Redis 独立功能
发布与订阅 Redis的发布订阅功能由PUBLISH, SUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE等命令实现,客户端可以订阅一个或多个频道/模式,服务器根据是否订阅频道、模式是否匹配,决定是否发送给指定客户端
发布与订阅
Redis的发布订阅功能由PUBLISH, SUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE等命令实现,客户端可以订阅一个或多个频道/模式,服务器根据是否订阅频道、模式是否匹配,决定是否发送给指定客户端消息。
频道
客户端执行SUBSCRIBE命令订阅频道后,这个客户端就和频道建立了订阅关系。所有订阅关系保存在redisServer/pubsub_channels字典中,字典的键是频道,值是订阅者的链表。
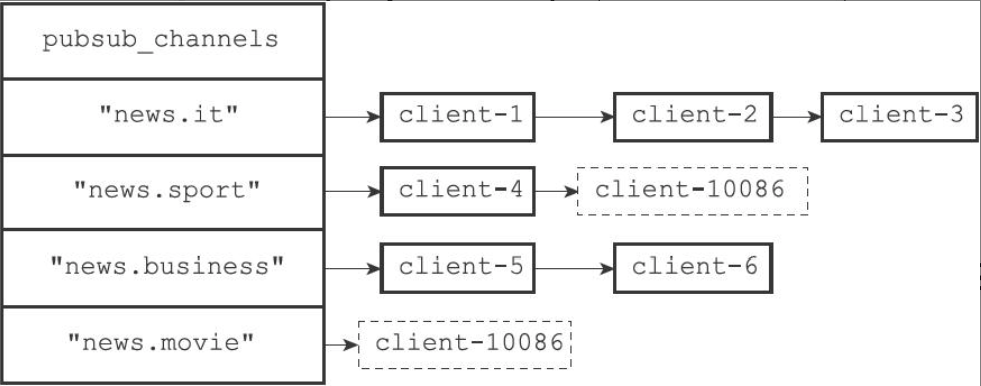
- 订阅频道时,(创建新的频道键)将客户端添加到频道对应的订阅者链表末尾
- 退订频道时,删除对应订阅者链表的客户端,如果链表为空,再删除频道键
模式
客户端执行PSUBSCRIBE命令订阅模式后,这个客户端就和模式建立了订阅关系。所有模式订阅关系保存在redisServer/pubsub_patterns列表中,列表的每个元素是一个pubsubPattern结构,保存模式和客户端。
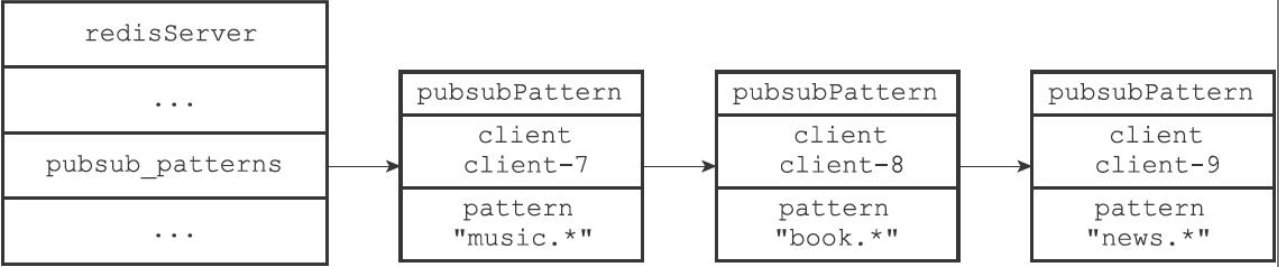
- 订阅模式时,创建新的pubsubPattern结构,保存客户端和模式,添加到列表尾
- 退订模式时,删除对应的pubsubPattern结构
发送消息
当客户端执行publish <channel> <msg>时:
- 查询pubsub_channels,遍历channel键的订阅者链表,将msg发送给channel订阅者
- 遍历pubsub_patterns列表,将msg发送给与频道匹配的模式关联的客户端
查看订阅
PUBSUB命令本质上都是对pubsub_channels和pubsub_patterns的访问:
PUBSUB CHANNELS [pattern]返回当前被订阅的所有频道,或符合pattern的所有频道PUBSUB NUMSUB [channle...]返回频道对应的订阅数PUBSUB NUMPAT返回当前订阅模式数
事务
Redis通过MULTI, EXEC, WATCH等命令实现事务,提供一种将多个命令请求打包,然后一次性、不会中断地、顺序执行多个命令的机制。
事务实现
事务开始
MULTI命令打开客户端的REDIS_MULTI标识,切换至事务状态。
