Zookeeper 学习笔记
基本介绍 概念 ZooKeeper 是一种分布式协调服务,用于管理大型主机,目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。在分布式环境中协调和管理服务是一个复杂的
基本介绍
概念
ZooKeeper 是一种分布式协调服务,用于管理大型主机,目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper 通过其简单的架构和 API 解决了这个问题。ZooKeeper 允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
应用场景
分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
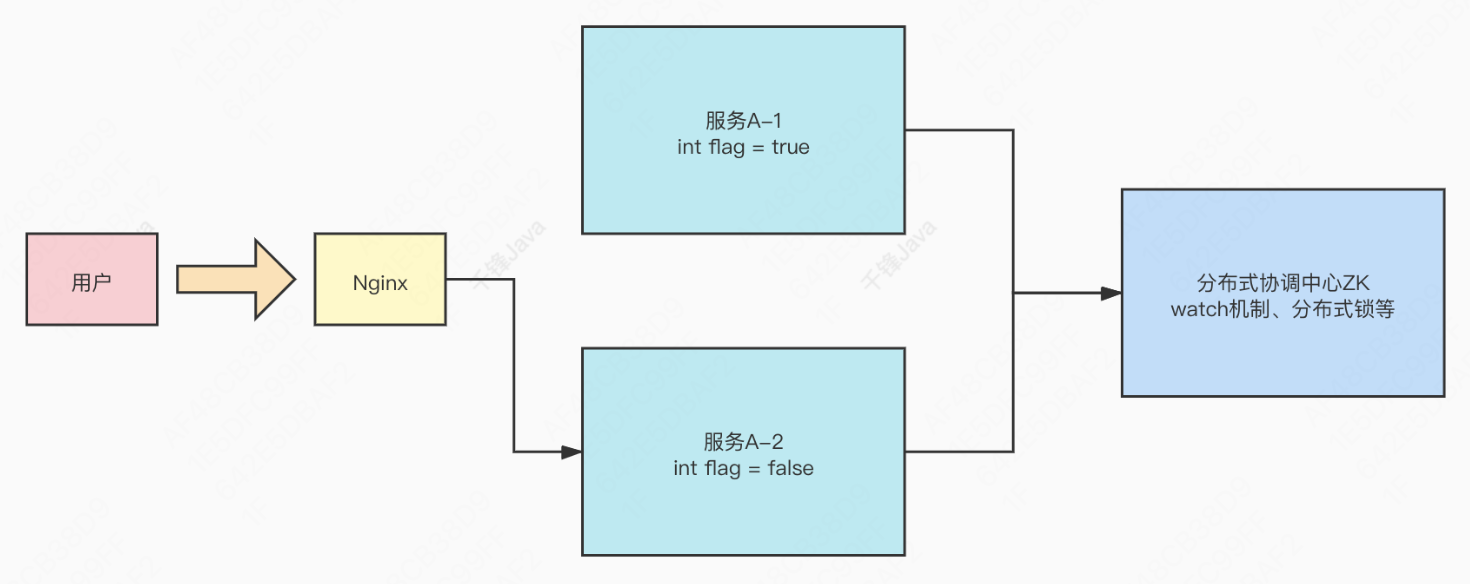
- 分布式协调组件 Zookeeper 在分布式系统中作为协调组件,协调各个服务的状态。包括统一命名服务(注册中心)、统一配置管理(配置中心)、统一集群管理、软负载均衡等等。
-
分布式锁 Zookeeper 在实现分布式锁上,可以做到强一致性。相比于 Redis 实现分布式锁,性能较低但安全性较高。Redis 集群在 master 发生故障时,主从切换时是异步复制的,可能导致数据丢失,无法保证分布式锁的绝对安全。
-
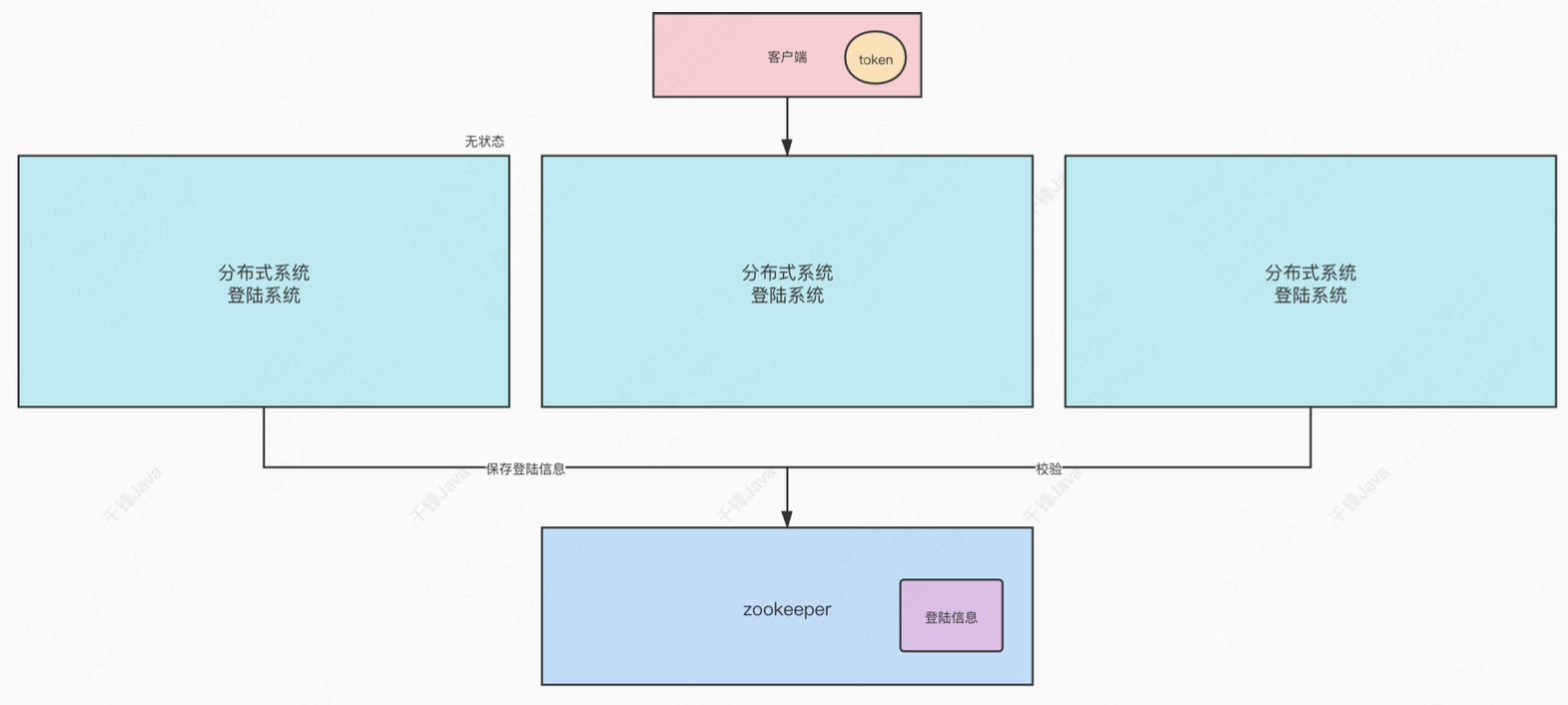
实现无状态化 类似于分布式 Session,存储多个服务公用的信息,以前放在 Redis 中,也可以放到 Zookeeper 中。
安装搭建
配置文件
conf/zoo.cfg
# zookeeper时间配置中的基本单位 (毫秒),也是发送心跳的时间间隔
tickTime=2000
# follower初始化连接到leader最大时限,单位是tickTime
initLimit=10
# follower与leader数据同步最大时限,单位是tickTime
syncLimit=5
# 数据文件及持久化目录
dataDir=/tmp/zookeeper
# 对客户端提供的端口号
clientPort=2181
# 单个zk节点的最大连接数
maxClientCnxns=60
# 保存的数据快照数量,多余的将会被清除
autopurge.snapRetainCount=3
# 自动触发清除任务时间间隔,单位是小时。默认为0,表示不自动清除。
autopurge.purgeInterval=1
# 内嵌的管理控制台端口,默认8080建议更换
admin.serverPort=8081
操作命令
# 启动
zkServer.sh start zoo.cfg
# 查看状态
zkServer.sh status zoo.cfg
# 重启
zkServer.sh restart zoo.cfg
# 停止
zkServer.sh stop zoo.cfg
数据模型
整体模型
zk 可以看作一种文件系统+通知机制,其数据模型类似文件系统的目录树结构,由若干 znode 节点构成,数据也是保存在 znode 中,每个 znode 默认能够存储 1MB 数据。
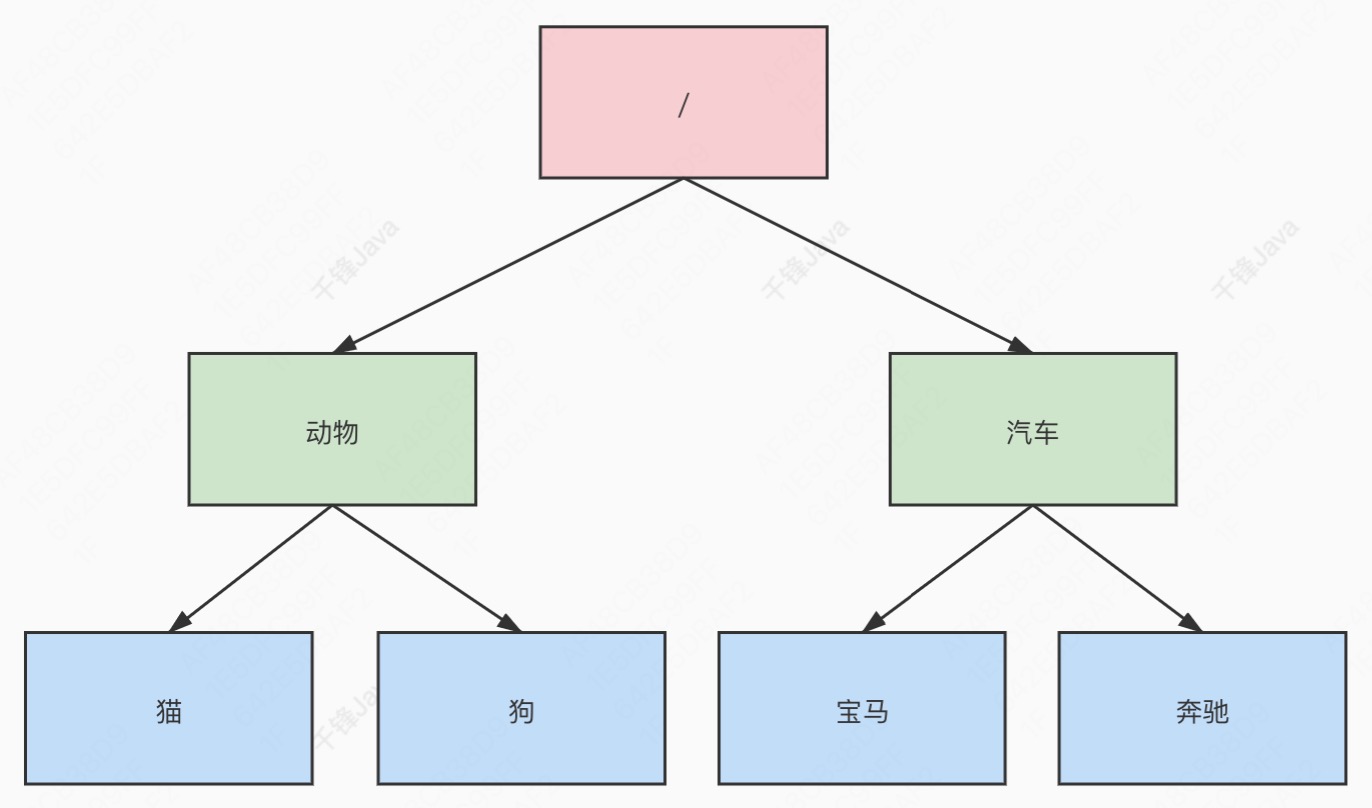
节点通过路径引用定位,每个 znode 拥有唯一的路径,类似命名空间一样对不同信息进行了清晰的隔离,例如/汽⻋/宝⻢。
节点结构
zk 中的 znode 包含了四个部分:
- data:保存数据
- acl:类似 Unix 系统的权限控制(Access Control List)
- c: create 创建权限,允许在该节点下创建子节点
