Java 基础
数据类型 1. 引用数据类型 2. 基本数据类型 4大类8种 (1 2 4 8) + 自动类型转换:类型范围小的变量,可以直接赋值给类型范围大的变量 byte short (char) int long float double + 在
数据类型
- 引用数据类型
- 基本数据类型 4大类8种 (1-2-4-8)

-
自动类型转换:类型范围小的变量,可以直接赋值给类型范围大的变量

byte --> short (char) --> int --> long --> float --> double -
在表达式中,小范围类型的变量会自动转换成较大范围的类型再运算
byte, short, char --> int --> long --> float --> double- 最终结果类型由表达式中的最高类型决定
- 在表达式中,byte、short、char 直接转换成int类型参与运算的
-
强制类型转换:可以强行将类型范围大的变量、数据赋值给类型范围小的变量

- 强制类型转换可能造成数据(丢失)溢出
- 浮点型强转成整型,直接丢掉小数部分,保留整数部分返回
运算符
-
短路逻辑运算符

-
逻辑与
&, 逻辑或|: 无论左边是false还是true,右边都要执行
代码块
- 代码块
{}是类的5大成分之一(成员变量、构造器、方法、代码块、内部类) - 静态代码块
static{ }- 通过static关键字修饰,随着类的加载而加载,自动触发,只执行一次
- 使用场景:在类加载的时候做一些静态数据初始化的操作,以便后续使用
- 构造代码块(很少使用)
{ }- 每次创建对象调用构造器前,都会执行该代码块
- 使用场景:初始化实例资源
单例模式
-
饿汉单例:
- 在用类获取对象时,对象已经提前为你创建好了
- 设计步骤:定义类,构造器私有,定义静态变量存储单例对象
public static SingleInstance { // 属于类,与类一起仅加载一次 public static SingleInstance instance = new SingleInstance(); private SingleInstance() { System.out.println("创建了一个对象"); } } -
懒汉单例:
- 在真正需要该对象时,才去创建一个对象(延迟加载对象)
- 设计步骤:定义类,构造器私有,定义静态变量存储对象,提供一个返回单例对象的方法
public static SingleInstance { // 类加载时初始为null public static SingleInstance instance; private SingleInstance() {} public static SingleInstance getInstance(){ if(instance == null) instance = new SingleInstance(); return instace; } }
继承
- 子类中访问成员满足就近原则,先找子类,子类没有找父类,父类没有报错
- 子类可以直接使用父类的静态成员(共享)
- 方法重写
- 私有方法不能被重写。但可以定义相同签名的方法。
- 子类重写父类方法时,访问权限必须大于或等于父类
缺省 < protected < public - 子类不能重写父类的静态方法
- 权限修饰符
private < 缺省 < protected < public
- final 修饰符
- 修饰类,表明该类不能被继承
- 修饰方法,表明该方法不能被重写
- 修饰变量,表明该变量不能被重新赋值
- 基本类型 – 数据值不能改变
- 引用类型 – 存储的地址值不能改变(地址指向的对象可变)
接口
- 一种约束规范
- 接口中的变量默认都是
public static final - 接口中的方法默认都是
public abstract - JDK 8/9 新增特性:
-
- 默认方法 - default修饰,自动public,需用接口实现类的对象来调用
-
- 静态方法 - static修饰,自动public,需用接口本身的接口名调用
-
- 私有方法 - private修饰,只能在 接口中被其它的方法访问
-
- 一个类同时继承父类和实现接口中的同名方法,优先使用父类的
多态
- 访问特点:
- 方法调用:编译看左边,运行看右边
- 变量调用:编译看左边,运行也看左边
- 强制类型转换
- 可以转换成真正的子类型,从而调用子类的独有功能
- 强转前尽量使用
instanceof判断对象的真实类型再进行强转
内部类
1. 静态内部类
static修饰,属于外部类这个类- 创建格式:
Outer.Inner in = new Outer.Inner() - 可以直接访问外部类静态对象
- 不可以直接访问外部类实例成员
2. 成员内部类
无 static修饰,属于外部类的对象- 创建格式:Outer.Inner in = new Outer().new Inner();
- 可以直接访问外部类静态对象
- 可以直接访问外部类实例成员(必须先有外部类对象,才能有成员内部类对象)
class People{
private int hearbeat = 150;
public class Heart{
private int hearbeat = 110;
public void show(){
int hearbeat = 78;
System.out.println(hearbeat); // 78
System.out.println(this.hearbeat); // 110
System.out.println(People.this.hearbeat); // 150
}
}
}
3. 局部内部类
- 放在方法、代码块、构造器等执行体中
- 类文件名:
Outer$NInner.class - 鸡肋
4. 匿名内部类
- 本质上是没有名字的局部内部类
- 既是一个类,也代表一个对象(new的类型的子类类型),写出来就会产生一个匿名内部类的对象
- 可以直接作为对象传给方法
- 作用:方便创建子类对象,简化代码编写
- 创建格式:
new 类/抽象类名/接口( ){ 重写方法 }
- Lambda表达式:
- 一个匿名函数,是一段可以传递的代码
- 用于简化函数式接口的匿名内部类的写法形式
- 函数式接口:有且仅有一个抽象方法的接口,通常加上@FunctionalInterface注解
字符串
两种创建过程
""双引号创建字符串:会先判断常量池里面是否有相同的字符串,若有则直接指向该地址new关键字不论常量池中是否已经有该串,都会在堆中开辟新的内存空间存放该字符串
此外,String::intern() 方法可以主动将字符串放入堆中的字符串常量池,并返回常量池中的该对象。
疑难点
- 问题:下列代码的运行结果是?

// 先在堆的字符串常量池里创建"abc"的串,然后new再创建一个新串赋给s2
String s2 = new String("abc");
// 由于是双引号,直接指向常量池里的"abc",因此这条语句没有创建新字符串
String s1 = "abc"
// false, s1指向的是常量池里的"abc",s2指向的是堆里的"abc"
System.out.println(s1 == s2)
String s7 = "qwe";
String s8 = "qw";
// 只要不是直接双引号给出的字符串,都是非常量池的。字符串变量拼接的本质是 StringBuilder
String s9 = s8 + "e";
// false, s7指向常量池的"qwe",s9指向堆里的"qwe"
System.out.println(s7 == s9);
String s10 = "asd";
String s11 = "a" + "s" + "d";
// true, 字符串字面量在编译时有优化机制:直接将"a"+"s"+"d"转换为"asd",可以通过class文件确认
// 而s9由于s8是变量,不是字面量,因此没有优化
System.out.println(s10 == s11);
StringBuilder 拼接字符串
String 对象拼接字符串原理 - 每次拼接都会产生新的对象:

