Netty 网络框架 01
概述 Netty 是什么? Netty is an asynchronous event driven network application framework for rapid development of maintainabl
概述
Netty 是什么?
Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients.
Netty 是一个异步的、基于事件驱动的网络应用框架,用于快速开发可维护、高性能的网络服务器和客户端。作者是韩国的 Trustin Lee,同时也是另一个著名网络应用框架 Mina 的重要贡献者。
Netty 自 2004 年诞生以来,久经考验
- 2.x 2004
- 3.x 2008
- 4.x 2013(现在主要使用的版本)
- 5.x 2015(已废弃,没有明显的性能提升,维护成本高)
Netty 的地位
Netty 在 Java 网络应用框架中的地位就好比:Spring 框架在 JavaEE 开发中的地位。以下的框架都使用了 Netty,因为它们有网络通信需求!
- Cassandra - nosql 数据库
- Spark - 大数据分布式计算框架
- Hadoop - 大数据分布式存储框架
- RocketMQ - 阿里开源的消息队列
- ElasticSearch - 搜索引擎
- gRPC - rpc 框架
- Dubbo - rpc 框架
- Spring 5.x - flux api 完全抛弃了 tomcat ,使用 netty 作为服务器端
- Zookeeper - 分布式协调框架
Netty 的优势
相比于 NIO 和 其它网络应用框架有着无可比拟的优势:
- NIO 工作量大,bug 多
- 需要自己构建协议
- 解决 TCP 传输问题,如粘包、半包
- epoll 空轮询导致 CPU 100%
- 对 API 进行增强,使之更易用,如 FastThreadLocal => ThreadLocal,ByteBuf => ByteBuffer
- 其它网络应用框架
- Mina 由 apache 维护,将来 3.x 版本可能会有较大重构,破坏 API 向下兼容性
- 而 Netty 的开发迭代更迅速,API 更简洁、文档更优秀
Hello World
开发一个简单的服务端和客户端为案例,首先引入 Netty 的依赖:
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>xxx</version>
</dependency>
服务端
public class HelloServer {
public static void main(String[] args) {
// 1.配置服务端启动器类
new ServerBootstrap()
// 类似Boss和Worker,EventLoop = selector + thread
.group(new NioEventLoopGroup())
// 选择服务端 ServerSocketChannel 实现
.channel(NioServerSocketChannel.class)
// worker(child) 处理请求的配置
.childHandler(new ChannelInitializer<>() {
// 5.初始化数据处理器
@Override
protected void initChannel(Channel channel) throws Exception {
channel.pipeline().addLast(new LoggingHandler());
channel.pipeline().addLast(new StringDecoder());
channel.pipeline().addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println(msg);
}
});
}
})
// 2.监听绑定端口
.bind(8080);
}
}
客户端
public class HelloClient {
public static void main(String[] args) throws InterruptedException {
// 3.客户端启动类
new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<NioSocketChannel>() {
// 5.初始化数据处理器
@Override
protected void initChannel(NioSocketChannel channel) throws Exception {
channel.pipeline().addLast(new StringEncoder());
}
})
// 4.发起连接请求