- w: write 更新权限,允许更新该节点的数据
- r: read 读取权限,允许读取该节点的内容以及子节点的列表信息
- d: delete 删除权限,允许删除该节点的子节点
- a: admin 管理者权限,允许对该节点进行 acl 权限设置
- stat:描述节点的元数据,包括三个数据版本
- version:当前 znode 版本
- cversion:当前 znode 子节点版本
- aclversion:当前 znode 的acl版本
- child:子节点
节点类型
- 持久节点
- 在会话结束后依然存在的节点
- 适合保存数据
create /test1 <data>
- 持久序号节点
- 按执行先后在节点后带上一个单调递增的数值
- 用于分布式锁
create -s /test1/subnode1 <data>
- 临时节点
- 会话结束后会被自动删除
- 可以用于服务注册与发现
create -e /temp1 <data>
- 临时序号节点
- 带序号的临时节点
- 用于临时的分布式锁
create -e -s /temp2 <data>
- Container 节点
- 容器节点
- 当容器中没有任何子节点,该容器节点会被zk定期删除(60s)
create -c /container <data>
- TTL 节点
- 可以指定节点的到期时间,到期后被zk定时删除
- 只能通过系统配置
zookeeper.extendedTypesEnabled=true开启 create -t <ttl> /node <data>
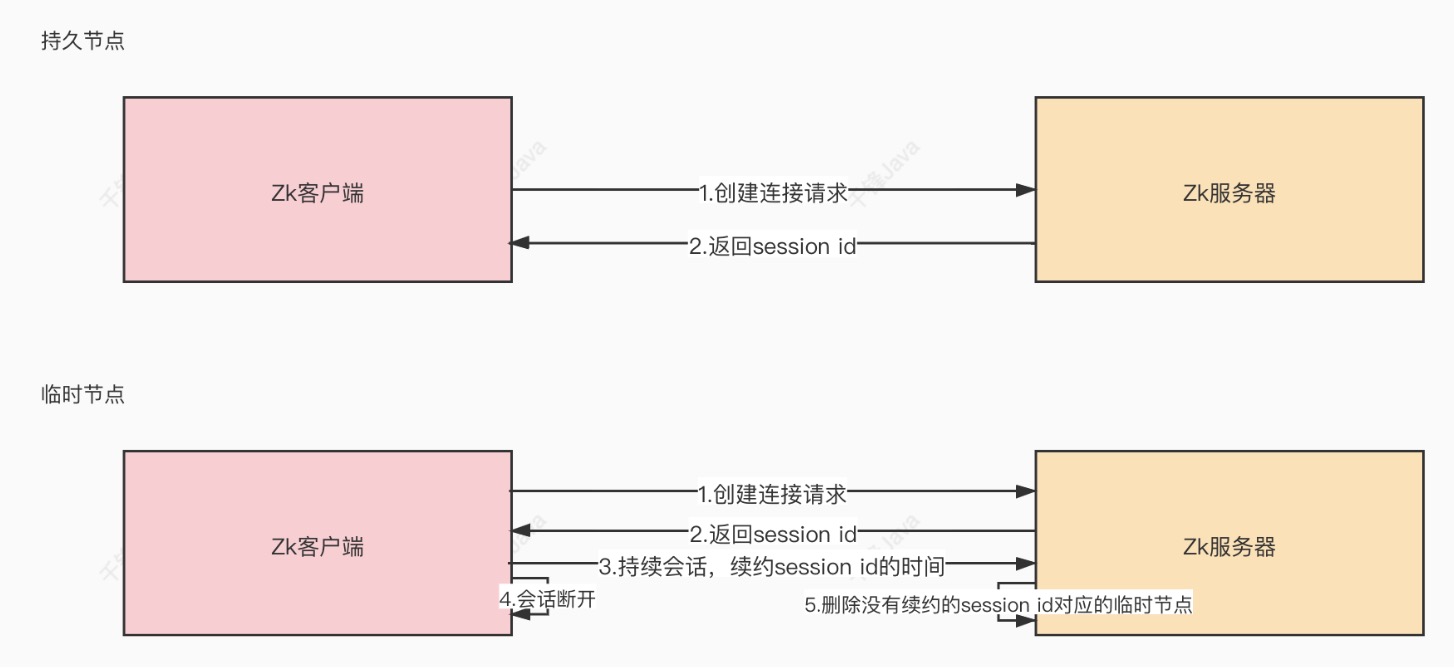
临时节点通过心跳维持连接,续约 sessionId 的有效期,zk 会定期删除没有续约的 sessionId 对应的临时节点。
持久化
zk 提供了两种数据持久化机制,和 Redis 的 AOF/RDB 非常类似。
-
事务日志 zk 把执行的命令以日志形式保存在 dataLogDir/dataDir 指定的路径文件中。
-
数据快照 zk 在一定的时间间隔内做一次内存数据的快照,把该时刻的内存数据保存在快照文件中。
在指定的数据目录下,zookeeper_server.pid 是用于集群搭建的 pid 标识,version2子目录下的 log 文件就是事务日志,而 snapshot 就是数据快照。因此可以发现,zk 的两种持久化机制默认都是开启的,数据在恢复时先恢复快照文件中的数据到内存中,再用日志文件中的数据做增量恢复,以此来提高恢复速度。
网络模式
- NIO 非阻塞
- 客户端连接端口使用 NIO 模式
- 客户端开启 Watch 监听时也使用 NIO,等待服务器的回调
- BIO 阻塞式
- 选举时节点间的投票通信端口使用 BIO 进行通信
zkCli 客户端
创建节点
# Sequential | Ephemeral | Container | TTL
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
查看节点
# 查看节点结构。-s 详细信息 | -R 递归查询子节点 | -w 设置监视器
ls [-s] [-R] [-w] path
# 查看节点数据。-s 详细信息 | -w 设置监视器
get [-s] [-w] path
查询结果:
- cZxid: 创建节点的事务ID
- mZxid:修改节点的事务ID
- pZxid: 添加和删除子节点的事务ID
- ctime: 节点创建的时间
- mtime: 节点最近修改的时间
- dataVersion: 节点内数据的版本,每更新一次数据,版本会+1
- aclVersion: 此节点的权限版本