StringBuilder 对象拼接字符串原理 - 对同一个对象做修改

- StringBuilder相当于一个容器,拼接、修改更加高效
- StringBuilder只是个工具,最终的目的是得到String
- StringBuffer是StringBuilder的多线程安全版,单线程下StringBuilder效率更高
集合
Collection
-
List: 有序、可重复、有索引
- ArrayList: 底层基于数组,默认长度10,存满时扩容1.5倍
- LinkedList: 底层基于双链表,可模拟栈/ 队列
-
Set: 无序、不重复、无索引
- HashSet:
基于哈希表,底层采用
数组+链表+红黑树实现。哈希表默认长度16,加载因子0.75,每次扩容2倍。相同哈希值的元素构成链表,新元素挂在老元素后面,当链表长度超过8自动转为红黑树。 - LinkedHashSet:
有序,底层
哈希表+双链表记录存储顺序 - TreeSet:
自动排序,底层基于
红黑树实现。必须指定比较规则 (比较器/比较接口)
如果希望 Set 认为两个内容一样的对象是重复的,必须重写对象的
hashCode()和equals()方法 - HashSet:
基于哈希表,底层采用

-
遍历方式:
- 迭代器
Iterator::hasNext, Iterator::next for-each 循环注意集合中存储的是对象的地址,因此修改第三方变量不会影响到集合中的元素- lambda表达式
forEach(Consumer<? super T> action)
遍历时直接用集合删除元素可能出现并发异常,可以通过迭代器删除
- 迭代器
-
Collections 集合工具类
- addAll
- sort
- shuffle
-
不可变集合 ImmutableCollections:
- List.of
- Set.of
- Map.of
Map
-
HashMap:
- 无序,不重复,无索引,值不作要求
- 基于哈希表、数组、红黑树实现
- 基于hashCode()和equals()保证键的唯一
-
LinkedHashMap:
- 按键有序,不重复,无索引,值不作要求
- 基于哈希表、双链表记录存储顺序
-
TreeMap:
- 自动按键排序 ,不重复,无索引,值不作要求
- 底层基于
红黑树实现,必须指定键的比较规则(比较器/比较接口)
-
Properties
- 本质是Map集合,一般代表一个属性文件,存储对象键值对,作为系统配置信息
store(Stream, comments), load(Stream), setProperty, getProperty
Set系列集合的底层就是Map实现的,只是Set集合中的元素只要键数据,不要值数据。

- 遍历方式:
- 键找值:
map.keySet(), map.get(key) - 键值对:
map.entrySet(), entry.getKey(), entry.getValue() - Lambda表达式:
map.forEach(BiConsumer<K, V>)
- 键找值:
泛型
- 自定义泛型类
public class MyGeneric<T> {} - 自定义泛型方法
public <T> void MyFun(T t) {} - 自定义泛型接口
public interface MyInterface<E> {} - 泛型通配符
?可以在使用泛型时代表一切类型
? extends Class泛型上限,限定必须是Class或其子类? super Class泛型下限,限定必须是Class或其父类 - 底层实现上,字节码中的泛型类型都会被擦除
反射
对于任何一个Class对象,可以在运行时得到这个类的全部成分
获取Class对象
- Class.forName(String)
- 类目.class
- 对象.getClass()

获取构造器
- Class::getConstructors([paramTypes]) 获取公有构造器, Class::getDeclaredConstructors([paramTypes]) 获取所有构造器
- Constructor::newInstance() 根据指定构造器创建新对象
- Constructor::setAccessible(boolean) 设置访问检查,实现暴力反射(调用私有构造器,破坏了封装性)
获取成员变量
- Class::getFields(name), Class::getDeclaredFields(name)
- Field::set(object, val), Field::get(obj) 设置/获取成员变量的值
- Field::setAccessible(boolean)
获取方法对象
- Class::getMethods([name, params]), Class::getDeclaredMethods([name, params])
- Method::invoke(obj, args…) 对obj对象调用目标方法,可以获取返回值
- Method::setAccessible(boolean)
Stream 流
文件
File类
- 代表OS的文件/文件夹对象。提供定位、获取文件信息、删除、创建等功能
createNewFilemkdir创建一级目录,mkdirs创建多级目录delete删除文件/空文件夹且不走回收站list返回目录下文件名数组,listFiles返回目录下文件对象数组,仅包括一级
字符集
- 常见字符集:
- ASCII: 1个字节存储1个字符,共128个
- GBK: 包含汉字等字符,一个中文2个字节存储
- Unicode (UTF-8): 一个中文3个字节存储
- 编解码:
- 英文、数字在任何字符集都占1字节,不会乱码
- 编码:
string.getBytes(chatset) - 解码:
String(byte[], charset)
IO 流
-
分类