.connect(new InetSocketAddress("localhost", 8080))
// 阻塞等待连接成功
.sync()
// 6.获取连接后的channel
.channel()
// 发送数据
.writeAndFlush("Hello, World!");
}
}
流程梳理
-
Server:创建服务端启动类 ServerBootstrap
- 创建 NioEventLoopGroup,可以理解成 Selector + Worker线程池
- 选择 ServerSocketChannel 的实现

- 配置 childHandler,用于处理客户端发起的连接建立后 SocketChannel 的请求,ChannelInitializer 会在连接建立后执行初始化
-
Server:监听绑定端口
-
Client:创建客户端启动类 Bootstrap
- 创建 NioEventLoopGroup
- 选择 ServerSocketChannel 的实现
- 配置 handler,用于处理连接建立后 SocketChannel 的请求,ChannelInitializer 会在连接建立后执行初始化
-
Client:connect 发起连接请求,sync 会同步阻塞,等待连接建立
-
连接建立成功后,就会执行服务端、客户端的 ChannelInitializer 初始化处理器的配置
-
Client:channel 获取连接建立后的通道,然后开始双方的数据通信,依次经过各个 Handler
模型概念
- Channel 理解为数据的通道,和 NIO 一致
- msg 理解为流动的数据,初始状态是 ByteBuf,经过 Pipeline 的加工,变成其它类型对象,最后输出又变回 ByteBuf
- Handler 理解为数据的处理工序,分 Inbound 入站和 Outbound 出站两类
- 工序可以有多个,多道工序的组合就是 Pipeline
- Pipeline 负责发布事件(读、读取完成…)传播给每个 Handler, Handler 对自己感兴趣的事件进行处理(重写相应的事件处理方法)
- EventLoop 理解为处理数据的工人
- 工人根据 Pipeline 里 Handler 的编排依次处理数据,并且可以为每道工序指定不同的工人
- 一个工人可以管理多个 Channel 的 IO 操作,并且一旦某个工人负责了某个 Channel,就会绑定负责到底
- 工人既可以执行 IO 操作,也可以进行任务处理
- 每位工人有相应的任务队列,队列里可以堆放多个 Channel 的待处理任务(分普通任务、定时任务)
EventLoop
EventLoop
事件循环对象,本质是一个单线程的执行器,同时维护了一个 Selector。里面有 run 方法处理 Channel 上源源不断的 IO 事件。
- EventLoop 最底层继承自 ExecutorService,因此具有线程池的所有方法
- EventLoop 间接继承自 Netty 的 OrderedEventExecutor,因此存在父子关系
- inEventLoop(thread) 判断一个线程是否属于当前 EventLoop
- parent() 获得自己的父 EventLoop
- EventLoop 实现类继承了 SingleThreadEventLoop,因此实际上又是个单线程
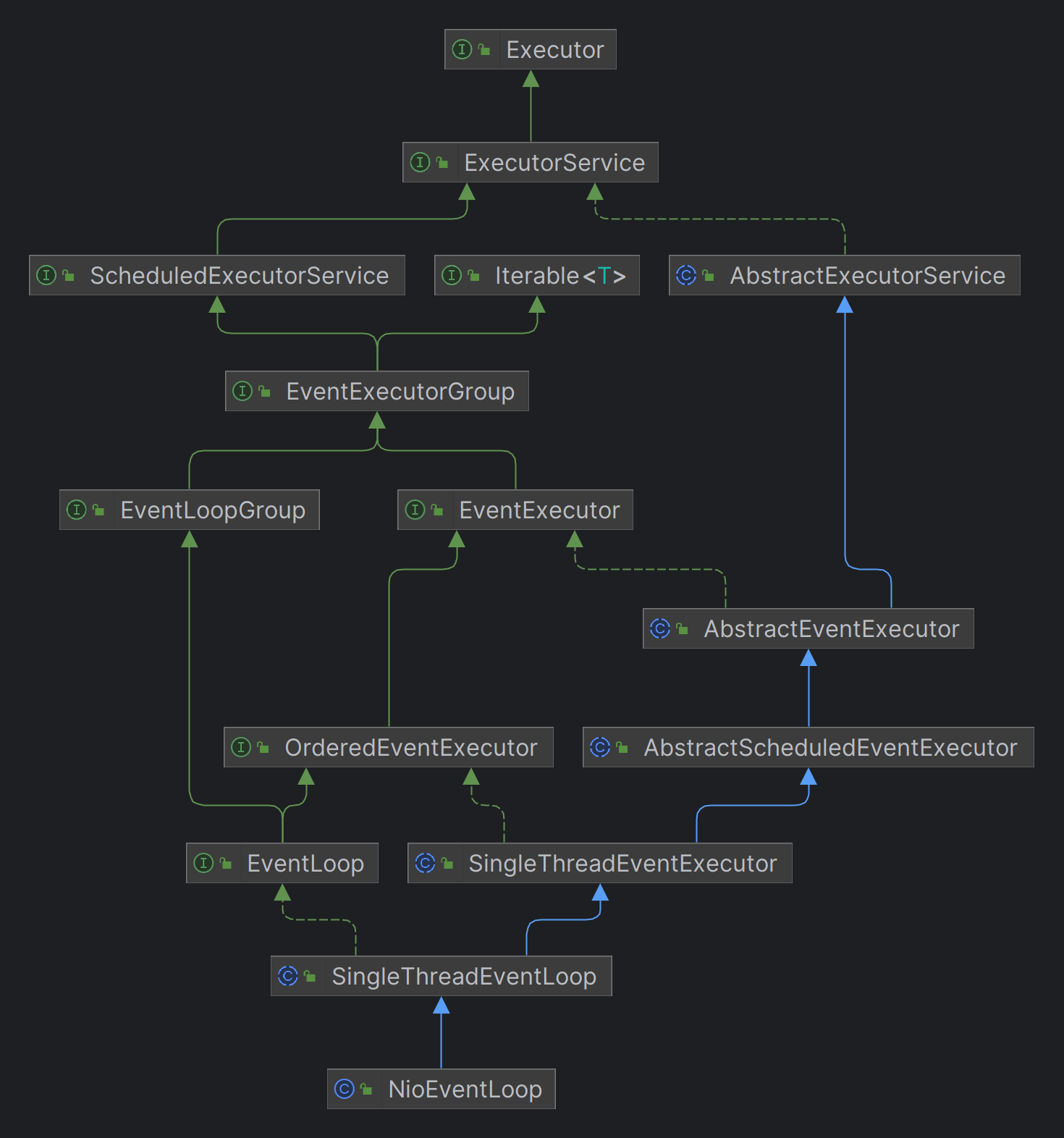
EventLoopGroup
EventLoopGroup 是一组 EventLoop(),Channel 一般会调用 EventLoopGroup 的 register 方法来绑定其中一个 EventLoop,后续这个 Channel 上的 IO 事件都由此 EventLoop 来处理,保证了 IO 事件处理时的线程安全。
- 继承自 Netty 的 MultithreadEventExecutorGroup -> EventExecutorGroup,
Set<EventExecutor> readonlyChildren即 EventLoop 组 - 实现了 Iterable 提供遍历 EventLoop 的能力,实现上就是返回
readonlyChildren的迭代器 - next() 获取集合内的下一个 EventLoop
所以其实可以直接向 EventLoop 提交任务,可以用来执行耗时较长的任务,细分功能:
NioEventLoopGroup workers = new NioEventLoopGroup(2);
log.debug("start...");
Thread.sleep(2000);
workers.execute(() -> {
log.debug("Task...");
});
Thread.sleep(2000);
workers.scheduleAtFixedRate(() -> {
log.debug("Scheduled Task...");