命令入队 当一个客户端处于事务状态,除EXEC, DISCARD, WATCH, MULTI四个命令外,其它命令都不会立即执行,而是放入redisClient/mstate结构的multiCmd数组里。multiCmd是基于数组实现的FIFO队列,每个multiCmd封装一个具体的命令、参数以及个数。
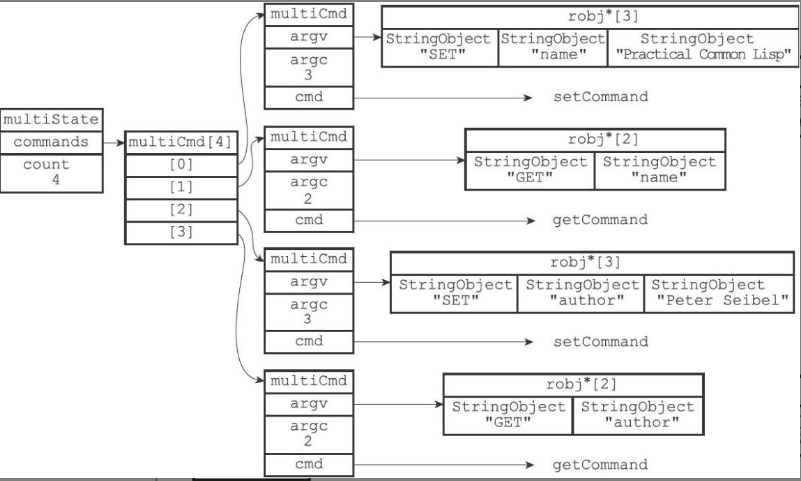
执行事务
EXEC命令用于执行事务,服务器将遍历客户端的事务队列,依次执行所有命令,并将全部结果返回给客户端。
Watch 命令
WATCH命令是一个乐观锁,可以在EXEC命令执行前监视任意数量的数据库键,并在EXEC命令执行时,检查被监视的键是否至少有一个已经被修改过,如果是,服务器将拒绝执行事务,并向客户端返回代表事务执行失败的空回复。
原理
每个redisDb结构保存了一个watched_keys字典,键是被监视的数据库键,值是监视的客户端链表。
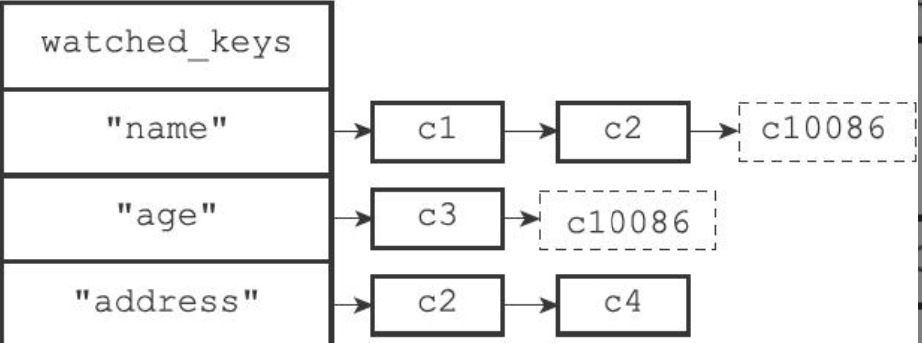
所有对数据库进行修改的命令,如SET, LPUSH…都会在执行后调用multi.c/touchWatchKey函数对watched_keys字典检查,如果有客户端正在监视刚刚修改过的数据库键,则会打开客户端的REDIS_DIRTY_CAS标识,表示该客户端的事务安全性已被破坏。
而当服务器开始执行事务时,如果发现该客户端的REDIS_DIRTY_CAS已打开,将拒绝执行并回复错误消息,以此来保证事务的安全性。
事务的ACID
Redis的事务总是具有原子性、一致性、隔离性,特定情况下具有持久性
- 原子性:数据库将食物中的多个操作当作一个整体来执行,要么执行所有,要么一个也不执行
- Redis事务队列中的命令要么全部执行,要么一个都不执行,因此具有原子性
- 不同于传统的关系型数据库,Redis不支持事务回滚。即使队列中某个命令执行出错,也会继续执行下去
- 一致性:如果数据库在执行事务前是一致的,那么事务执行后,无论事务是否成功,数据库仍应保持一致(符合定义和要求,没有非法或无效数据)
- Redis在入队错误、执行错误、服务器停机等场景下,都进行了处理,保证了事务的一致性
- 隔离性:即使数据库中有多个事务并发执行,各个事务之间也不会相互影响,且和串行执行结果相同
- Redis使用单线程方式,串行执行事务,且不会中断,因此具有隔离性
- 持久性:当一个事务执行完毕后,所得结果不会丢失
- Redis的事务仅仅是简单的执行一组命令,没有提供额外的持久化功能。因此持久性由持久化模式决定
- 仅AOF持久化模式下,appendfsync选项为always时,具有持久性(no-appendfsync-on-rewrite关闭)
- 内存/RDB/AOF(not always)模式下都不能保证持久性
Lua脚本
创建Lua环境
Redis在服务器内嵌了一个修改过的Lua环境,来执行Lua脚本。具体步骤包括:
- 创建基础Lua环境
- 载入多个函数库
- 创建全局表格redis,包含对Redis进行操作的函数
- 使用Redis自制的随机函数替换原有的随机函数,避免副作用
- 创建排序辅助函数
- 创建redis.pcall函数的错误报告辅助函数
- 对Lua环境的全局环境进行保护,防止用户添加额外的全局变量
- 将完成修改的Lua环境保存到redisServer/lua属性中,等待执行服务器传来的Lua脚本
协作组件
伪客户端
为了执行Lua脚本包含的Redis命令,需要为Lua环境创建一个伪客户端。执行命令的交互过程如下:
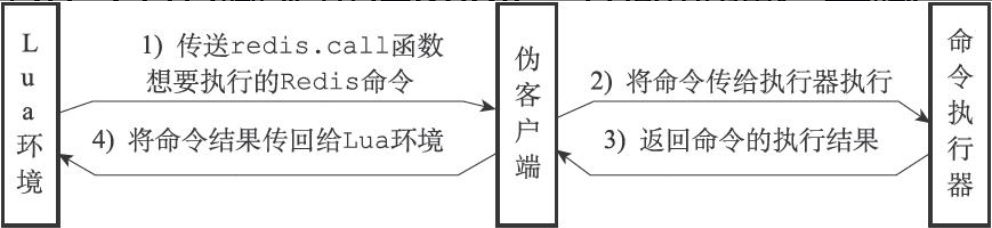
lua_scripts 字典
- lua_scripts 字典的键是为某个Lua脚本的SHA1校验和,值是对应的Lua脚本。
- 所有被服务器 EVAL 命令执行过的脚本,以及 SCRIPT LOAD 命令载入过的脚本都保存至 lua_scripts 字典中。
- lua_scripts 字典有两个作用:
- 实现 SCRIPT EXISTS 命令
- 实现脚本复制功能
EVAL 命令
EVAL script <numkeys> key... arg... 根据传入的键、参数执行脚本。
- 根据客户端给定的Lua脚本,在Lua环境中定义一个Lua函数
- 函数名为
f_脚本的sha1校验和
- 函数名为
- 将客户端给定的脚本保存到lua_scripts字典
- 执行刚刚在Lua环境中定义的函数,以此来执行客户端给定的Lua脚本。
- 将 EVAL 命令中传入的键名参数和脚本参数分别保存到KEYS数组和ARGV数组,将两个数组作为全局变量传入 Lua 环境里。
- 为 Lua 环境装载超时处理钩子,使得脚本超时运行时,让客户端通过 SCRIPT KILL 命令停止脚本,或者通过 SHUTDOWN 命令直接关闭服务器。
- 执行脚本函数
- 移除之前装载的超时钩子
- 将执行脚本函数所得的结果保存到客户端状态的输出缓冲区里面,等待服务器将结果返回给客户端。
- 对Lua环境执行垃圾回收操作。
EVALSHA <sha1> numkeys key... arg... 根据已保存过的脚本SHA1执行对应的脚本。
脚本管理命令
SCRIPT FLUSH清除服务器中所有和Lua脚本有关的信息,释放并重建 lua_scripts 字典和 Lua 环境SCRIPT EXISTS <sha1>检查 lua_scripts 字典,查看校验和对应脚本是否存在于服务器SCRIPT LOAD script为脚本创建相对应的函数,并保存至 lua_scripts 字典中SCRIPT KILL停止执行脚本- 超时处理钩子在脚本运行期间,会定期检查脚本运行时长,如果超过lua-time-limit选项设置的时长,钩子将定期在脚本运行的间隙中,查看是否有 SCRIPT KILL 命令或者 SHUTDOWN 命令到达服务器。