-
体系

字节流
-
InputStream
read(), read(byte[len]), readAllBytes读取1 / len / 所有字节
-
OutputStream
- 覆盖管道,默认打开文件流会清空,构造器append = true开启附加模式
write(), flush(), close()输出字节流,必须刷新,结束需要关闭资源。close操作包括flush- 一般用 try-with-resource 处理资源 (Closeable/AutoCloseable)
字符流
-
Reader
read(), read(char[len])读取 1 / len 个字符
-
Writer
- 覆盖管道,默认打开文件流会清空,构造器append = true开启附加模式
write(), flush(), close()输出字符流,必须刷新,结束需要关闭资源。close操作包括flush- 一般用 try-with-resource 处理资源 (Closeable/AutoCloseable)
- 使用总结
- 字节流适合一切文件数据的拷贝,包括音视频、文本等
- 字节流不适合读取中文内容输出
- 字符流适合文本文件的读写
缓冲流
- 也称高效流、高级流。自带8KB缓冲区,可以提高原始字节流、字符流读写数据的性能。建议使用缓冲流+字节数组
BufferedInputStream(InputStream)BufferedOutputStream(OutputStream)BufferedReader(Reader),readline()BufferedWriter(Writer),newLine()
转换流
- 把原始的字节流按照指定编码转换
- 字符输入转换流:
InputStreamReader(InputStream, charset) - 字符输出转换流:
OutputStreamWriter(OutputStream, charset) - 建议创建转换流后使用缓冲流进行包装,提高性能
对象字节流 - 序列化
- 以内存为基准,把内存中的对象存储到磁盘文件中,称为对象序列化
- 对象字节输出流:
ObjectOutputStream(OutputStream) oos.writeObject(obj)obj 必须实现Serializable序列化接口
- 以内存为基准,把存储在磁盘文件中的数据恢复成内存中的对象,称为对象反序列化
- 对象字节输入流:
ObjectInputStream(InputStream) ois.readObject(obj)obj 必须实现Serializable序列化接口
transient修饰的成员变量不参与序列化- 通常指定一个序列化版本号,以确保序列化、反序列化的对象保持一致
打印流
- 方便、高效地打印数据到文件中
- 基于字节
PrintStream, 基于字符PrintWriter print(), PrintStream支持写字节,PrintWriter支持写字符System.out就是一个PrintStream对象。可以重定向输出语句到文件中:System.setOut(new PrintStream(File))
IO 库
commons-io:
- IOUtils::copy
- FileUtils::copyFileToDirectory
- FileUtils::copyDirectoryToDirectory
- …
NIO
JDK 1.4 引入了 NIO库,弥补了原来同步阻塞I/O 的不足,它在标准 Java 代码中提供了高速的、面向块的 I/O。
Buffer:缓冲区,包含一些要写入或者要读出的数据。在 NIO 库中,所有数据都是用缓冲区进行处理的,不同于面向流的IO中将数据直接读/写到 Stream 对象中 Channel:通道,可以通过它读取和写入数据。通道是双向的,而流是单向的(InputStream/OutputStream) Selector:可以同时轮询多个 Channel
多线程
多线程的创建
1. 继承Thread类
- 定义任务类继承java.lang.Thread,重写run()方法
- 创建线程对象, 调用Thread::start()启动线程
- 优点:编码简单
- 缺点:不利于扩展,自定义线程无法继承其它类
2. 实现Runnable接口
- 创建Runnable接口匿名内部类,重写run()方法
- 把Runnable交给Thread类处理,调用start()启动线程
- 优点:可以继续继承、实现,扩展性强
- 缺点:多一层包装,线程如果有执行结果不可以直接返回
3. 实现Callable接口
- 定义任务类实现Callable接口,重写call()方法
- 用FutureTask把Callable对象封装成线程任务对象
- 把FutureTask交给Thread类处理调用,start()启动线程
- 线程执行完毕后,通过FutureTask::get()获取任务执行的结果
- 优点:可以继续继承、实现,扩展性强。且可以在线程执行完毕后获取执行结果
- 缺点:编码稍复杂
Thread常用API
- setName, getName
- currentThread() 返回当前正在执行的线程对象的引用
- sleep(long) 让线程休眠指定时间,单位毫秒
- yield, join, interrupt…
线程安全
-
多个线程同时访问同一个共享资源且修改该资源
-
线程同步的核心思想:加锁
- 同步代码块
- synchronized(锁对象)
- 一般把共享资源作为锁对象
- 建议实例方法使用this作为锁对象,静态方法使用类.class对象作为锁对象
- 同步方法
- synchronized 修饰方法
- 底层:实例方法默认对this加锁,静态方法默认对类.class加锁
- Lock锁
- 实现类:ReentrantLock
- lock, unlock
- 同步代码块
-
线程通信
- wait() 让当前线程释放锁并进入等待,直到另一个线程唤醒
- notify(), notifyAll() 唤醒正在等待的单个 / 所有线程
- 必须通过当前同步锁对象进行调用
线程池
-
创建线程的开销很大,可以通过复用线程,提高系统性能
-
线程池接口:
ExecutorService; 实现类:ThreadPoolExecutor;public ThreadPoolExecutor( int corePoolSize, //指定线程池的线程数量 (核心线程) int maximumPoolSize, //指定线程池可支持的最大线程数 (>=核心线程数) long keepAliveTime, //指定临时线程的最大存活时间 TimeUnit unit, //指定存活时间的单位(秒、分、时、天) BlockingQueue<Runnable> workQueue, //指定任务队列 ThreadFactory threadFactory, //指定用哪个线程工厂创建线程 RejectedExecutionHandler handler //指定线程忙,任务满的时候,新任务来了怎么办 )- 新任务提交时的服务顺序:核心线程 -> 任务队列 -> 创建临时线程 -> 拒绝服务
- 如果核心线程都在忙,任务队列也满了,并且还可以创建临时线程,此时才会创建临时线程
- 核心线程、临时线程都在忙,任务队列也满了,新的任务到达时才会开始拒绝服务
- 常用方法:
execute(Runnable), submit(Callable), shutdown(), shutdownNow() - 拒绝策略:
ThreadPoolExecutor.AbortPolicy默认策略,丢弃并抛出RejectedExecutionException异常ThreadPoolExecutor.DiscardPolicy丢弃且不抛异常,不推荐ThreadPoolExecutor.DiscardOldestPolicy抛弃队列中等待最久的任务 然后把当前任务加入队列中ThreadPoolExecutor.CallerRunsPolicy绕过线程池,由主线程直接调用任务的run()方法执行
- 新任务提交时的服务顺序:核心线程 -> 任务队列 -> 创建临时线程 -> 拒绝服务
-
线程池工具类:
Executors通过调用方法返回不同类型的线程池对象newCachedThreadPool()线程数量随着任务增加而增加,如果线程任务执行完毕且空闲了一段时间则会被回收掉newFixedThreadPool(int nThreads)创建固定线程数量的线程池,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程替代它newSingleThreadExecutor()创建只有一个线程的线程池对象,如果该线程出现异常而结束,那么线程池会补充一个新线程newScheduledThreadPool(int corePoolSize)创建一个线程池,可以实现在给定的延迟后运行任务,或者定期执行任务- 底层仍是基于ThreadPoolExecutor实现的
- 最大任务队列长度/线程数量是Integer.MAX_VALUE,可能出现OOM
补充
定时器
- 一种控制任务延时调用,或者周期调用的技术
- 实现方式:
- Timer
- Timer::schedule(task, delay/time, period);
- Timer单线程,处理多个任务按顺序执行,存在延时,和设置定时器的时间有出入
- 可能因为异常导致Timer线程死掉,从而影响后续任务执行
- ScheduledExecutorService
- Executors.newScheduledThreadPool(int corePoolSize)
- ScheduledExecutorService.scheduleAtFixedRate(Runnable, delay, period, unit)
- 基于线程池,某个任何的执行情况不会影响其它定时任务
- Timer
并行与并发
- 并发: CPU分时轮询执行
- 并行: 同一时刻同时执行
线程的生命周期
- Java定义了6中状态:Thread.State::{NEW, RUNNABLE, BLOCKED, WAITING, TIMED_WAITING, TERMINATED}