}, 0, 1, TimeUnit.SECONDS);
优雅关闭
EventExecutorGroup#shutdownGracefully方法首先切换 EventLoopGroup 到关闭状态从而拒绝新的任务的加入,然后在任务队列的任务都处理完成后,停止线程的运行。从而确保整体应用是在正常有序的状态下退出的。
绑定 Channel
addLast 在添加 Handler 时,还可以指定执行的线程池,在 Pipeline 加工数据时就会从指定的线程池里取 Worker 去加工数据。
DefaultEventLoopGroup group = new DefaultEventLoopGroup(2);
new ServerBootstrap()
.group(new NioEventLoopGroup(1), new NioEventLoopGroup(2))
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<>() {
@Override
protected void initChannel(Channel channel) throws Exception {
channel.pipeline().addLast("handler1", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug(msg.toString());
ctx.fireChannelRead(msg);
}
}).addLast(group, "handler2", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug(msg.toString());
}
});
}
})
.bind(8080);
执行结果:
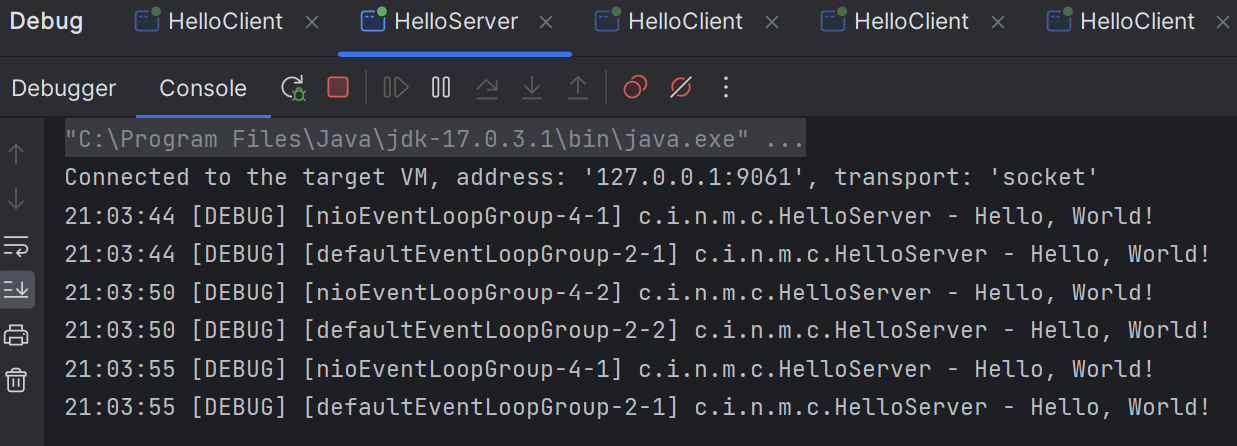
可以看到,NioEventLoopGroup 的两个工人轮流在第一道工序处理,DefaultEventLoopGroup 的两个工人轮流在第二道工序处理。即工人与 channel 之间进行了绑定,但中途是可以换人处理的。
原理
关键代码 io.netty.channel.AbstractChannelHandlerContext#invokeChannelRead()
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
// 下一个 handler 的事件循环是否与当前的事件循环是同一个线程
EventExecutor executor = next.executor();
// 是,直接调用
if (executor.inEventLoop()) {
next.invokeChannelRead(m);
}
// 不是,将要执行的代码作为任务提交给下一个事件循环处理(换人)
else {
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
- 如果两个 handler 绑定的是同一个线程,那么就直接调用
- 否则,把要调用的代码封装为一个任务对象,由下一个 handler 的线程来调用
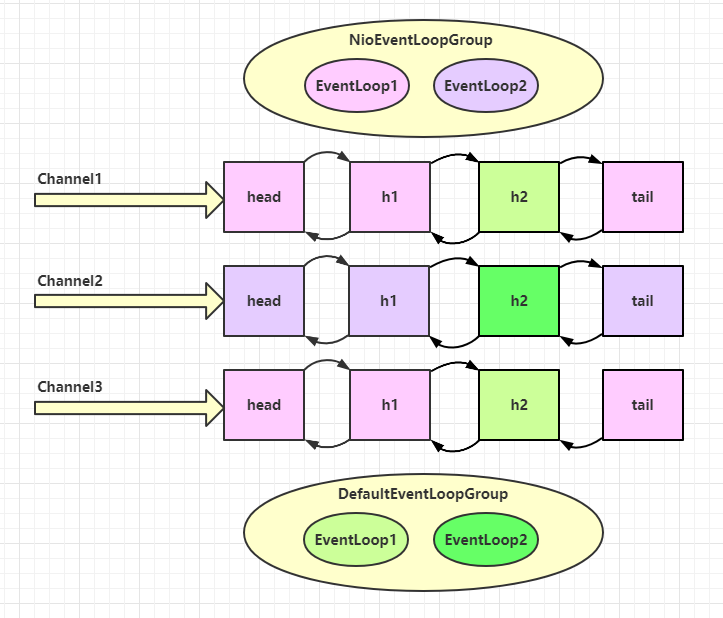
Channel
Channel 比较简单,常用 API 如下:
- sync 同步等待 channel 操作
- addListener 是异步监听 channel 操作
- close() 关闭 channel
- closeFuture() 用来处理 channel 的关闭
- pipeline() 添加处理器
- write() 将数据写入
- writeAndFlush() 将数据写入并刷出
ChannelFuture
将客户端代码拆解来看:
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel channel) throws Exception {
channel.pipeline().addLast(new StringEncoder());
}
})
.connect(new InetSocketAddress("localhost", 8080));
log.debug("{}", channelFuture.channel());
channelFuture.sync();
log.debug("{}", channelFuture.channel());
channelFuture.channel().writeAndFlush("Hello, World!");
connect() 连接是个异步方法,并不会阻塞主线程,因此在 sync() 方法之前,日志打印的 channel 是个未连接的通道对象[id: 0x2e1884dd]。而 sync() 方法就是同步等待连接建立成功,因此第二个日志打印的 channel 就是个已连接的通道[id: 0x2e1884dd, L:/127.0.0.1:57191 - R:/127.0.0.1:8080]。
