后面)
- key/keyGenerator:指定缓存对应的 key 值,默认使用方法参数生成,可以使用 spel 指定
- condition/unless: 条件缓存
- sync:默认 false,为 true 时开启同步锁
@CacheEvict:可用于类或方法,用于清空缓存- allEntries: true 表示删除域名下所有缓存
@CachePut:强制执行方法并将返回结果放入缓存,常用于更新 DB 的方法- 属性同 @Cacheable
@Caching: @Cacheable + @CachePut + @CacheEvict
缺陷
- 读缓存:
- 缓存穿透:spring.cache.redis.cache-null-values 指定是否缓存空数据
- 缓存击穿:默认是无加锁的,可以置 Cacheable 的 sync 为 true
- 缓存雪崩:可以设置随机时间
- 写缓存:
- 读写加锁
- 引入 Canal
- 读多写多的场景,可以直接查 DB
总结:
- 常规数据(读多写少,即时性,一致性要求不高的数据,完全可以使用 Spring-Cache
- 写模式(只要缓存的数据有过期时间就足够了)
- 特殊数据进行特殊设计
Spring 单例并发问题
Spring 中的 Bean 默认都是单例的,Spring也没有对 Bean 有线程安全的控制策略,并发安全问题由开发决定。单例 Bean 的并发安全取决于 Bean 是有状态还是无状态,即是否有数据存储功能,例如 User 里面存储了用户数据。因此不应把有状态的 Bean 定义成单例 Bean。要么使用 prototype 作用域,要么使用本地变量 ThreadLocal。
JPA 取消持久化
static String transient1; // not persistent because of static
final String transient2 = "Satish"; // not persistent because of final
transient String transient3; // not persistent because of transient
@Transient
String transient4; // not persistent because of @Transient
分布式
概念
- 分布式:把整个系统拆分成不同的服务,部署在不同的服务器/集群上减轻单体服务的压力,提高并发量和性能,提高开发效率,便于维护和扩展。
- 注册中心:负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互。
- 监控中心:负责统计各服务调用次数,调用时间等。
- 负载均衡:改善跨多个计算资源的工作负载分布,来优化资源使用,最大化吞吐量,最小化响应时间,并避免任何单个资源的过载。
CAP 和 BASE
CAP 理论
对于一个分布式系统,在满足 P 的前提下,只能满足 AP(如ZooKeeper)或 CP(Eureka):
- Consistency: 一致性,所有节点访问同一份最新的数据副本
- Availability:可用性,非故障的节点在合理的时间内返回合理的响应
- Partition Tolerance:分区容错性,出现网络分区时仍能对外提供服务
原因:若系统出现分区,系统中的某个节点在进行写操作。为了保证 C 一致性, 必须要禁止其他节点的读写操作,这就和 A 可用性发生冲突了。如果为了保证 A 可用性,其他节点的读写操作正常的话,那就和 C 一致性发生冲突了。如果不需要保证 P,即网络分区正常,那么 C 一致性和 A 可用性可以同时保证。
BASE 理论
BASE 理论核心思想是:即使无法做到强一致性,也应采用适当的方式来使系统达到最终一致性。
- Basically-Available: 基本可用,系统在出现不可预知故障的时候,允许损失部分可用性(响应时间上的损失/系统功能上的损失)
- Soft-state:软状态,允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性(允许不同节点的副本同步过程存在延迟)
- Eventually-Consistent:最终一致性,系统中所有的数据副本经过一段时间的同步后,最终达到一致。
BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
Paxos
共识算法:通过保持复制日志的一致性,即使面对故障,服务器也可以在共享状态上达成一致。
Paxos 算法是第一个被证明完备的分布式系统共识算法。共识算法的作用是让分布式系统中的多个节点之间对某个提案(Proposal)达成一致的看法。例如哪个节点是 Leader、多个事件发生的顺序等。
Paxos 主要包含两个部分:
1. Basic Paxos
多节点间如何就某个值(提案)达成共识
- Proposer:也称 Coordinator,负责接受客户端的请求并发起提案(提案编号、提议值)
- Acceptor:也称 Voter,负责对提议者的提案进行投票,同时需要记住自己的投票历史
- Learner:如果有超过半数接受者就某个提议达成了共识,那么学习者就需要接受这个提议,并就该提议作出运算,然后将运算结果返回给客户端。