- ephemeralOwner: 如果当前节点是临时节点,该值是当前节点所有者的 sessionId。否则该值为零。
- dataLength: 节点内数据的⻓度
- numChildren: 该节点的子节点个数
其中,zxid 是事务id,每次向 zookeeper 写入或者修改数据时都会产生一个事务。它是 zookeeper 中所有修改的次序,如果 zxid1 小于 zxid2,那么 zxid1 对应的修改操作在 zxid2 之前发生。
修改节点
# -s 显示详细信息 | -v CAS 验证版本号
set [-s] [-v version] path data
删除节点
# -v CAS 验证版本号
delete [-v version] path
# 用于子节点非空的节点
deleteall path [-b batch size]
设置权限
# 注册当前会话的账号和密码
addauth digest chanper:123456
# 创建节点并设置权限
create /test-node abcd auth:xiaowang:123456:cdwra
# 之后在另一个会话中必须先使用账号密码,才能拥有操作该节点的权限
Curator 客户端
Curator 是 Netflix 公司开源的一套 zookeeper 客户端框架,Curator 是对Zookeeper 支持最好的客户端框架。Curator 封装了大部分 Zookeeper 的功能,比如 Leader 选举、分布式锁等,减少了技术人员在使用 Zookeeper 时的底层细节开发工作。
依赖
<!--Curator-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>2.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
<!--Zookeeper-->
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.7.1</version>
</dependency>
配置
curator.retryCount=5
curator.elapsedTimeMs=5000
curator.connectString=localhost:2181
curator.sessionTimeoutMs=60000
curator.connectionTimeoutMs=5000
// 注入配置 Bean
@Data
@Component
@ConfigurationProperties(prefix = "curator")
public class WrapperZK {
private int retryCount;
private int elapsedTimeMs;
private String connectString;
private int sessionTimeoutMs;
private int connectionTimeoutMs;
}
// 注入CuratorFramework
@Configuration
public class CuratorConfig {
@Autowired
WrapperZK wrapperZk;
@Bean(initMethod = "start")
public CuratorFramework curatorFramework() {
return CuratorFrameworkFactory.newClient(
wrapperZk.getConnectString(),
wrapperZk.getSessionTimeoutMs(),
wrapperZk.getConnectionTimeoutMs(),