除了用 sync() 方法让异步操作同步以外,还可以使用回调的方式:
log.debug("{}", channelFuture.channel());
channelFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture channelFuture) throws Exception {
log.debug("{}", channelFuture.channel());
}
});
ChannelFutureListener 会在连接建立时被调用,执行 operationComplete 方法,因此第一个日志打印的是未建立连接的 channel,而第二个日志打印 [id: 0x749124ba, L:/127.0.0.1:57351 - R:/127.0.0.1:8080],即已经连接成功的 channel。同时从线程名也可以看出 listener 的回调是由 NioEventLoopGroup 里的线程执行的。
CloseFuture
同样的,关闭也有两种方式:
// 方法 1:直接异步关闭
channel.close();
// 方法 2:Future监听器
ChannelFuture closeFuture = channel.closeFuture();
log.debug("{}", closeFuture.getClass());
closeFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
group.shutdownGracefully();
}
});
close() 方法会异步去关闭 channel,而 CloseFuture 配合监听器模式可以在关闭后自动执行回调,做一些后置的清理工作,让事件组处理完手上的工作后不再接收新任务,使得程序结束更加优雅。
Future & Promise
在异步处理时,经常用到 Future 和 Promise 这两个接口。Netty 中的 Future 继承自 JDK 中的 Future,而 Promise 又继承自 Netty 的 Future,做了进一步的扩展。主要的区别在于:
- JDK Future 只能同步等待任务结束(成功/失败)才能得到结果
- Netty Future 可以同步等待任务结束拿到结果,也可以异步方式得到结果,但都要等任务结束
- Netty Promise 不仅有 Netty Future 的功能,而且脱离了任务独立存在,只作为两个线程间传递结果的容器
| 功能/名称 | JDK Future | Netty Future | Promise |
|---|---|---|---|
| cancel | 取消任务 | - | - |
| isCanceled | 任务是否取消 | - | - |
| isDone | 任务是否完成,不能区分成功失败 | - | - |
| get | 获取任务结果,阻塞等待 | - | - |
| getNow | - | 获取任务结果,非阻塞,还未产生结果时返回 null | - |
| await | - | 等待任务结束,如果任务失败,不会抛异常 | - |
| sync | - | 等待任务结束,如果任务失败,抛出异常 | - |
| isSuccess | - | 判断任务是否成功 | - |
| cause | - | 获取失败信息,非阻塞,如果没有失败,返回null | - |
| addLinstener | - | 添加回调,异步接收结果 | - |
| setSuccess | - | - | 设置成功结果 |
| setFailure | - | - | 设置失败结果 |
下面看几个示例:
JDK Future
ExecutorService service = Executors.newFixedThreadPool(2);
Future<Integer> future = service.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("执行计算");
Thread.sleep(1000);
return 50;
}
});
// 主线程同步阻塞,等待结果
log.debug("结果:{}", future.get());
Netty Future
EventLoop eventLoop = new NioEventLoopGroup().next();
Future<Integer> future = eventLoop.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("执行计算");
Thread.sleep(1000);
return 70;
}
});