2. Multi Paxos
一种思想,通过执行多个 Basic Paxos,就一系列值达成共识。
针对存在恶意节点的情况(拜占庭问题),一般使用 PoW 工作量证明、PoS 权益证明 等公式算法。
Raft
节点类型
一个 Raft 集群包括若干服务器,任何时间点,任意服务器一定会处于以下三个状态中的一个:
- Leader: 负责发起心跳,响应客户端,创建日志,同步日志
- Candidate: Leader 选举过程中的临时角色,由 Follower 转化而来,发起投票参与竞选
- Follower: 接受 Leader 的心跳和日志同步数据,投票给 Candidate
在正常的情况下,只有一个服务器是 Leader,剩下的服务器是 Follower。Follower 是被动的,不会发送任何请求,只是响应来自 Leader 和 Candidate 的请求。
选举
任期:Raft 算法将时间划分为任意长度的任期(Redis 中的选举轮次),用连续的数字表示。每个任期都以一次选举开始。
Raft 使用心跳机制来触发 Leader 的选举。
- Leader 通过心跳保持 Leader 状态
- Follower 通过心跳保持为 Follower 状态,并确认 Leader
- 如果 Follower 在一个周期内没收到心跳,将开始一次选举
- 自增自己的 term 并转换为 Candidate,向其他节点请求投票
- 如果超过半数节点投票给自己,则成为 Leader
- 期间,如果收到其它节点声明 Leader 的心跳,且 term 号大于等于自己的 term,则退回 Follower,否则拒绝该请求并让该节点更新
- 如果选举失败,随机一个新的超时时间,之后重新选举
日志复制
- Entry:
<term, index, cmd>的结构,每一个事件成为 entry,只有 Leader 可以创建 entry。 - Log:有 Entry 构成的数组,只有 Leader 才可以改变其他节点的 log。
Leader 收到客户端请求后,会生成一个 entry,添加到自己的日志末尾,并广播给其它服务器,如果收到超过半数的成功响应,标记这个 entry 是 committed 的。Leader 通过强制 Follower 复制自己的日志来处理日志的不一致。
API 网关
主要功能:请求转发、请求过滤
基于这两个功能,继而实现 安全认证、流量控制、日志、监控…
常见网关:Netflix Zuul, Spring Cloud Gateway, Kong, APISIX, Shenyu…
分布式 ID
在分布式系统中,不同的数据节点要为数据生成全局唯一主键,也即分布式ID,需要满足:
- 全局唯一
- 高性能
- 高可用
- 方便易用
除此之外,还应保证安全、有序递增、有具体业务含义、独立部署
常见解决方案
- 数据库主键自增:实现简单,但很多缺点
- 数据库号段模式:批量获取 ID,存入内存,需要时取用。
- NoSQL:例如利用 Redis Cluster实现 id 原子递增
- UUID 算法:基于 MAC 地址、时间戳、命名空间、随机数等信息生成唯一 ID。但占用存储空间过大,且无序,影响DB性能
- Snowflake 算法:雪花算法,灵活有序。但如果机器时间不正确可能产生重复ID。
开源方案例如 百度的 UidGenerator,美团的 Leaf,滴滴的 Tinyid
RPC
RPC,Remote Procedure Call 远程过程调用,通过网络编程实现不同服务器上的方法调用。
核心功能的实现由以下五个部分实现:
- 客户端(服务消费端):调用远程方法的一端
- 客户端 Stub(桩): 本质上是代理类,把调用的类、方法、参数等信息传递到服务端(序列化/反序列化 + 接收/发送)
- 网络传输: 将调用信息传输到服务端,服务端执行完后通过网络把结果再传输回来。实现方式比如最基本的 Socket、性能以及封装更优秀的 Netty
- 服务端 Stub(桩):指接收到客户端执行请求后,调用处理器然后返回结果给客户端的类(序列化/反序列化 + 接收/发送)
- 服务端(服务提供端):提供远程方法的一端
HTTP 和 RPC
纯裸 TCP 是能收发数据,但它是个无边界的数据流,上层需要定义消息格式用于定义消息边界。于是就有了各种协议,HTTP 和各类 RPC 协议就是在 TCP 之上定义的应用层协议。RPC本质上是一种调用方式,具体的实现 gRPC/Thrift 才是协议,目的是希望程序员能像调用本地方法那样去调用远端的服务方法。RPC也不一定非得基于TCP。
区别:
- 服务发现:RPC一般有专门的中间服务保存服务名和IP信息(HTTP当然也能实现)
- 底层连接形式:RPC使用连接池
- 传输内容:HTTP报文非常冗余,而RPC定制化程度高,性能也更好。是内部网络使用RPC的主要原因
当然HTTP/2通过压缩做了很多改进,甚至优于RPC,但由于历史原因,RPC仍在使用。
消息队列
基本概念
中间件:一类提供系统软件和应用软件之间连接、便于软件各部件之间的沟通的软件,应用软件可以借助中间件在不同的技术架构之间共享信息与资源。
消息队列:存放消息的容器,FIFO 按序消费。参与消息传递的双方称为 生产者 和 消费者,生产者负责发送消息,消费者负责处理消息。