new RetryNTimes(wrapperZk.getRetryCount(), wrapperZk.getElapsedTimeMs()));
}
}
API
@Slf4j
@SpringBootTest
class BootZkClientApplicationTests {
@Autowired
CuratorFramework curatorFramework;
@Test
void createNode() throws Exception {
String path = curatorFramework.create().forPath("/curator-node");
String path1 = curatorFramework.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath("/curator-node", "some-data".getBytes());
System.out.println(String.format("curator create node :%s successfully.", path));
}
@Test
public void testGetData() throws Exception {
byte[] bytes = curatorFramework.getData().forPath("/curator-node");
System.out.println(new String(bytes));
}
@Test
public void testSetData() throws Exception {
curatorFramework.setData().forPath("/curator-node", "changed!".getBytes());
byte[] bytes = curatorFramework.getData().forPath("/curator-node");
System.out.println(new String(bytes));
}
@Test
public void testCreateWithParent() throws Exception {
String pathWithParent = "/node-parent/sub-node-1";
String path = curatorFramework.create().creatingParentsIfNeeded().forPath(pathWithParent);
System.out.println(String.format("curator create node :%s successfully.", path));
}
@Test
public void testDelete() throws Exception {
String pathWithParent = "/node-parent";
curatorFramework.delete().guaranteed().deletingChildrenIfNeeded().forPath(pathWithParent);
}
}
分布式锁
锁的种类
zk 中的锁分为两类:
- 读锁: 共享可读,与写锁互斥
- 写锁: 独占写锁,与读锁、写锁都互斥
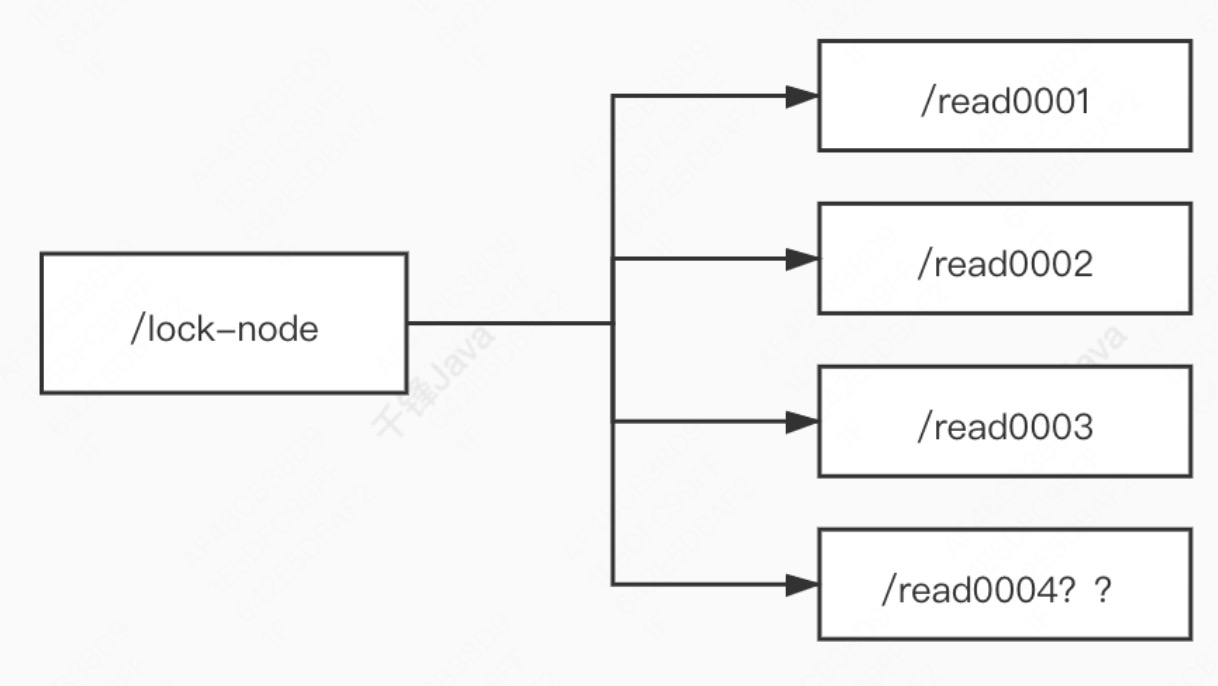
加读锁
- 创建一个临时序号节点,节点数据是 read 表示是读锁
- 获取当前 zk 中序号比自己小的所有节点
- 判断最小节点是否是读锁
- 如果不是读锁的话,则上锁失败,阻塞等待并监听最小节点
- 如果是读锁的话,则上锁成功
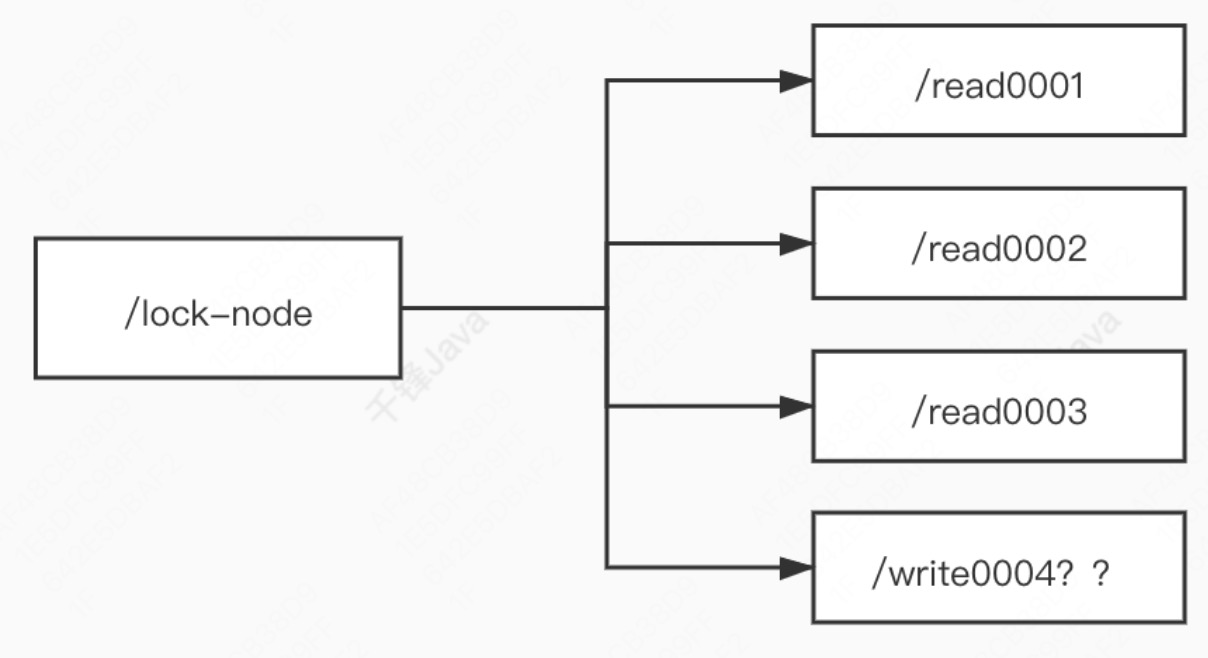