// 1. 同步等待
log.debug("结果:{}", future.get());
// 2. 异步回调,获取结果
future.addListener(new GenericFutureListener<Future<? super Integer>>(){
@Override
public void operationComplete(Future<? super Integer> future) throws Exception {
log.debug("接收结果: {}", future.getNow());
}
});
Netty Promise
EventLoop eventLoop = new NioEventLoopGroup().next();
// 可以主动创建 promise 这个结果容器
DefaultPromise<Integer> promise = new DefaultPromise<>(eventLoop);
new Thread(() -> {
log.debug("开始计算...");
try {
Thread.sleep(1000);
int i = 1 / 0;
// 填充成功的结果
promise.setSuccess(80);
} catch (Exception e) {
e.printStackTrace();
// 填充失败的结果
promise.setFailure(e);
}
}).start();
// 1. 同步等待
log.debug("结果: {}", promise.get());
// 2. 异步回调,获取结果
promise.addListener(new GenericFutureListener<Future<? super Integer>>() {
@Override
public void operationComplete(Future<? super Integer> future) throws Exception {
log.debug("结果是: {}", promise.getNow());
}
});
Promise 的 get() 和 sync() 都可以同步等待执行结果,如果出现异常都会抛出,get() 会在外面再多包一层。await() 同样也是同步等待,但如果执行失败不会抛出异常。另外需要注意执行多个任务时要注意 Promise 的同步阻塞,防止死锁等待。
Handler & Pipeline
ChannelHandler 用来处理 Channel 上的各种事件,分入站、出站两类。所有 ChannelHandler 被连成一串,就是 Pipeline 管道流水线。
- 入站处理器通常是 ChannelInboundHandlerAdapter 的子类,用于读取客户端发送的数据,计算结果
- 出站处理器通常是 ChannelOutboundHandlerAdapter 的子类,用于对计算结果进行加工回复
这里的概念可以理解成:ByteBuf 是原材料,经过 Pipeline 里面各个 ChannelHandler(先入站、后出站) 处理后返回给客户端。
我们可以用 EmbeddedChannel 测试 Handler 的处理顺序:
public static void main(String[] args) {
// 入站1
ChannelInboundHandlerAdapter h1 = new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("1");
super.channelRead(ctx, msg);
}
};
// 入站2
ChannelInboundHandlerAdapter h2 = new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("2");
super.channelRead(ctx, msg);
}
};
// 出站1
ChannelOutboundHandlerAdapter h3 = new ChannelOutboundHandlerAdapter() {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("3");
super.write(ctx, msg, promise);
}
};
// 出站2
ChannelOutboundHandlerAdapter h4 = new ChannelOutboundHandlerAdapter() {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("4");
super.write(ctx, msg, promise);
}
};
EmbeddedChannel channel = new EmbeddedChannel(h1, h2, h3, h4);
// 模拟入站操作