优点
- 异步处理,提高系统性能,减少响应时间
- 削峰/限流
- 降低系统耦合性
缺点
- 系统可用性降低:例如消息丢失,MQ宕机等问题
- 系统复杂性提高:需要保证无重复消费、消息丢失、消息传递顺序性等问题
- 一致性问题:消费者没有正确消费消息的情况
JMS
Java Message Service Java消息服务的一套 API 规范。例如 ActiveMQ
- 消息格式:StreamMessage, MapMessage, TextMessage, ObjectMessage, BytesMessage
- 消息模型:P2P 点对点、PubSub 订阅模型
AMQP
Advanced Message Queuing Protocol 高级消息队列协议,应用层面向消息的中间件开发标准协议,支持跨平台、跨语言,兼容 JMS。例如 RabbitMQ
- 仅支持 byte[] 消息类型
- 基于 Exchange 提供的路由算法,提供多种消息模型,例如 direct exchange, fanout exchange, topic change, headers exchange, system exchange
常见 MQ
Kafka、RocketMQ、RabbitMQ、Pulsar
Kafka
Kafka 是一个分布式流式处理平台,用作消息队列和数据处理。有三个关键功能:
- 消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
- 容错的持久方式存储记录消息流: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险。
- 流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
优点:极致的性能、生态兼容性
消息模型
- 队列模型
- PubSub 发布订阅模型:使用 Topic 作为消息通信载体,广播给订阅者
概念模型
- Consumer
- Producer
- Broker:代理,一个独立的 Kafka 实例,多个 Broker 组成 Cluster
- Topic:主题,Producer 发送消息到特定主题,Consumer 订阅特定主题的消息
- Partition: Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker
RabbitMQ
概念
RabbitMQ 是使用 Erlang 语言实现的 AMQP 消息中间件,整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。
消息
- 消息头:一系列可选属性,也叫标签。例如 routing-key 路由键, priority 优先权,delivery-mode 持久性存储…
- 消息体:payload
Exchange 交换机
RabbitMQ 中消息必须先经过 Exchange,再根据路由规则分配到对应的 Queue。如果路由不到,可能返回给 Producer 或直接丢弃。
RabbitMQ 通过 Binding 将 Exchange 和 Queue 绑定关联,并指定一个 BindingKey 作为路由规则。Producer 发送消息时需要指定 RoutingKey,与 BindingKey 匹配时就会路由到对应的消息队列中。多个队列绑定到同一个 Exchange 可以使用相同的 BindingKey,具体路由还依赖于交换器类型。
分四种类型:
- direct:把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。常用于处理有优先级的任务
- fanout:把发送到该 Exchange 的消息路由到所有与它绑定的 Queue 中,不需要任何判断,因此速度最快
- topic:将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,例如 * 匹配一个单词,# 匹配零/多个单词
- headers:路由规则不依赖于路由键的匹配规则,而是根据发送的消息内容中的 headers 属性进行匹配,完全匹配才会路由
因此,RabbitMQ 工作模式有 简单模式、work 工作模式、PubSub 模式、Routing 路由模式、Topic 主题模式
Queue 消息队列
Queue 用来保存消息,直到发送给消费者,一个消息可以投入一个或多个队列。
多个消费者可以订阅同一个队列,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免消息被重复消费。
Broker 服务节点
一个 RabbitMQ 实例可以看作一个 Broker。
常见问题
- 死信队列
Dead-Letter-Exchange 私信交换机/死信队列,当消息在一个队列中变成死信(dead message)之后,它能重新被发送到另一个交换器中,这个交换器就是 DLX,绑定 DLX 的队列就称之为死信队列。
导致死信的原因:
- 消息被拒(Basic.Reject/Basic.Nack)且 requeue = false
- 消息 TTL 过期
- 队列满了无法添加
- 延迟队列