网络通信
三要素
IP地址
- 操作类
InetAddress - getLocalHost 返回本主机的地址对象
- getByName(host) 得到指定主机(域名/IP)的IP地址对象
- getHostName 返回此IP地址的主机名
- getHostAddress 返回IP地址字符串
- isReachable(timeout) 指定时间ms内是否连通该IP
端口
- 标识主机上的进程,16bit,0-65535
- 周知端口 0-1023:预先定义的知名应用,如HTTP 80,FTP 21
- 注册端口 1024-49151:分配给用户进程/应用程序,如Tomcat 8080,MySQL 3306
- 动态端口 49152-65535
协议
- Ping命令直接基于网络层ICMP协议,无连接,不针对特定端口。与传输层TCP/UDP,或是应用层HTTP等都无关
- Socket是一个调用接口,实际是对TCP/IP协议的封装
- UDP协议的数据包大小限制64KB
UDP 通信
- DatagramPacket 数据包对象
- DatagramPacket(byte[] buf, length, InetAddress, port)
- getLength() 获取实际接受的字节个数
- DatagramSocket 发送者/接收者对象
- DatagramSocket(port)
- send(packet)
- receive(packet)
- 广播 Broadcast
- 使用广播地址 255.255.255.255
- 发送端指定端口,其它主机注册该端口即可
- 组播 Multicast
- 使用组播地址 224.0.0.0 - 239.255.255.255
- 发送端指定组播IP和端口,接收端绑定该组播IP,并注册该端口
- DatagramSocket的子类MulticastSocket::joinGroup负责绑定组播IP
TCP 通信
java.net.Socket基于TCP协议- Socket(host, port)
- Socket::getOutputStream()
- Socket::getInputStream()
- ServerSocket 服务端
- ServerSocket(port)
- ServerSocket::accept() 等待接收客户端的Socket通信连接,连接成功返回Socket对象与客户端建立端到端通信
- 服务端一般使用循环,负责接收客户端Socket管道连接,每接收到一个Socket管道后分配一个独立的线程负责处理它(线程池技术)
异常
异常体系
- Error:系统级别问题、JVM退出等,代码无法控制
- Exception:java.lang包下,称为异常类,表示程序本身可以处理的问题
- RuntimeException及其子类:运行时异常,编译阶段不会报错。如空指针、数组索引越界等
- 除RuntimeException之外的所有异常:编译时异常,编译期必须处理,也称受检异常。如日期格式化异常

异常处理
- throws:用在方法声明上,将方法内部出现的异常抛出给调用者
- try-catch:监视捕获异常,在方法内部自己处理,程序继续执行
- try-catch-finally: 除非JVM崩溃,否则必须执行finally块
- try-with-resource: 自动关闭资源(Closeable/AutoCloseable),即使出现异常
自定义异常
- 定义异常继承 Exception / RuntimeException
- 重写构造器
- 在出现异常的地方主动 throw 自定义异常对象
注解
又称Java标注,对Java中类、方法、变量做标记,然后进行特殊处理
- 自定义注解
@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface Book {
String value();
double price() default 100;
String[] author();
}
-
元注解:对注解类的注解
- @Target:约束注解标记的位置
- ElementType.TYPE 类,接口
- ElementType.FIELD 成员变量
- ElementType.METHOD 成员方法
- ElementType.PARAMETER 方法参数
- ElementType.CONSTRUCTOR 构造器
- ElementType.LOCAL_VARIABLE 局部变量
- @Retention:约束注解的存活范围
- RetentionPolicy.SOURCE 注解只作用在源码阶段,生成的字节码文件中不存在
- RetentionPolicy.CLASS 默认值,注解作用在源码阶段,字节码文件阶段,运行阶段不存在
- RetentionPolicy.RUNTIME 注解作用在源码阶段,字节码文件阶段,运行阶段(开发常用)
- @Target:约束注解标记的位置
-
注解解析
- Annotation: 注解对象
- AnnotatedElement: 注解解析相关方法的接口,所有类成分Class/Method/Field/Constructor均已实现
- getDeclaredAnnotations()
- getDeclaredAnnotation(class)
- isAnnotationPresent(class)
- 解析技巧:注解在哪个成分上,就先拿哪个成分对象
动态代理
- 对业务功能进行代理,类似AOP编程
- Proxy::newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
- InvocationHandler::invoke(Object proxy, Method method, Object[] args)
- 优点:
- 非常灵活,支持任意接口类型做代理,也可以直接为接口本身做代理
- 可以为被代理对象的所有方法做代理
- 不改变方法源码的情况下,实现对功能的增强
- 简化编程,提高可扩展性,提高了开发效率
常用API
BigDecimal
- 解决浮点型运算精度失真问题
- 禁止使用BigDecimal(double)把double值转换为BigDecimal对象,依然存在精度损失风险
- 推荐使用
BigDecimal(String)或BigDecimal.valueOf(Double)的构造方式,自动对精度进行截断处理 - BigDecimal只是手段,目的是Double
枚举
- 枚举类都继承了
java.lang.Enum - 枚举都是最终类,不可以被继承
- 构造器都是私有,对外不能创建对象
- 枚举类相当于多例模式

日期与时间
- Date 日期对象
- Date()
- setTime(), getTime() 时间毫秒值
- SimpleDateFormat
- new SimpleDateFormat(pattern)
- format(Date/time): Date/time -> String
- parse(dateStr): String -> Date
- Calendar 系统此刻日历对象
- Calendar.getInstance()
JDK 8新增日期时间API:
- LocalDate 不包含具体时间的日期
- LocalTime 不包含日期的时间
- LocalDateTime 包含日期和时间
- Instant 时间戳
- DateTimeFormatter 时间格式化和解析
- Duration 计算两个时间间隔
- Period 计算两个日期间隔
- ChronoUnit 针对特定时间单位测量时间差
正则表达式
- Pattern.complie(regex)
- pattern.matcher(String)
- matcher.find()
- matcher.group()
日志
-
优势:可以将系统执行的信息选择性的记录到指定的位置,如控制台、文件、数据库等。并且随时以开关的形式控制是否记录,灵活性好

-
Logback 模块
- logback-core: 核心模块
- logback-classic: log4j 改良版本,完整实现 slf4j API
- logback-access: 与Tomcat和Jetty等Servlet容器集成,提供HTTP访问日志功能
-
使用:
- 日志级别:TRACE < DEBUG < INFO < WARN < ERROR,默认DEBUG
- 配置文件
logback.xml
Logger LOGGER = LoggerFactory.getLogger("Test.class"); LOGGER.debug("log info......"); LOGGER.info("log info......"); LOGGER.trace("a = " + a);
单元测试
- 针对最小的功能单元,即Java中的方法,编写测试代码
- 传统测试方法的缺陷:只能测试main,方法之间相互影响,无法得到测试结果的报告,无法实现自动化测试
- Junit单元测试框架
- 优点:可以灵活选择测试方法,自动生成测试报告
- 使用:
- 导入JUnit
- 编写公共的,无参数无返回值测试方法,并加上@Test注解
- 允许测试
- 测试注解:@Before, @After, @BeforeClass, @AfterClass, @BeforeEach, @AfterEach, @BeforeAll, @AfterAll
XML
- 可扩展标记语言(eXtensible Markup Language),一种数据表示格式
- 纯文本,默认UTF-8编码,可嵌套,经常用于网络传输、配置文件
- XML格式:
- 第一行文档声明
<?xml version="1.0" encoding="UTF-8" ?> - 特殊字符:小于 < 大于 > 和号 & 单引号 ' 引号 "
- 解释器忽略文本:<![CDATA[…内容…]]>
- 第一行文档声明
- XML约束:限定xml文件中的标签以及属性规则
- DTD
<!DOCTYPE 根标签名 PUBLIC/SYSTEM "dtd文件名" "dtd文件位置">不能约束具体数据类型 - SCHEME
<根标签 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://xxx.com" xsi:schemaLocation="http://xxx.xsd">约束更严谨
- DTD
- XML解析
- SAX解析:一行一行解析
- DOM解析:整个文件解析,如JAXP、JDOM、Dom4j、jsoup
- Dom4j API
- XML检索——XPath
- 使用路径表达式来定位元素节点或属性节点
- 基于dom4j和jaxen
- selectSingleNode(exp), selectNodes(exp)
- 四大检索方案:
- 绝对路径:
/根元素/子元素/孙元素从根元素开始,一级一级向下查找,不能跨级 - 相对路径:
./子元素/孙元素从当前元素开始,一级一级向下查找,不能跨级 - 全文检索:
//name//father/son//father//grandson直接全文搜索所有的name元素并打印 - 属性查找:
//@attr//ele[@attr]//ele//[@attr=val]查找属性/含有指定值的属性的元素
- 绝对路径:
设计模式
- 工厂模式:
- 对象通过工厂的方法创建返回
- 可以为该对象进行加工和数据注入,实现类与类之间的解耦操作
- 装饰模式
- 创建新类,包装原始类
- 可以在不改变原有类的基础上,动态扩展一个类的功能
内存图
- JVM内存区:虚拟机栈、堆、方法区、本地方法栈、程序计数器