channel.writeInbound(ByteBufAllocator.DEFAULT.buffer().writeBytes("hello".getBytes()));
// 模拟出站操作
channel.writeOutbound(ByteBufAllocator.DEFAULT.buffer().writeBytes("world".getBytes()));
}
执行结果为:

由此我们可知,ChannelInboundHandlerAdapter 是按照 addLast 的顺序执行的,而 ChannelOutboundHandlerAdapter 是按照 addLast 的逆序执行的。ChannelPipeline 的实现是一个 ChannelHandlerContext(包装了 ChannelHandler) 组成的双向链表。
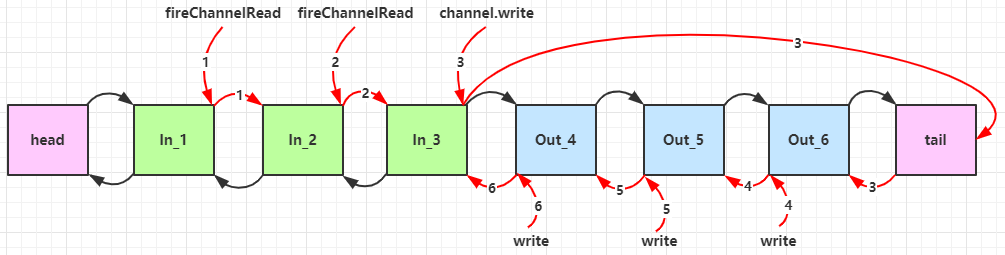
- 入站处理器中,
super.channelRead(ctx, msg)实际执行了ctx.fireChannelRead(msg)- 作用是调用下一个入站处理器
- 不调用则不会进入下一个入站处理器
- 出站处理器中,
super.write(ctx, msg, promise)实际执行了ctx.write(msg, promise)- 作用是调用下一个出站处理器
- 不调用则不会进入下一个出站处理器
- 出站处理器中,也可以执行
ctx.channel().write(msg)触发其它处理器- 但会从尾部 tail 开始触发后续出站处理器的执行
- 而
ctx.write(msg)是从当前节点找上一个出站处理器
ByteBuf
ByteBuf 是 Netty 提供的用于处理字节数据的缓冲区类,是 Netty 的核心组件之一。提供了丰富的 API,用于操作字节数据,包括读取、写入、复制、切片等操作。
特点
- 灵活的内存分配:ByteBuf 支持自动扩容,并且使用池化技术分配内存,避免频繁地创建和销毁缓冲区,提高了内存利用率
- 零拷贝:ByteBuf 支持零拷贝技术,可以直接访问 OS 底层数据,避免了数据在应用程序和内核空间之间的复制
- 读写索引分离:ByteBuf 有独立的读索引和写索引,可以实现零拷贝的同时保持读写操作的独立性
- 引用计数:ByteBuf 使用引用计数来跟踪缓冲区的引用次数,当引用计数为零时将被自动释放,避免了内存泄漏
- 可组合和复合:ByteBuf 可以被组合成更大的数据结构,也可以被拆分成多个小的数据结构,支持复杂的数据处理需求
创建
Netty 创建的 ByteBuf 既可以使用直接内存,也可以使用堆内存,并且默认开启了池化技术。
// 默认使用直接内存
ByteBuf directBuf1 = ByteBufAllocator.DEFAULT.buffer();
System.out.println(directBuf1.getClass());
// 默认方法实际调用的这一层
ByteBuf directBuffer2 = ByteBufAllocator.DEFAULT.directBuffer();
System.out.println(directBuffer2.getClass());
// 指定使用堆内存
ByteBuf heapBuffer = ByteBufAllocator.DEFAULT.heapBuffer();
System.out.println(heapBuffer.getClass());
// Handler 中可以使用 context 创建
ByteBuf buf = channelHandlerContext.alloc().buffer();
直接内存 vs 堆内存
- 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
- 直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
池化 vs 非池化
- 没有池化,则每次都要创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
- 有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
在 Netty 4.1 版本之后,除了 Android 平台默认实现都是开启池化的,可以通过环境变量/VM参数指定是否池化:-Dio.netty.allocator.type={unpooled|pooled}
结构
ByteBuf 的内存区域可以分为四个部分,通过若干个索引分割:
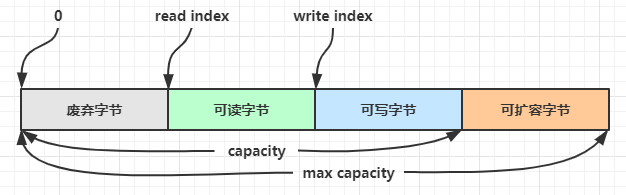
最开始读写指针都在 0 位置
- Reader Index 读索引:
readerIndex 是一个指针,表示下一个被读取的字节的位置。从 ByteBuf 中读取数据时,readerIndex 会随之移动。可以通过