RabbitMQ 本身不支持延迟队列,但又两种实现方式:
- 利用死信交换机和消息的存活时间 TTL 模拟延迟
- 插件 rabbitmq-delayed-message-exchange
- 优先级队列
可以通过 x-max-priority 参数实现优先级队列。不过,当消费速度大于生产速度且 Broker 没有堆积的情况下,优先级显得没有意义。
- 消息传输
RabbitMQ 使用信道 Channel 来传输数据,信道是建立在 TCP 连接上的虚拟连接,一条 TCP 连接上可以有上千条信道复用,每条信道都有唯一ID,并且对应一个线程使用。
- 保证消息可靠性
- Producer 到 RabbitMQ:事务机制 或 Confirm 机制
- RabbitMQ 中:持久化、集群、普通模式、镜像模式
- RabbitMQ 到 Consumer:basicAck 机制、死信队列、消息补偿机制
- 保证消息顺序性
- 拆分多个 Queue,每个 Queue 一个消费者
- Consumer 内部用队列排队,分发给底层不同的 worker 处理
- 保证高可用
RabbitMQ 基于主从做高可用,有三种模式:
- 单机模式:生产环境不用
- 普通集群:多台机器启动多个 RabbitMQ 实例,创建的 Queue 只放在一个实例上,实例之间同步 Queue 的元数据,以找到 Queue 所在的实例
- 镜像集群:创建 Queue 存在于多个实例上,每次写消息到 Quee 都会同步到所有实例。缺点就是性能开销大,网络压力重
开发工具
Linux
# 显示当前系统正在执行的进程的相关信息,包括进程ID、内存占用率、CPU占用率等
top -p <进程号> -u <用户名>
ps -ef
# 向进程发送信号,例如 -9 SIGKILL
kill -9 pid
# 启动/停止/重启/重新加载配置 一个Unit服务
systemctl start | stop | restart | reload
free # 可用内存和已使用情况
vmstat # 虚拟内存统计
df # 文件系统磁盘空间占用
iostat # IO 统计
ifstat # 统计网络接口流量状态
# 递归修改文件权限
chmod -R 777 dir
# 查看网络配合和收发数据包的统计信息
ifconfig/ip
# 查看 socket、网络协议栈、网口、路由表信息
ss/netstat
# 查看当前网络的吞吐率和 PPS
sar
# secure copy 远程安全拷贝
scp local_file remote_username@remote_ip:remote_file
# 统计行数
wc -l file
# 日志处理 (awk 处理文本 -> 排序 -> 去重统计 -> 统计结果逆序 -> top 3)
awk '{print substr($4, 2, 11)}' access.log | sort | uniq -c | sort -rn | head -n 3
# 以 6 个线程,3 万个连接,持续 60s 对目标进行压测
wrk -t 6 -c 30000 -d 60s http://xxx:8080
Maven
作用
- 项目构建:提供标准的、跨平台的自动化项目构建方式。
- 依赖管理:方便快捷的管理项目依赖的资源(jar 包),避免资源间的版本冲突问题。
- 统一开发结构:提供标准的、统一的项目结构。
坐标
- groupId:项目隶属的组织或公司
- artifactId:项目的名称
- version
- 其它可选:packaging(jar/war/…)、classifier
依赖范围
三套不同的classpath:
- 编译 classpath :编译主代码有效
- 测试 classpath :编译、运行测试代码有效
- 运行 classpath :项目运行时有效
不同的依赖范围:
- compile:默认,对编译、测试、运行都有效
- provided:对编译、测试有效,如Servlet
- test:仅用于测试,如JUnit
- runtime:仅用于运行,如JDBC Driver
- system:必须通过systemPath指定,不依赖Maven
依赖冲突
遵循 路径最短优先 -> 声明顺序优先 两大原则。
<exception> 手动排除依赖
Maven 仓库
除了本地仓库,远程仓库分三类:
- 中央仓库:Maven 社区维护
- 私服:设在局域网内的仓库服务
- 其它公共仓库:用于加速访问,或部分构件不存在于中央仓库
依赖查找顺序:本地仓库 -> 远程仓库 -> 报错
生命周期
- default
- clean
- site
每个生命周期里包含多个阶段,阶段间前后依赖,当执行某个阶段的时候,会先执行它前面的阶段。
多模块管理
- 降低代码之间的耦合性(从类级别的耦合提升到 jar 包级别的耦合)
- 减少重复,提升复用性
- 每个模块都可以是自解释的(通过模块名或者模块文档)
- 模块还规范了代码边界的划分,开发者很容易通过模块确定自己所负责的内容
Git
Git 不同与其它版本控制记录文件修改的增量,而是直接保存修改文件的快照。
文件三种状态
- 已提交(committed):数据已经安全的保存在本地数据库中。
- 已修改(modified):已修改表示修改了文件,但还没保存到数据库中。