-
基本内存分配:
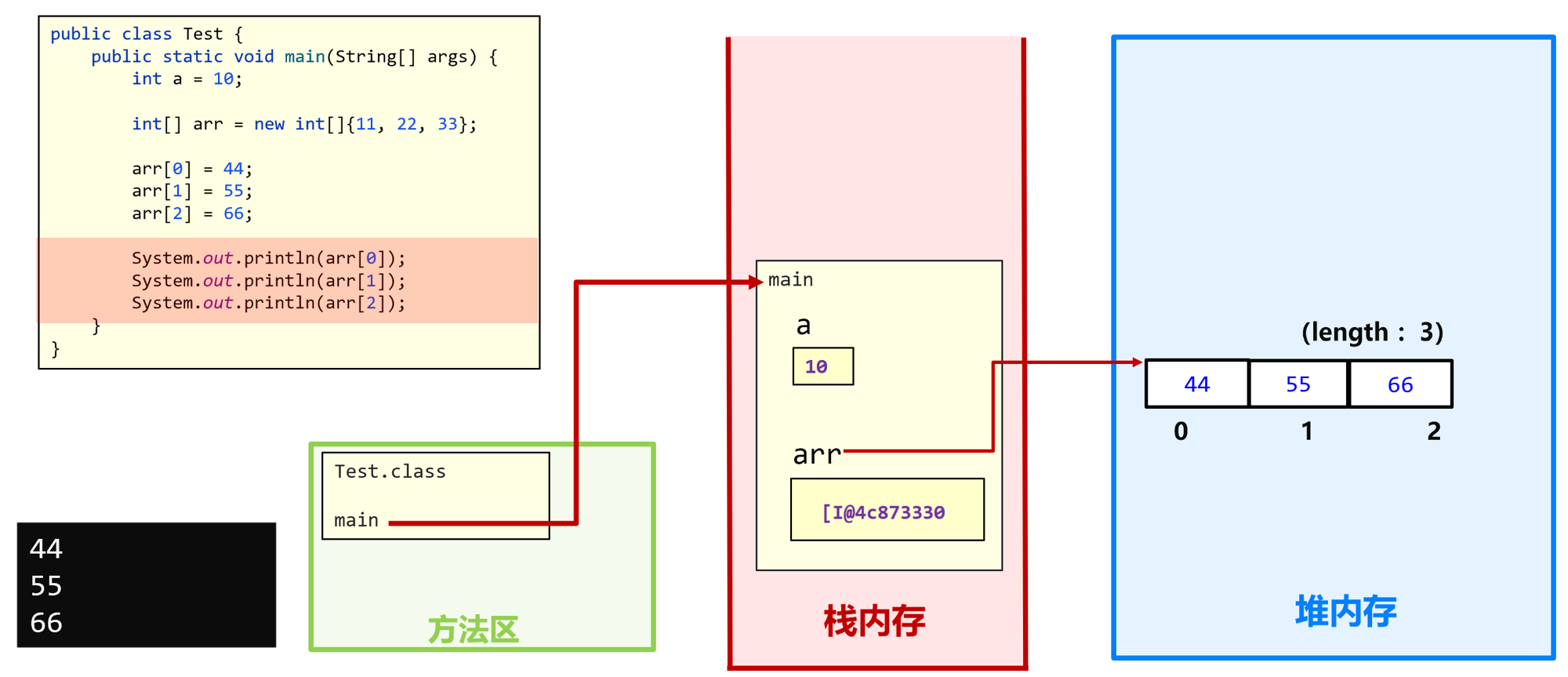
- 方法区存放加载的类信息
- 栈(栈帧): 局部变量表
- 堆: new出来的对象实例 (如数组)
-
两个引用指向同一对象
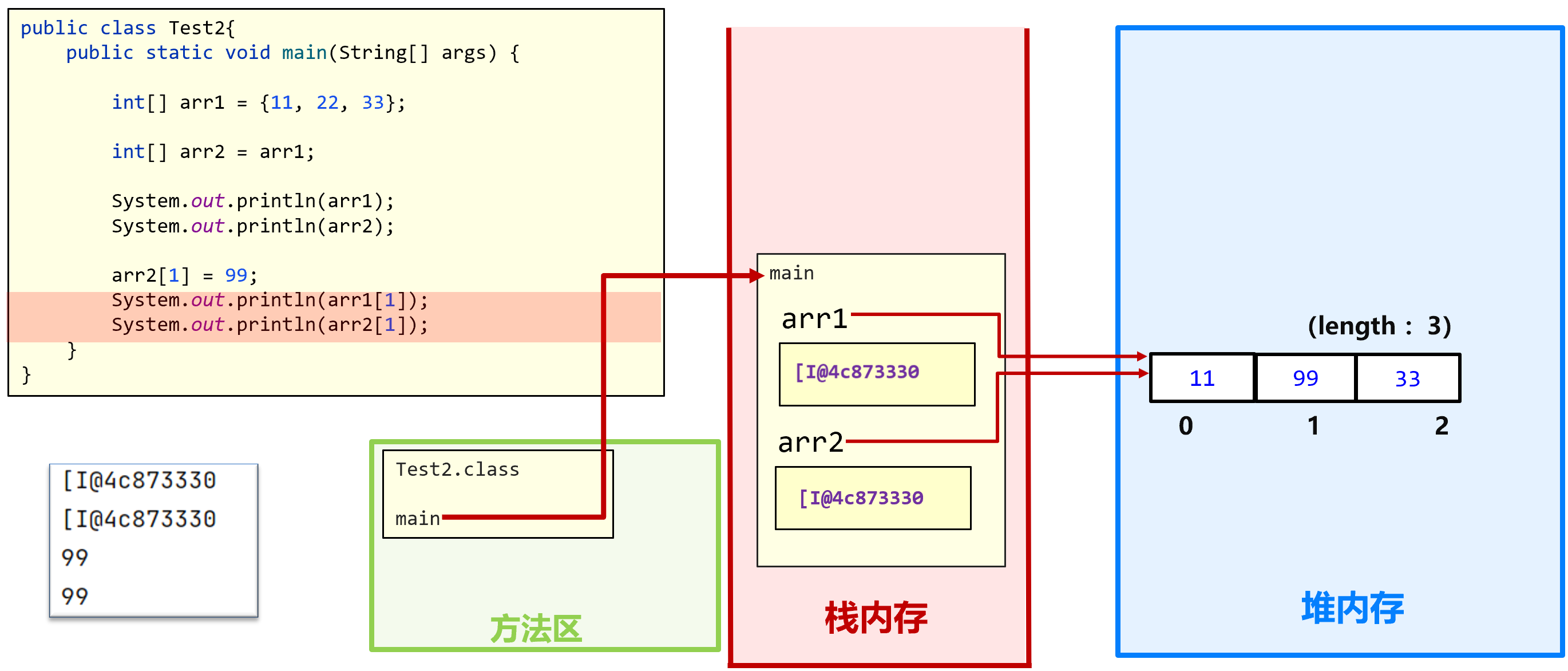