byteBuf.readerIndex()获取。 - Writer Index 写索引:
writerIndex 是一个指针,表示下一个可以被写入数据的位置。向 ByteBuf 中写入数据时,writerIndex 会随之移动。可以通过
byteBuf.writerIndex()获取。 - Capacity 容量:
capacity 表示 ByteBuf 的总容量,即它可以存储的最大字节数。当 writerIndex 达到 capacity 时,ByteBuf 需要重新分配更大的内存来扩容。可以通过
byteBuf.capacity()获取。 - Max Capacity 最大容量:
maxCapacity 是 ByteBuf 的最大容量,即它能够动态扩容的最大限制。默认是 Integer.MAX_VALUE,可以通过
byteBuf.maxCapacity()获取。 - Reference Count 引用计数:
ByteBuf 使用引用计数来跟踪缓冲区的引用次数。当引用计数为零时,ByteBuf 内存将被释放。基于 ReferenceCounted 接口实现,可以通过
byteBuf.refCnt()获取
读写
写方法,写指针会随写入字节数移动;类似的有对应的读方法(write->read),读指针随读取字节数移动。
| 方法签名 | 含义 | 备注 |
|---|---|---|
| writeBoolean(boolean value) | 写入 boolean 值 | 用一字节 01|00 代表 true|false |
| writeByte(int value) | 写入 byte 值 | |
| writeShort(int value) | 写入 short 值 | |
| writeInt(int value) | 写入 int 值 | Big Endian,即 0x250,写入后 00 00 02 50 |
| writeIntLE(int value) | 写入 int 值 | Little Endian,即 0x250,写入后 50 02 00 00 |
| writeLong(long value) | 写入 long 值 | |
| writeChar(int value) | 写入 char 值 | |
| writeFloat(float value) | 写入 float 值 | |
| writeDouble(double value) | 写入 double 值 | |
| writeBytes(ByteBuf src) | 写入 netty 的 ByteBuf | |
| writeBytes(byte[] src) | 写入 byte[] | |
| writeBytes(ByteBuffer src) | 写入 nio 的 ByteBuffer | |
| int writeCharSequence(CharSequence sequence, Charset charset) | 写入字符串 |
::: tip
- 未指明返回值的写方法,其返回值都是 this,因此支持链式调用
- 一系列以 set 开头的写方法可以修改指定位置的数据,不改变写指针位置
- 一系列以 get 开头的读方法可以读取指定位置的数据,不改变读指针位置
- 类似 NIO 的 ByteBuffer,
byteBuf.mark[Writer|Reader]Index、byteBuf.reset[Writer|Reader]Index可以标记、重置读写指针 - 网络传输,默认习惯是 Big Endian
:::
扩容机制
- 如果写入后数据大小未超过 4MB,则每次容量翻倍
- 如果写入后数据大小超过 4MB,则每次增加 $4MB * n$,$n$ 取决于容量足够即可,目的是避免内存浪费
- 扩容的大小不能超过 max capacity
内存回收
基于堆外内存的 ByteBuf 实现最好是手动来释放,而不是等 GC 垃圾回收。
- UnpooledHeapByteBuf 使用 JVM 内存,只需等 GC 回收内存即可
- UnpooledDirectByteBuf 使用直接内存,需要特殊的方法来回收内存
- PooledByteBuf 及其子类使用了池化机制,需要更复杂的规则来回收内存
回收内存的源码实现,可以关注 protected abstract void deallocate()方法的不同实现。
原理上,Netty 采用了引用计数法来控制回收内存,每种 ByteBuf 都实现了 ReferenceCounted 接口:
- 每个 ByteBuf 对象的初始计数为 1
- 调用
byteBuf.release()方法计数减 1 - 调用
byteBuf.retain()方法计数加 1 - 当计数为 0 时,底层内存会被回收,这时即使 ByteBuf 对象还在,其各个方法均无法正常使用
释放规则
基本规则是,谁是最后使用者,谁负责 release !