加写锁
- 创建一个临时序号节点,节点数据是 write 表示是写锁
- 获取zk中所有的子节点
- 判断自己是否是最小的节点
- 如果是,则上写锁成功
- 如果不是,说明前面还有锁,则上锁失败,阻塞等待并监听最小的节点
羊群效应
如果用上述的加锁方式,只要有节点发生变化,就会触发其他所有节点的监听事件。这样的话对 zk 的压力非常大,即羊群效应。因此可以调整成链式监听。
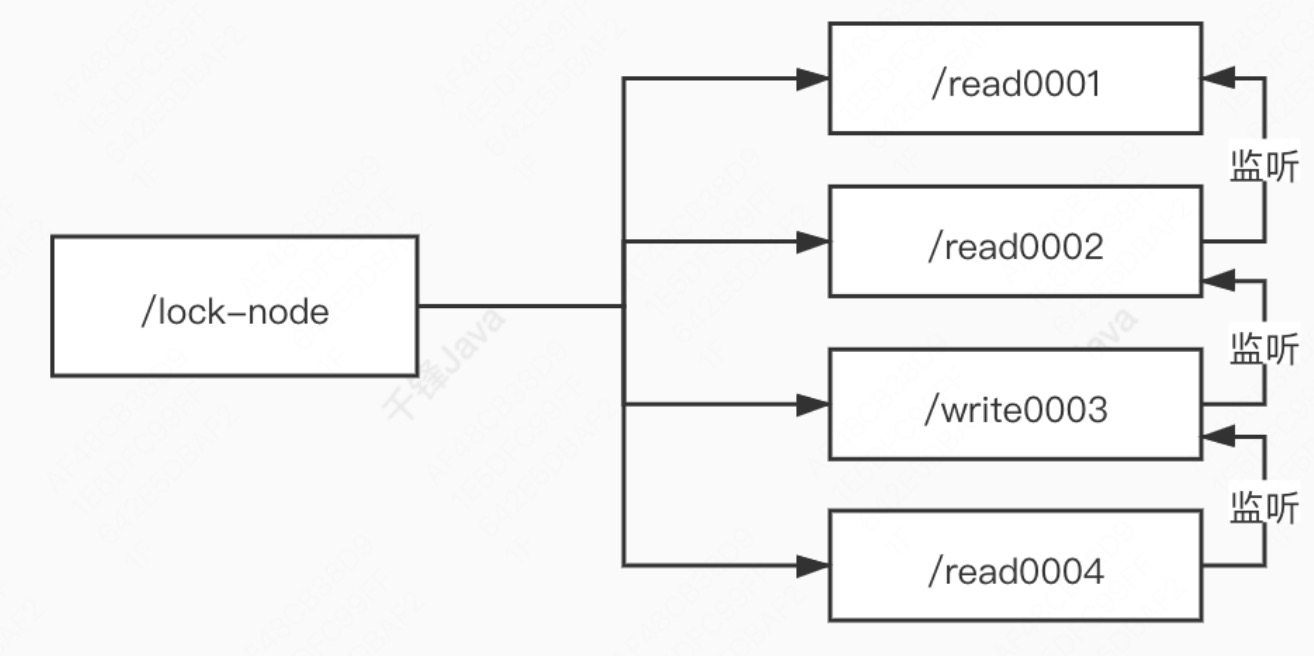
每个 znode 只监听自己临近的节点,这样序号最小的节点变化时只会触发后续一个节点的监听事件。
对比 Redis
Redis 集群性能非常高,但在 master 发生故障时,主从切换时是异步复制的,可能导致数据丢失,无法保证分布式锁的绝对安全。
而 Zookeeper 在实现分布式锁上,可以做到强一致性。但是每次在创建和释放锁的过程中,都要动态创建、销毁临时节点,并且只能通过 Leader 服务器来执行,然后再将数据同步到所有的 Follower 机器上。因此相比 Redis 并发性能较低,开销较大。
Curator 加锁
@SpringBootTest
public class TestReadWriteLock {
@Autowired
private CuratorFramework client;
@Test
void testGetReadLock() throws Exception {
// 读写锁
InterProcessReadWriteLock interProcessReadWriteLock = new InterProcessReadWriteLock(client, "/lock1");
// 获取读锁对象
InterProcessLock interProcessLock = interProcessReadWriteLock.readLock();
System.out.println("等待获取读锁对象!");
// 获取锁
interProcessLock.acquire();
for (int i = 1; i <= 100; i++) {
Thread.sleep(3000);
System.out.println(i);
}
// 释放锁
interProcessLock.release();
System.out.println("释放读锁!");
}
@Test
void testGetWriteLock() throws Exception {
// 读写锁
InterProcessReadWriteLock interProcessReadWriteLock = new InterProcessReadWriteLock(client, "/lock1");
// 获取写锁对象
InterProcessLock interProcessLock = interProcessReadWriteLock.writeLock();
System.out.println("等待获取写锁对象!");
// 获取锁
interProcessLock.acquire();
for (int i = 1; i <= 100; i++) {
Thread.sleep(3000);
System.out.println(i);
}
// 释放锁
interProcessLock.release();
System.out.println("释放写锁!");
}
}
启动两个 testGetReadLock() 测试实例,由于是读锁,因此两个实例不会发生阻塞,正常打印信息。当启动一个 testGetWriteLock() 测试实例时,会一直阻塞,直到前面两个读锁测试结束,才会开始打印。
Watch 机制