- 栈内存中两个引用的地址值指向堆中同一块内存区
- 利用引用修改堆中数据后,所有引用指向该内存区域的数据都会反映出来
-
Java参数传递机制
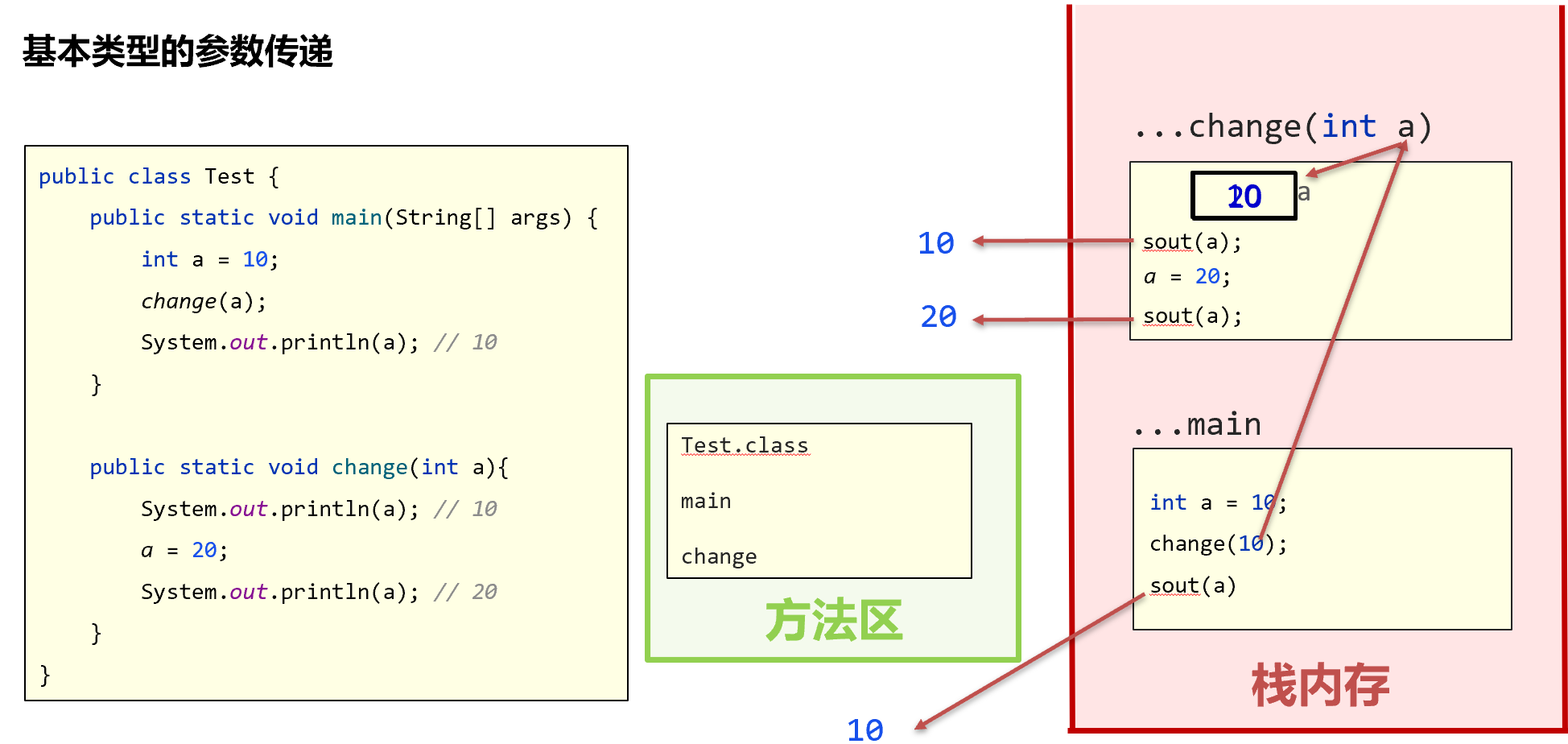