- 已暂存(staged):表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
由此引出三个工作区:工作目录、暂存区、Git 仓库
常用命令
# 添加远程地址
git remote add origin <server>
# 贮藏修改到栈上
git stash
# 应用贮藏的修改
git stash apply
merge 和 rebase 区别
- merge 合并分支会新增一个merge commit,然后将两个分支的历史联系起来。对现有分支不会以任何方式被更改,但是会导致历史记录相对复杂
- rebase 找到两个分支最近的共同祖先,将整个分支移动到另一个分支上,修改各自的冲突,整合所有分支上的提交。好处是历史记录更加清晰,是在原有提交的基础上将差异内容反映进去,消除了 git merge所需的不必要的合并提交
Docker
优势
Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。
- 一致的运行环境,能够更轻松地迁移
- 对进程进行封装隔离,容器与容器之间互不影响,更高效地利用系统资源
- 可以通过镜像复制多个一致的容器
重要概念
- 镜像:一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数
- 容器:镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等,每个容器相互隔离
- 仓库:集中存放镜像文件的地方
容器
- 容器镜像是轻量的、可执行的独立软件包 ,包含软件运行所需的所有内容:代码、运行时环境、系统工具、系统库和设置。
- 容器化软件适用于不同OS的应用,在任何环境中都能够始终如一地运行。
- 容器赋予了软件独立性,使其免受外在环境差异的影响
对比虚拟机
- 容器是一个应用层抽象,用于将代码和依赖资源打包在一起。多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行。容器占用空间少,启动快
- 虚拟机 (VM) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。
常用命令
docker version # 查看docker版本
docker images # 查看所有已下载镜像,等价于:docker image ls 命令
docker container ls # 查看所有容器
docker ps #查看正在运行的容器
docker image prune # 清理临时的、没有被使用的镜像文件。-a, --all: 删除所有没有用的镜像,而不仅仅是临时文件;
docker search mysql # 查看mysql相关镜像
docker pull mysql:5.7 # 拉取mysql镜像
docker image ls # 查看所有已下载镜像
docker rmi xxx # 删除镜像
docker rm xxx # 删除容器
docker start xxx
docker restart xxx
docker stop xxx
docker kill xxx
docker udpate --restart=always xxx # 设置容器自启动
docker logs -ft xxx # 实时显示日志,并打印时间戳
docker top xxx # 容器内运行了哪些进程
docker exec -it xxx bash # 与容器交互
docker cp file xxx:dir # 将文件从宿主机拷贝到容器指定位置,反之也可以
docker inspect xxx # 查看容器/数据卷细节
docker run -v volume:dir # 将volume/宿主机目录 映射到 容器内的dir
docker commit -m "描述信息" -a "镜像作者" tomcat01 my_tomcat:1.0 # 打包镜像
docker save my_tomcat:1.0 -o my-tomcat-1.0.tar # 备份镜像
docker load -i my-tomcat-1.0.tar # 加载本地镜像
系统设计
熔断降级
熔断
A 服务调用 B 服务的某个功能,由于网络不稳定问题,或者 B 服务卡机,导致功能时间超长。如果这样子的次数太多。我们就可以直接将 B 断路了(A 不再请求 B 接口),凡是调用 B 的直接返回降级数据,不必等待 B 的超长执行。 这样 B 的故障问题,就不会级联影响到 A。
降级
整个网站处于流量高峰期,服务器压力剧增,根据当前业务情况及流量,对一些服务和页面进行有策略的降级(停止服务,所有的调用直接返回降级数据)。以此缓解服务器资源的的压力,以保证核心业务的正常运行,同时也保持了客户和大部分客户的得到正确的相应。
相同点
- 为了保证集群大部分服务的可用性和可靠性,防止崩溃,牺牲一部分服务
- 用户最终都是体验到某个功能不可用
不同点、
- 熔断是被调用方故障,触发系统主动规则
- 降级是基于全局考虑,手动停止一些正常服务,释放资源
服务限流
限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。