Watch 即注册在特定 znode 上的触发器,当这个 znode 发生变化,也就是调用create, delete, setData等方法时,会触发 znode 上注册的监听事件,请求注册 Watch 的客户端会接收到 NIO 异步通知。
ZK 的 Watch 监听是一次性的,触发后需要重复注册监听,并且不能保证客户端收到每次节点变化的通知。
实现原理
客户端在监听的时候会创建两个子线程,一个负责网络通信(connector),另一个负责监听(listener)。通过 connector 将注册的监听事件发送给服务端,服务端将注册的监听事件添加进内部维护的注册监听器列表中。当服务端监听到有数据变化,会查询列表找到所有 watcher 并发送异步通知给 listener 线程,然后 listener 线程将消息输出出来。
zkCli 监听
create /test xxx
# 一次性监听节点
get -w /test
# 监听目录,创建和删除子节点会收到通知。但子节点中再新增节点不会收到通知
ls -w /tes
# 监听子节点中子节点的变化,但内容的变化不会收到通知
ls -R -w /test
Curator 监听
@Test
public void addNodeListener() throws Exception {
NodeCache nodeCache = new NodeCache(curatorFramework, "/curator-node");
nodeCache.getListenable().addListener(new NodeCacheListener() {
@Override
public void nodeChanged() throws Exception {
byte[] bytes = curatorFramework.getData().forPath("/curator-node");
log.info("{} path node Changed, data: {}", "/curator-node", new String(bytes));
}
});
nodeCache.start();
System.in.read();
}
集群
集群角色
- Leader: 处理集群的所有事务请求,进行投票的发起和决议,更新系统状态。集群中只有一个 Leader
- Follower: 只能处理读请求,参与 Leader 选举
- Observer: 只能处理读请求,提升集群读的性能,不参与 Leader 选举。
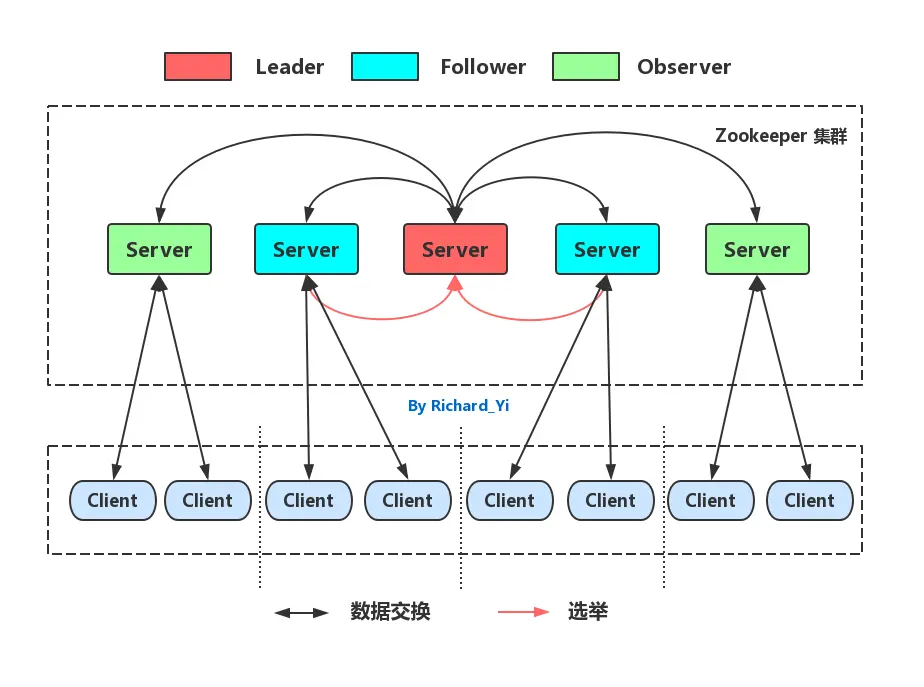
ZooKeeper 每个节点拥有集群的全量数据,因此扩容 Observer 能分摊 connections、watch数、读请求,但不能分摊写请求和 Znode 的数量与大小,而且集群越大,写请求时Leader所需的事务协调工作也越多。因此需要根据实际的业务决定节点数量。
集群搭建
创建 zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
# 每个实例对应的数据目录
dataDir=/tmp/zookeeper/zk1
# 每个实例用于客户端连接的端口
clientPort=2181
# 服务之间的关联。其中第一列端口用于集群内部通信,第二列端口用于集群选举
# observer 表示该节点是观察者角色,不参与选举
server.1=127.0.0.1:2001:3001
server.2=127.0.0.1:2002:3002
server.3=127.0.0.1:2003:3003
server.4=127.0.0.1:2004:3004:observer
创建 myid