- 如果没有执行写操作,可以 SCRIPT KILL 停止执行脚本
- 如果执行过写操作,可以 SHUTDOWN nosave 停止服务器
脚本复制
与其他普通Redis命令一样,当服务器运行在复制模式下,具有写性质的脚本命令也会被复制到从服务器。
对于 EVAL, SCRIPT FLUSH, SCRIPT LOAD 三个命令,主服务器将直接传播给所有从服务器
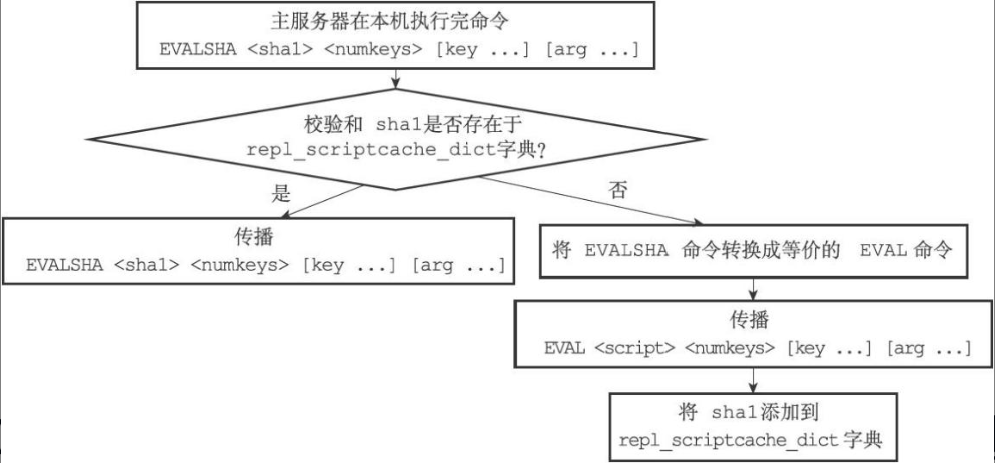
复制 EVALSHA 命令
由于主服务器和从服务器载入的脚本情况可能不同,EVALSHA 命令可能出现 not found 错误。因此在传播时必须确保 EVALSHA 命令要执行的脚本已经被从服务器载入,需要借助 lua_scripts, repl_scriptcache_dict 两个字典。
- repl_scriptcache_dict:主服务器记录自己已经将哪些脚本传播给了所有从服务器。
- 键是脚本的SHA1值,值全部是NULL
- 当一个校验和出现在 repl_scriptcache_dict 字典时,说明对应的脚本已经传播给了所有从服务器
- 每当主服务器添加一个新的从服务器时,主服务器都会清空自己的repl_scriptcache_dict字典。强制自己重新向所有从服务器传播脚本
- 如果一个SHA1值对应脚本没有载入所有从服务器,主服务器可以将 EVALSHA 命令转换成 EVAL 命令:
- 根据校验和,在 lua_scripts 字典中查找对应的脚本
- 将原来的 EVALSHA 命令请求改写成 EVAL 命令请求,并将校验和改成脚本,而 numkeys、key、arg 等参数则保持不变
排序
Sort 命令
SORT <key>
-- 对字符串值的键进行排序(字典序)
SORT <key> ALPHA
-- 升降序,默认升序
SORT <key> ASC|DESC
-- 按指定键/域排序
SORT <key> BY <by-pattern>
-- 分页:跳过offset个,返回count个
SORT <key> LIMIT <offset> <count>
-- 返回指定域
SORT <key> GET <get-pattern>
-- 保存排序结果(每次都会更新保存结果,本质上是保存一个列表)
SORT <key> STORE <store-key>
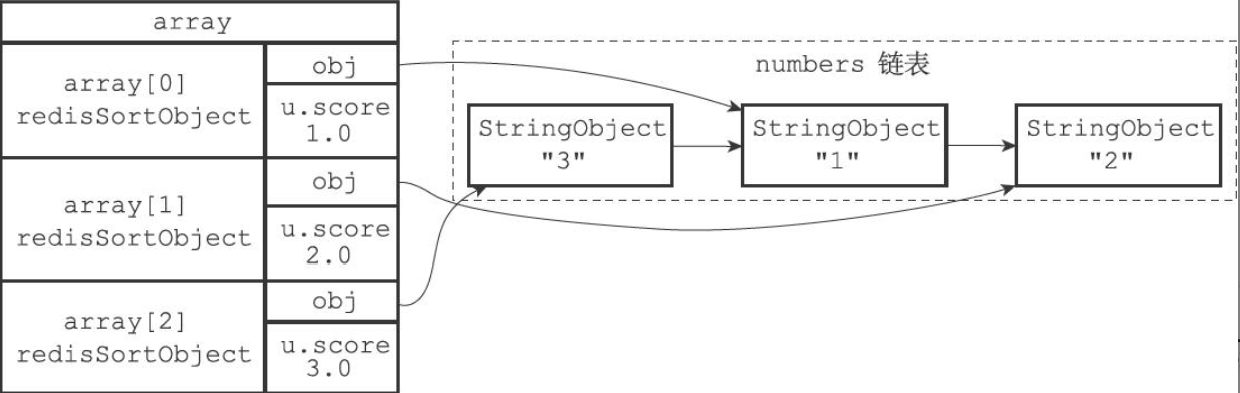
底层实现
- 创建和 key 长度相同的数组,该数组的每个项都是一个 redis.h/redisSortObject 结构