固定窗口计数器
- 即时间窗口,规定了单位时间内处理的请求数量。
- 例如用 counter 计数请求,超过阈值后拒绝请求,等时间到了重置
- 这种限流算法无法保证限流速率,因而无法保证突然激增的流量。例如一分钟内的前55s没有请求,后1s突然有1000个请求,系统直接被击垮
滑动窗口计数器
- 在固定窗口计数器基础上,把时间以一定比例分片,对窗口内请求数计数。
- 分片越细,窗口滚动越平滑,限流也就越精确
漏桶算法
- 类似漏桶漏水,任意速率流入,固定速率流出
- 可以使用队列保存请求,定期从队列中取出请求执行
令牌桶算法
- 以一定速率网桶里添加令牌,桶满就不再添加
- 请求在处理前需要拿到一个令牌,处理完毕后将令牌丢弃
高可用
描述一个系统在大部分时间都是可用的,即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。
系统不可用原因
- 黑客攻击
- 硬件故障
- 并发量/用户请求量激增
- 代码中的坏味道导致内存泄漏或者其他问题,进而引发程序崩溃
- 网站架构中的某个组件宕机
- 自然灾害、人为破坏
- …
提高方法
- 集群,避免单点故障
- 限流,避免瞬时流量高峰冲垮系统
- 超时和重试机制
- 熔断,系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。
- 异步调用,或配合消息队列
- 缓存机制
冗余设计
- 高可用集群:同一份服务部署两份或者多份,以便故障时快速切换
- 同城/异地灾备,备用服务不处理请求
- 同城/异地多活,备用服务也处理请求
性能测试
- 性能测试:通过测试工具模拟用户请求系统,目的主要是为了测试系统的性能是否满足要求
- 负载测试:对被测试的系统继续加大请求压力,直到服务器的某个资源已经达到饱和,达到系统上限
- 压力测试:不去管系统资源的使用情况,对系统继续加大请求压力,直到服务器崩溃无法再继续提供服务
- 稳定性测试:模拟真实场景,给系统一定压力,看看业务是否能稳定运行
RestFul
Resource Representational State Transfer “资源”在网络传输中以某种“表现形式”进行“状态转移”。
- 资源:特定 URI 对应的对象数据
- 表现形式:资源具体的呈现形式,如JSON、XML、Image等
- 状态转移:通过CRUD,使得服务器端资源状态的改变
动作
- GET:请求获取特定资源
- POST:创建新资源
- PUT:更新资源
- DELETE:删除资源
- PATCH:部分更新
软件工程
瀑布模型
软件概念 -> 需求分析 -> 架构设计 -> 详细设计 -> 编码 -> 测试
敏捷开发模型
一种以人为核心、迭代、循序渐进的开发方法。在敏捷开发中,软件项目的构建被切分成多个子项目,各个子项目的成果都经过测试,具备集成和可运行的特征。换言之,就是把一个大项目分为多个相互联系,但也可独立运行的小项目,并分别完成,在此过程中软件一直处于可使用状态。
开发策略
软件复用、分而治之、逐步演进、优化折中
认证授权
- 认证:验证身份凭据
- 授权:管理操作权限
RBAC 模型:Role-Based Access Control 基于角色的权限访问控制,权限与角色相关联,用户通过成为适当角色的成员而得到这些角色的权限。
Cookie 和 Session
Cookie:保存在客户端(浏览器),一般用来保存用户信息。(例如存放 SessionId 用于服务器标记用户)
Session:保存在服务端,记录用户的状态。(HTTP是无状态的,需要Session标记并跟踪特定用户)
- 一般 Session 的安全性更高,Cookie尽量加密放到服务端解密。
- Session 一般依赖于 Cookie 实现。,但也可以不用 Cookie,例如直接放在 url 中,但安全性和用户体验降低。
- Cookie 无法防止 CSRF 跨站请求伪造(以用户身份发送虚假请求),但 Token 令牌可以禁止(Token 保存在 localStorage 中,前端负责携带 Token)
- Cookie 和 Token 都无法阻止 XSS 跨站脚本攻击(注入恶意代码,通过脚本盗用信息)
SSO
Single Sign On 单点登录,在多个应用的系统中,只需要登陆一次,就可以访问其它相互信任的应用系统。对于同域下的不同服务,只要扩大 Cookie 作用域到顶域,然后共享 session 即可(Redis 统一存储 Session)。但对于不同域下的服务,需要单独部署 SSO 系统,只要登录了这个公共的登陆服务就代表对应的服务群都登录了。
跨域 SSO
- 用户访问 app1 系统,app1 没有登录,跳转到SSO
- SSO 也没有登录,弹出用户登录页
- 用户填写用户名、密码,SSO 进行认证后,将登录状态写入 SSO 的 session,并通知浏览器中写入 SSO 域下的 Cookie
- SSO 登录完成后会生成一个 ST (Service Ticket),携带并跳转到 app1 系统
- app1 拿到 ST 后,向 SSO 发送请求验证 ST 是否有效
- 验证通过后,app1 将登录状态写入 Session 并设置 app1 域下的 Cookie
访问 App2