- 无论基本类型还是引用类型,都是值传递
- 基本类型传递的是本身的数据值
- 引用类型的值是指向堆内存的某个地址
- 两个对象内存图;
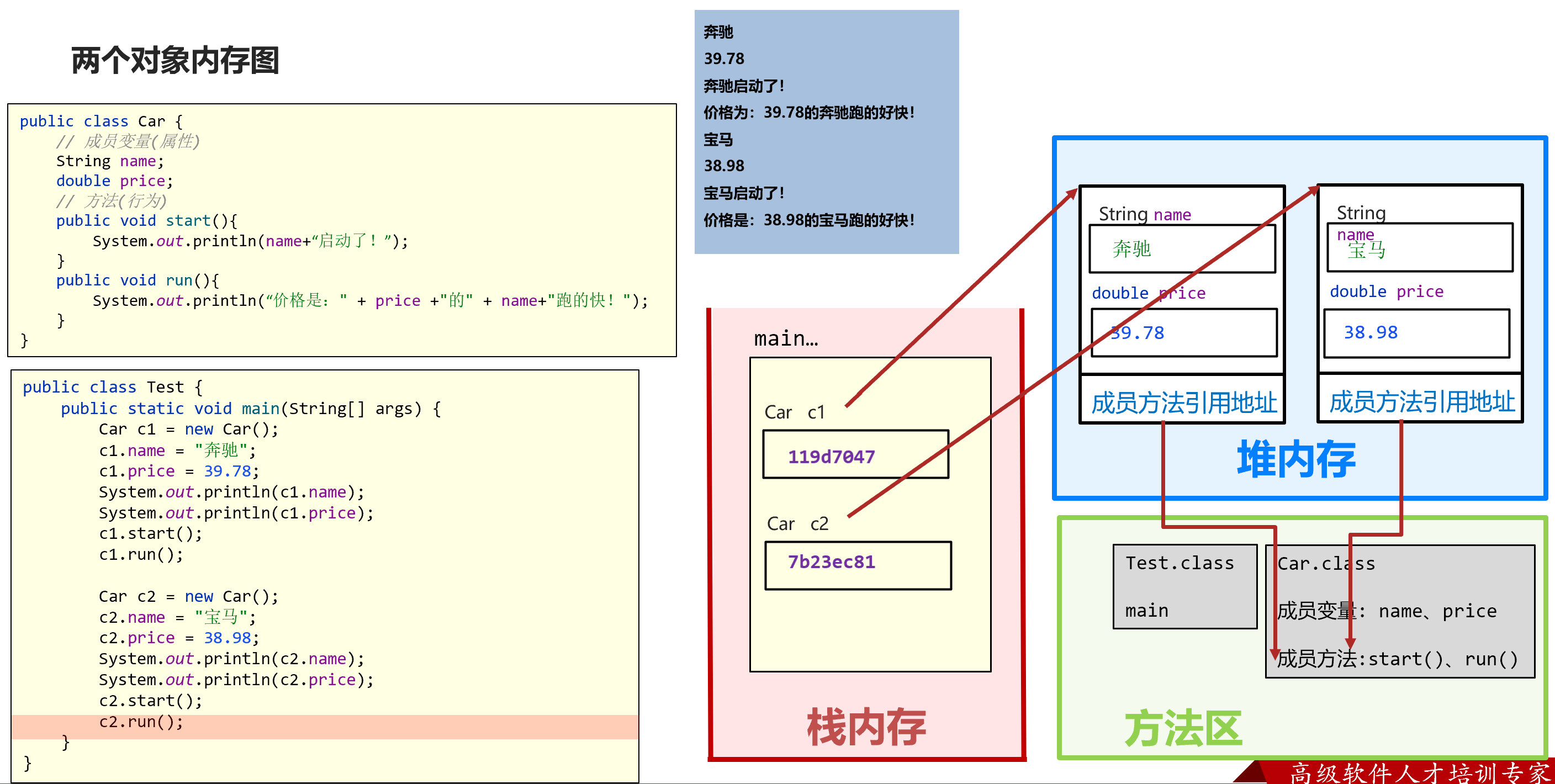
- 方法区保存了类的信息,包括类名、成员变量、成员方法等
- 堆中实际类对象的成员方法存的是方法区里类的成员方法引用
-
集合存储内存图