- 遍历数组,将各个数组项的 obj 指针分别指向 key 的各个项,构成obj指针和列表项之间的一对一关系
- 遍历数组,将各个 obj 指向的列表项 根据指定规则 转换成一个double类型的浮点数,保存在数组项的u.score属性中
- 根据u.score属性值,对数组进行基于快排的数字值排序,默认升序
- 遍历数组,将列表项/指定域作为排序结果返回给客户端
执行顺序
SORT <key> ALPHA DESC BY <by-pattern> LIMIT <offset> <count> GET <get-pattern> STORE <store_key>
排序 -> 限制长度 -> 获取外部键 -> 保存结果集 -> 返回客户端
除 GET 影响结果集外,其余选项的书写顺序不影响执行结果。
二进制位数组
Redis提供了SETBIT, GETBIT, BICOUNT, BITOP四个命令用于处理二进制位数组。
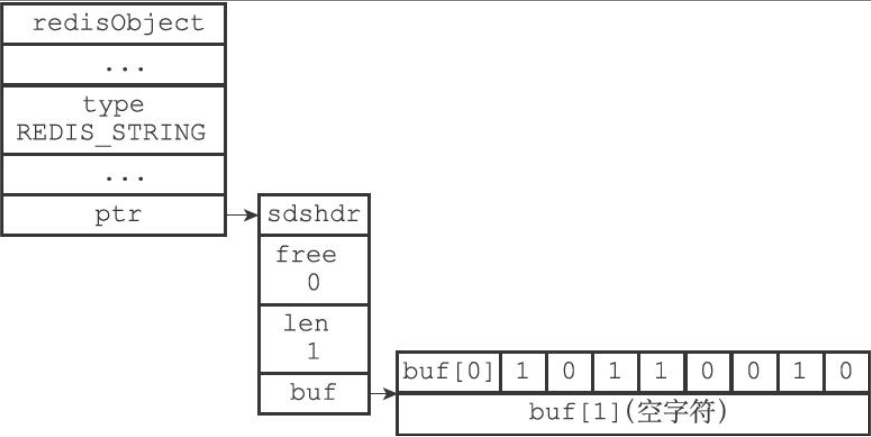
位数组的表示
Redis使用二进制安全的SDS字符串保存位数组,且逆序保存简化操作。
GETBIT
GETBIT <bitarray> <offset> 返回位数组 bitarray 在 offset 偏移量上的二进制位的值,复杂度$O(1)$,执行步骤:
- 计算 $byte = \lfloor offset÷8 \rfloor$,byte 值记录了 offset 偏移量指定的二进制位保存在位数组的哪个字节。
- 计算 $bit = (offset % 8)+1$,bit 值记录了 offset 偏移量指定的二进制位是 byte字节的第几个二进制位。
- 根据byte值和bit值,在位数组bitarray中定位 offset 偏移量指定的二进制位,并返回这个位的值。
SETBIT
SETBIT <bitarray> <offset> <value> 将位数组 bitarray 在 offset 偏移量上的二进制位设为 value,复杂度O(1),执行步骤如下:
- 计算 $len = \lfloor offset÷8\rfloor + 1$,len 值记录了保存 offset 偏移量指定的二进制位至少需要多少字节。
- 检查 bitarray 键保存的位数组(即SDS)的长度是否小于len,如果是,将SDS长度扩展为 len 字节(通常会多分配两个字节),并将所有新扩展空间的二进制位置0。
- 计算 $byte = \lfloor offset÷8 \rfloor$,byte 值记录了 offset 偏移量指定的二进制位保存在位数组的哪个字节。
- 计算 $bit =(offset % 8)+ 1$,bit 值记录了 offset 偏移量指定的二进制位是 byte字节的第几个二进制位。