- 用户访问 app2 系统,app2 没有登录,跳转到SSO
- 由于 SSO 已经登录了,不需要重新登录认证
- SSO 生成 ST,携带并跳转到 app2 系统
- app2 拿到 ST 后,向 SSO 发送请求验证 ST 是否有效
- 验证成功后,app2 将登录状态写入 Session 并设置 app2 域下的 Cookie
设计模式
单例
确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
// 懒汉
public class Singleton {
private static Singleton instance;
private Singleton (){}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}
// 饿汉
public class Singleton {
private static Singleton instance = new Singleton();
private Singleton (){}
public static Singleton getInstance() {
return instance;
}
}
// 双重校验锁
public class Singleton {
// 实例化对象分三个步骤:分配内存对象 -> 初始化对象 -> 将对象指向刚分配的内存空间
// Volatile 禁止指令重排序,防止另一个线程访问一个初始化未完成的对象(2、3步重排序)
private volatile static Singleton singleton;
private Singleton (){}
public static Singleton getSingleton() {
if (singleton == null) {
// 只有第一次初始化才需要加锁,后续不需要
synchronized (Singleton.class) {
// 如果多个线程同时通过了第一次检查,防止第二个进入临界区的线程再次创建对象
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
}
工厂模式
通过定义工厂类来创建对象,让使用者不用知道具体的参数就可以创建出所需的产品类。
适配器模式
解决两个软件实体间的接口不兼容的问题
策略模式
相同的目标,用不同的方法实现。例如 Spring 中加载 BeanDefinition 可以从类路径加载、文件系统加载、网络资源加载,可以通过不同的类,实现共同的接口来实现。
代理模式
一个类代表另一个类的功能。在代理模式中,我们创建具有现有对象的对象,以便向外界提供功能接口。
手撕算法
LRU
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
堆排
class Solution {
public void heapSort(int[] nums) {
int heapSize = nums.length;
buildHeap(nums, heapSize);
for(int i = nums.length - 1; i >= 0; i--) {
System.out.print(nums[0] + " ");
swap(nums, 0, i);
--heapSize;
heapify(nums, 0, heapSize);
}
}
void buildHeap(int[] nums, int heapSize) {
for (int i = heapSize / 2; i >= 0; i--)
heapify(nums, i, heapSize);
}
void heapify(int[] nums, int i, int heapSize) {
int l = 2 * i + 1, r = 2 * i + 2;
int maxIdx = i;
if(l < heapSize && nums[maxIdx] < nums[l])
maxIdx = l;
if(r < heapSize && nums[maxIdx] < nums[r])
maxIdx = r;
if(maxIdx != i){
swap(nums, i, maxIdx);
heapify(nums, maxIdx, heapSize);
}
}
void swap(int[] nums, int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}
快排
class Solution {
private static Random rand = new Random(System.currentTimeMillis());
public int[] sortArray(int[] nums) {
quickSort(nums, 0, nums.length - 1);
return nums;
}
private void quickSort(int[] nums, int left, int right) {
if(left >= right)
return;
int r = rand.nextInt(right - left + 1);