# 分别在每个实例的数据目录下创建 myid 标识
/tmp/zookeeper/zk1# echo 1 > myid
/tmp/zookeeper/zk2# echo 2 > myid
/tmp/zookeeper/zk3# echo 3 > myid
/tmp/zookeeper/zk4# echo 4 > myid
启动所有 zk 实例
zhServer.sh start zoo1.cfg
zhServer.sh start zoo2.cfg
zhServer.sh start zoo3.cfg
zhServer.sh start zoo4.cfg
连接 zk 集群
zkCli.sh -server localhost:2181,localhost:2182,localhost:2183,localhost:2184
ZAB 协议
Zookeeper 作为非常重要的分布式协调组件,需要以一主多从的形式进行集群部署,Leader 负责接收写请求,Follower 负责接收读请求以及和 Leader 进行数据同步。
Zookeeper 架构上是 CP 模型,集群的数据是全局一致的,每个 Server 都保存了相同的数据副本。也正因此,ZK 适合存储一些简单的配置信息,而非大量数据。为了保证数据的一致性,Zookeeper 使用 ZAB (Zookeeper Atomic Broadcast) 原子广播协议解决崩溃恢复和主从数据同步的问题。
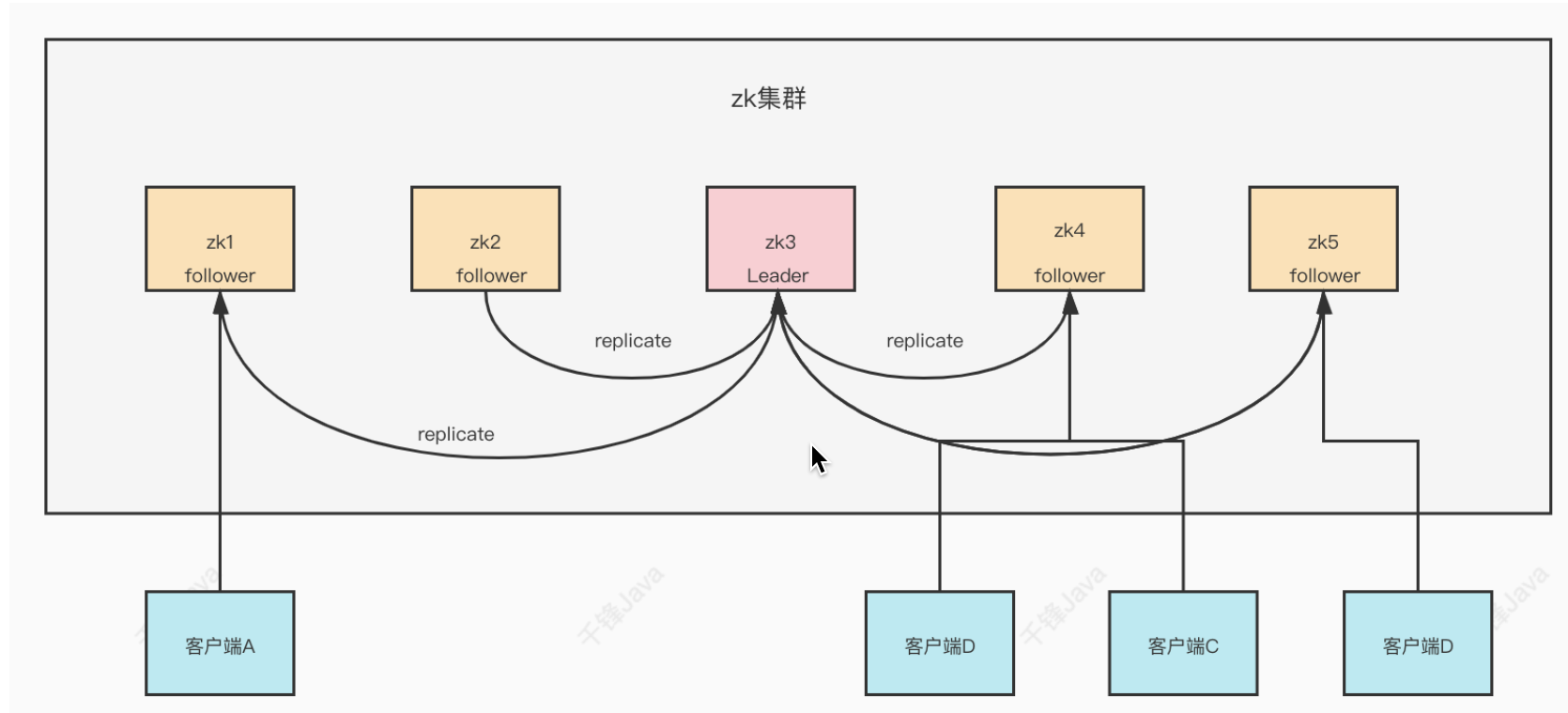
节点状态
- Looking: 选举状态
- Following: 从节点所处状态
- Leading: 主节点所处状态
- Observing: 观察者节点所处状态
选举过程
ZK 会在集群启动,或者 Leader 宕机两种情况下进行选举。每轮选举中,除 Observer 外每个节点都可以投票,且默认都投给自己,当一个节点获得超过半数选票则自动成为集群里的 Leader,后续新加入的节点自动成为 Follower。
注:正是因为“半数”这个要求,所以一般 ZK 集群的节点个数为奇数个,因为 3/4 个节点的 ZK 集群都能容忍 1台节点宕机,即它们的容灾能力是一样的,从节约资源的角度所以只设置奇数个节点。
启动时选举
我们以5个节点的集群启动为例分析:
-
server1 启动:
- 发起选举,server1 投给自己
- server1 仅有一票,没超过半数 3,进入 Looking 状态
-
server1 启动:
- 发起选举,server1 和 server2 都投票给自己,然后交换选票信息
- server1 发现 server2 的 id 比自己大,于是改投 server2
- server2 有两票,没超过半数 3,于是都进入 Looking 状态
-
server3 启动:
- 发起选举,各自都先投给自己,然后交换选票信息
- server1 和 server2 发现 server3 的 id 比自己大,改投 server3
- 此时 server3 有 3 票,超过节点半数,于是成为 Leader,进入 Leading 状态。server1 和 server2 进入 Following 状态
-
server4 启动:
- 发起选举,server4 投给自己。但非 Looking 状态的 server1、server2、server3 不会改投
- 于是 server3 有 3 票,server4 有 1 票。少数服从多数,server4 会将自己选票交给 server3,并成为 Follower 进入 Following 状态
-
server5 启动:
- 同理,server5 投给自己,其它不改投