- 根据 byte 和 bit,在 bitarray 键保存的位数组中定位offset偏移量指定的二进制位,先将指定二进制位现在值保存至 oldvalue 变量,然后将新值value设置为这个二进制位的值。
- 向客户端返回oldvalue变量的值。
Redis逆序存储位数组使得 SETBIT 可以在不移动现有二进制位的情况下,对位数组空间进行扩展
BITCOUNT
BITCOUNT <bitarray> 统计给定二进制位数组中,值为1的位数,即汉明重量。通常的统计算法有:
- 遍历:时间复杂度非常高
- 查表:空间复杂度非常高,16位表键需要几百KB,但32位的表键需要十几GB
- variable-precision SWAR算法:通过位移,计算每2位、4位、8位的汉明重量,最后得到每32位二进制的汉明重量。这种算法时间复杂度大大降低,仅需常量空间复杂度。
Redis的实现结合了查表和SWAR算法,程序会根据未处理的二进制位数量来决定使用哪种算法:
- 如果未处理的二进制位的数量 $>=128$ 位,那么程序使用variable-precision SWAR算法
- 每次循环中载入128个二进制位,然后调用四次32位 SWAR算法来计算这128位的汉明重量
- 如果未处理的二进制位的数量 $<128$ 位,那么程序使用查表算法
- 查表使用键长为8位的表,表中记录了从 0000 0000 到 1111 1111 在内的所有二进制位数组的汉明重量
BITOP
BITOP <op> <result> <x> <y>
Redis基于C语言支持对字节执行逻辑与&、逻辑或|、逻辑异或^、逻辑非~等操作。计算时,按每字节处理存入结果result。
慢查询日志
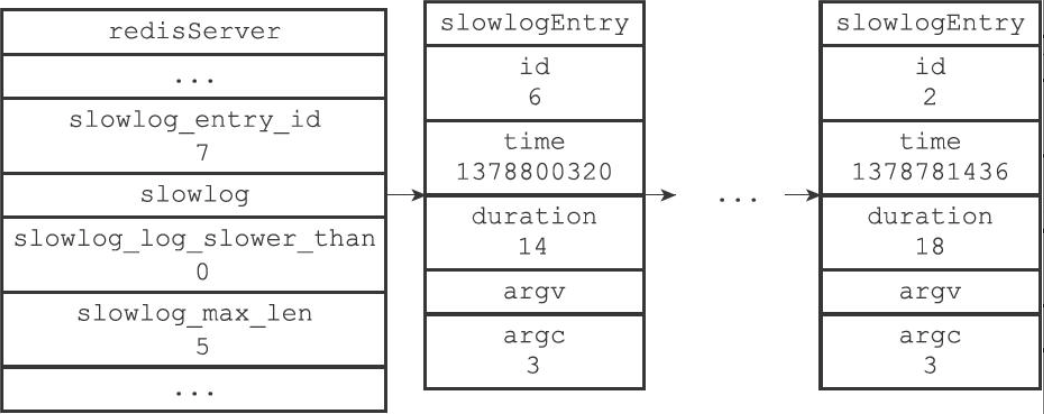
- slowlog_log_slower_than: 慢查询的阈值
- slowlog_max_len: 保存上限
- 所有慢查询日志保存至先进先出的redisServer/slowlog链表中
- 链表使用头插法,结点最多即 slowlog_max_len 个
- 链表的每个结点是 slowlogEntry 结构
- slowlogPushEntryIfNeeded 函数负责检查是否慢查询,以及加入链表
监视器
MONITORS 命令可以让客户端成为一个监视器,实时接收并打印服务器当前处理的命令请求信息。
- 成为监视器:
MONITORS命令打开客户端的 REDIS_MONITOR 标识,并将客户端添加到 redisServer/monitors 链表末尾 - 发送信息:服务器每次处理命令请求前,都会调用 replicationFeedMonitors 函数,封装信息,遍历 monitors 链表并发送
评论加载中。如果这里长期空白,请检查 giscus.app / GitHub 是否可访问。