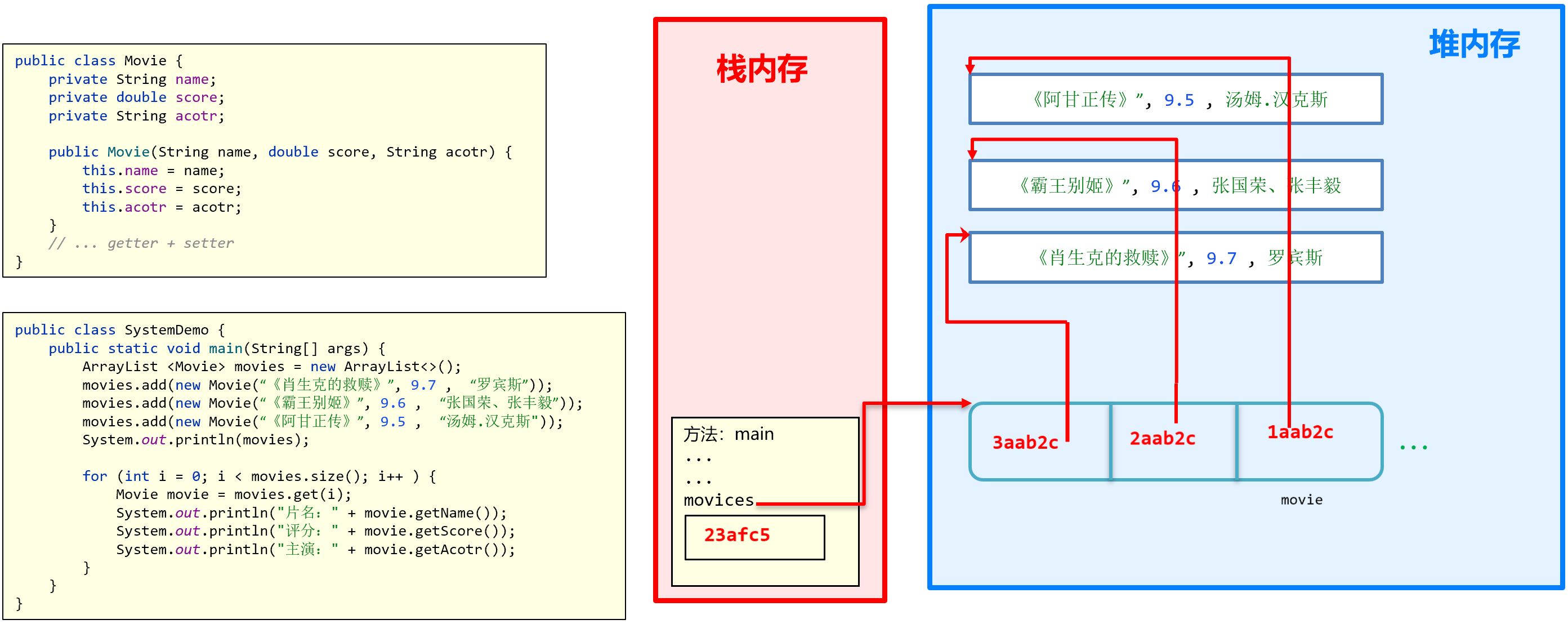
- 数组/集合中存储的元素并不是对象本身,而是对象的地址
-
静态常量内存图
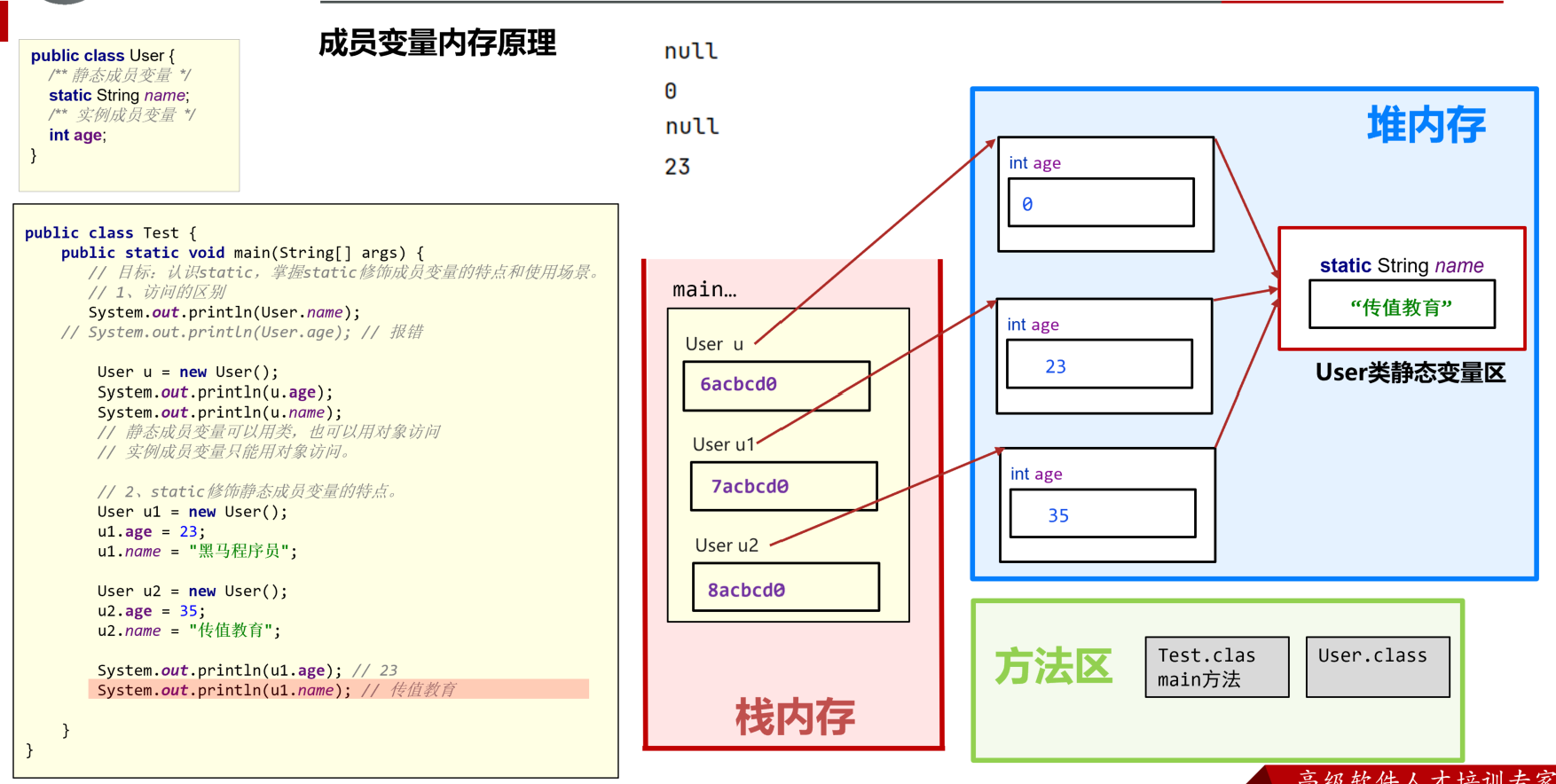
-
子类继承内存图
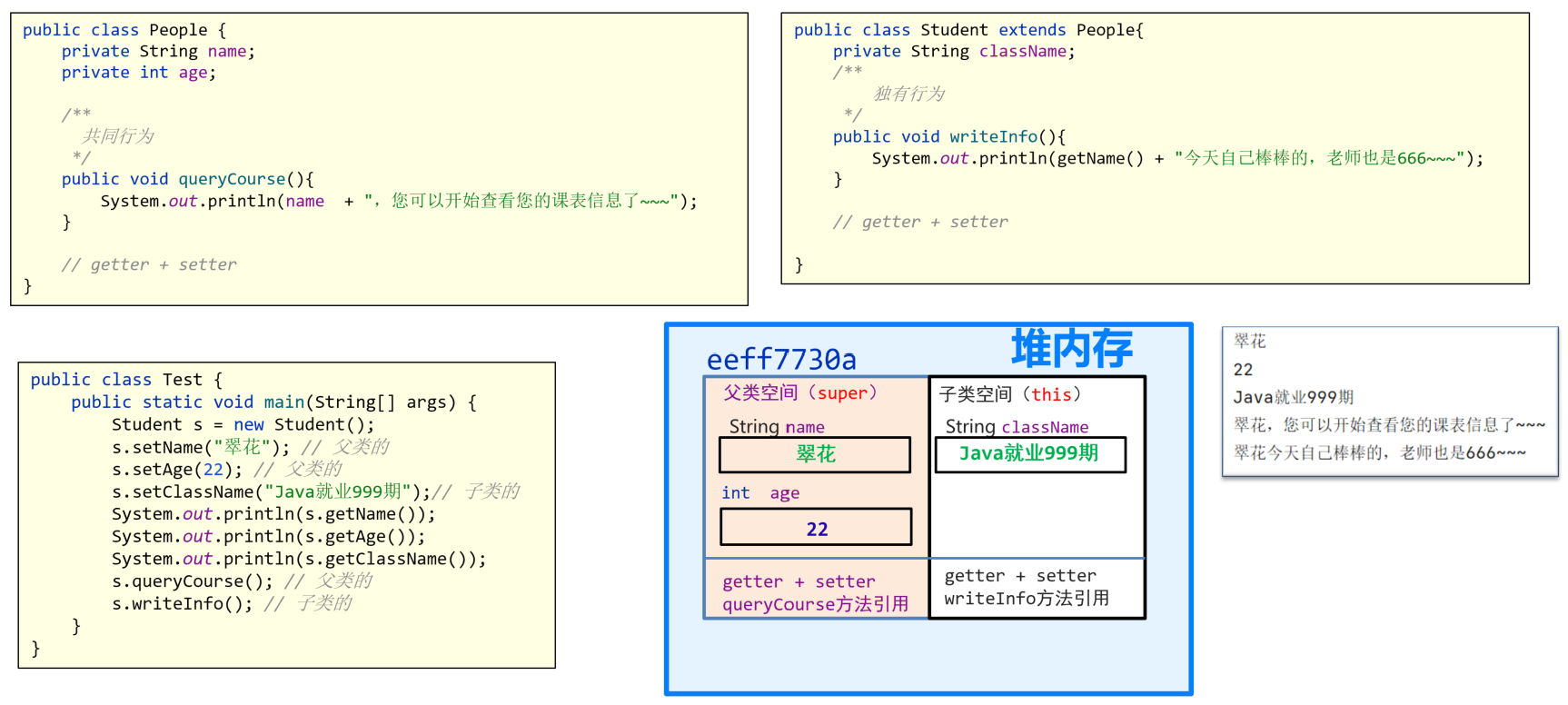
评论加载中。如果这里长期空白,请检查 giscus.app / GitHub 是否可访问。