- server3 有 4 票当选 Leader,server5 将选票交给 server3 成为它的 Follower
关键点:
- 每个 server 启动之后都会发起选举,并将票投给自己。然后交换选票信息,并将票投给 id 最大的 server
- 一旦选择出 Leader,其它节点自动成为 Follower。而后启动的 server,不论 id 多大,也只能成为 Follower
Leader 宕机时选举
- sid:就是我们一直说的服务器 id,用于唯一标识集群中的节点
- zxid:事务id,客户端在发起一次写请求的时候,都会带有 zxid,用于标识一次服务器状态的变更。实现上是一个 64bit 的数字,高 32bit 标识 Leader 关系,低 32bit 用于递增计数
- epoch:Leader 任期的编号,每投完一次票,这个编号就会增加
重新选举的规则:
- 先比较节点之间的 epoch,epoch 大的直接当选;
- epoch 相同,再比较 zxid,zxid 大的当选;
- epoch 和 zxid 都相同,则比较 sid,sid 大的当选;
数据读写
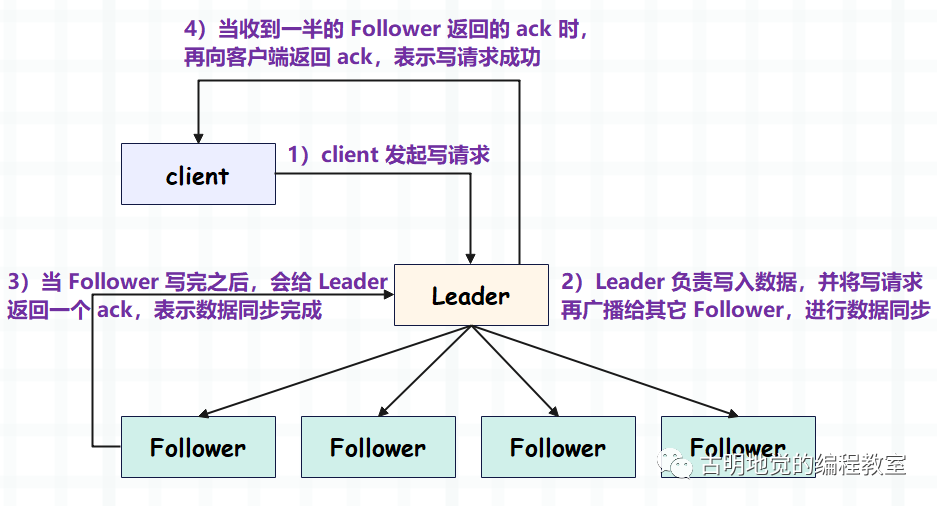
Leader 为了快速响应,不会等到所有的 Follower 都写完,只要有一半的 Follower 写完,就会告知客户端。还是半数机制,一半的 Follower 加上 Leader 正好刚过半数。
而如果客户端写请求命中的是 Follower,Follower 节点会将请求转发给 Leader,然后执行类似过程。超过半数 Follower 写数据成功后,Leader 将 Ack 返回给客户端请求的那个 Follower,最后由这个 Follower 将 Ack 返回给客户端确认写请求执行完毕。
CAP 理论
分布式计算领域的公认定理:一个分布式系统最多只能同时满足一致性(Consistency)、可用性 (Availability)和分区容错性(Partition tolerance)这三项中的两项。
- Consistency:更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。
- Availability:服务一直可用,而且是正常响应时间。
- Partition tolerance:分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性或可用性的服务。
至于具体选择 AP/CP,根据场景定夺,没有好坏。
BASE 理论
BASE 理论是对 CAP 理论的延伸,核心思想是即使无法做到 CAP 中的强一致性,但服务可以采用适合的方式达到最终一致性 (Eventual Consitency)。
- 基本可用(Basically Available): 基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。
- 软状态(Soft State): 软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。
- 最终一致性(Eventual Consistency): 最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
Zookeeper 架构设计追求的是 CP 模式,基于 事务id 的单调递增保证顺序一致性(Paxos算法),但在数据同步的时候无法提供对外服务。相对的,Redis 集群是追求的 AP 模式,各个节点可以独立处理读写请求,数据同步是异步进行的,因此在产生网络分区时,不同节点间数据可能不一致。
评论加载中。如果这里长期空白,请检查 giscus.app / GitHub 是否可访问。