- 起点,对于 NIO 实现来讲,在 io.netty.channel.nio.AbstractNioByteChannel.NioByteUnsafe#read 方法中首次创建 ByteBuf 放入 pipeline(line 163 pipeline.fireChannelRead(byteBuf))
- 入站 ByteBuf 处理原则
- 对原始 ByteBuf 不做处理,调用 ctx.fireChannelRead(msg) 向后传递,这时无须 release
- 将原始 ByteBuf 转换为其它类型的 Java 对象,这时 ByteBuf 就没用了,必须 release
- 如果不调用 ctx.fireChannelRead(msg) 向后传递,那么也必须 release
- 注意各种异常,如果 ByteBuf 没有成功传递到下一个 ChannelHandler,必须 release
- 假设消息一直向后传,那么 TailContext 会负责释放未处理消息(原始的 ByteBuf)
- 出站 ByteBuf 处理原则
- 出站消息最终都会转为 ByteBuf 输出,一直向前传,由 HeadContext flush 后 release
- 异常处理原则
- 有时候不清楚 ByteBuf 被引用了多少次,但又必须彻底释放,可以循环调用 release 直到返回 true
零拷贝
和 OS 里面的零拷贝意义略有不同,Netty 的零拷贝指的是对 ByteBuf 的复制、拼接在底层没有发生内存的拷贝,还是使用原来的那块内存区域,只不过新增了一些指针来维护不同的实例。
切片
byteBuf.slice()对 ByteBuf 进行切片,并不发生内存复制,切片后的多个 ByteBuf 各自维护独立的 read,write 指针。
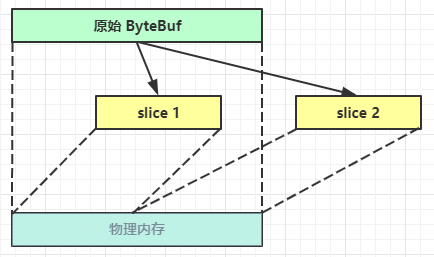
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer(10);
buf.writeBytes(new byte[]{'a','b','c','d','e','f','g','h','i','j'});
log(buf);
// 切片后调用 retain 防止被释放
ByteBuf slice = buf.slice(0, 5);
slice.retain();
// 对 slice 写数据也会改变原来的 buf,因为底层是同一块内存区域
slice.setByte(4, 'x');
log(slice);
// 使用完毕要注意主动释放
slice.release();
复制
byteBuf.duplicate()截取原始 ByteBuf 的所有内容,不发生内存拷贝,仅新增维护指针。
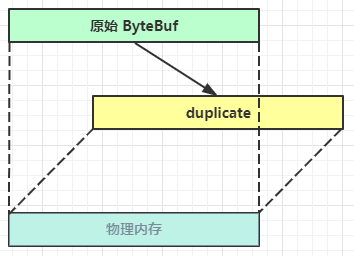
byteBuf.copy()则是执行了深拷贝,无论读写都和原 ByteBuf 无关。
组合
CompositeByteBuf 是一个组合的 ByteBuf,内部维护了一个 Component 数组,每个 Component 管理一个 ByteBuf,记录了这个 ByteBuf 相对于整体偏移量的信息,代表着整体中某一段的数据。
- 优点,对外是一个虚拟视图,组合这些 ByteBuf 不会产生内存复制
- 缺点,复杂了很多,多次操作会带来性能的损耗
CompositeByteBuf buffer = ByteBufAllocator.DEFAULT.compositeBuffer();
buffer.addComponents(true, buf1, buf2);
log(buffer);
Unpooled
Unpooled 是一个工具类,提供了非池化的 ByteBuf 创建、组合、复制等操作,例如wrappedBuffer用于包装 ByteBuf,并且底层不会发生拷贝。
// 当包装 ByteBuf 个数超过一个时, 底层使用了 CompositeByteBuf
ByteBuf buf3 = Unpooled.wrappedBuffer(buf1, buf2);
// 也可以包装普通字节数组
ByteBuf buf4 = Unpooled.wrappedBuffer(new byte[]{1, 2, 3}, new byte[]{4, 5, 6});
评论加载中。如果这里长期空白,请检查 giscus.app / GitHub 是否可访问。