swap(nums, left, left + r);
int pivot = left;
int lt = left + 1, gt = right;
while(true) {
while(lt <= right && nums[lt] < nums[pivot]) lt++;
while(gt >= left && nums[gt] > nums[pivot]) gt--;
if(lt >= gt) break;
swap(nums, lt++ ,gt--);
}
swap(nums, pivot, gt);
quickSort(nums, left, gt - 1);
quickSort(nums, gt + 1, right);
}
private void swap(int[] nums, int i, int j) {
int tmp = nums[i];
nums[i] = nums[j];
nums[j] = tmp;
}
}
归并排序
class Solution {
int[] tmp;
public int[] sortArray(int[] nums) {
tmp = new int[nums.length];
mergeSort(nums, 0, nums.length - 1);
return nums;
}
public void mergeSort(int[] nums, int l, int r) {
if (l >= r) {
return;
}
int mid = (l + r) >> 1;
mergeSort(nums, l, mid);
mergeSort(nums, mid + 1, r);
int i = l, j = mid + 1;
int cnt = 0;
while (i <= mid && j <= r) {
if (nums[i] <= nums[j]) {
tmp[cnt++] = nums[i++];
} else {
tmp[cnt++] = nums[j++];
}
}
while (i <= mid) {
tmp[cnt++] = nums[i++];
}
while (j <= r) {
tmp[cnt++] = nums[j++];
}
for (int k = 0; k < r - l + 1; ++k) {
nums[k + l] = tmp[k];
}
}
}
背包
0-1背包
// 前 i 件商品,总重量 j 的前提下的最大价值
dp[i][j] = Math.max(dp[i - 1][j], dp[i - 1][j - w[i]] + v[i])
完全背包
// 前 i 种硬币(可重复),总金额 j 的组合方式
dp[i][j] = dp[i - 1][j] + dp[i][j - coins[i - 1]]
斐波那契
不要写递归!!!复杂度 $O(2^n)$!!!
写 DP,复杂度 O(n)
二分细节
- while(l < r)
- 如果更新时 l = mid + 1 和 r = mid; 则 mid = left + (right - left + 1) / 2;
- 如果更新时 l = mid 和 r = mid - 1; 则 mid = left + (right - left + 1) / 2;
- 返回时优先取 r,避免越界
二分的本质是「二段性」而非「单调性」
二分不仅适用于 01 特性(满足/不满足),还适用于** 一定满足/不一定满足** 这样的特性
场景题
40亿 bit ~= 500 MB;1亿整数 ~= 400 MB
- 两个文件分别有 50亿 URL,找出其中相同的 URL
先哈希切分多个小文件,对每个文件建立 HashSet,查找相同的 URL;优化:前缀字典树,降低存储成本提高查询效率
- 大量数据找出 Top 100 频度的字符串
分而治之,哈希取余 -> HashMap 统计频度 -> 容量 K 的小顶堆求 Top K
- 大量数据中找出不重复的数字
分治法:切分小文件 -> Hashset/HashMap 找出每个小文件不重复的整数 -> 合并每个子结果
位图法:用两位 bit 表示数字状态,00没出现,01出现一次,10出现多次。前提是内存可以容纳所有 bit
- 大量数据中判断一个数是否存在
分治法:/
位图法:每个存在的整数对应的 bit 置 1,然后直接查询该数对应位是否为 1。
- 5亿个数中找出中位数
双堆法:一个大根堆,一个小根堆。大根堆的最大元素小于小根堆的最小元素,保证两个堆的元素个数不超过 1。如果数据总数为偶数,中位数就是两个堆顶的平均值,否则是容量较大的堆的堆顶元素。
分治法: 先遍历一轮,二进制最高位为 1 的写入 file1,否则写入 file0,则中位数位于数量较多的文件中。继续按 位 划分,直到可以定位到中位数。
- Redis 数据结构的应用
ZSet 可以用于实现排行榜数据,例如根据某个权重排序,获得排名顺序。
Set 可以用于集合的交集、并集计算等。例如计算每日新增用户数,用两天的用户 set 作差(sdiffstore命令)
Bitmap 不记录数据本身,只能判断是否存在,可以用于每月的签到记录的场景。
评论加载中。如果这里长期空白,请检查 giscus.app / GitHub 是否可访问。