Redis 多机
复制 Redis中可以使用 SLAVEOF 实现主从复制,复制功能分两个操作: 同步:将从服务器的数据库状态更新至主服务器的最新状态 命令传播:在主服务器的数据库状态被修改,导致主从不一致时,让主从数据库重新回到一致状态 旧版复制实现
复制
Redis中可以使用SLAVEOF <master_ip> <master_port>实现主从复制,复制功能分两个操作:
- 同步:将从服务器的数据库状态更新至主服务器的最新状态
- 命令传播:在主服务器的数据库状态被修改,导致主从不一致时,让主从数据库重新回到一致状态
旧版复制实现
- 同步:
- 从服务器向主服务器发送SYNC命令
- 收到SYNC的主服务器执行BGSAVE,在后台生成RDB文件,并使用一个缓冲区记录从现在开始执行的所有写命令
- BGSAVE执行完毕后,主服务器将生成的RDB文件发送给从服务器
- 从服务器接收并载入RDB文件,更新从数据库状态至主服务器执行BGSAVE时的状态
- 主服务器将缓冲区里的所有写命令发送给从服务器,从服务器执行这些写命令,更新数据库至最新状态

- 命令传播:同步完成后,任何写操作都将导致主从不一致。为了维护主从一致性,主服务器将自己执行的写命令,即造成主从服务器不一致的那条写命令发送给从服务器执行。从服务器执行了相同的写命令之后,主从服务器将再次回到一致状态。
- 旧版复制的缺陷:
- 主从复制可分为初次复制、断线后重复制
- 其中,断线后重复制为了补足小部分缺失数据,需要对所有数据进行同步,造成极大的资源开销
新版复制实现
为了解决旧版复制在断线后重复制的巨大开销,Redis从2.8开始使用PSYNC代替SYNC执行复制时的同步操作。
- PSYNC分两种模式:
- 完整重同步:处理初次复制的情况,与SYNC基本相同,创建RDB和命令缓冲区并发送
- 部分重同步:可以将连接断开期间的写命令发送给从服务器,从服务器只需要更新缺失数据即可恢复一致性
- 部分重同步的实现包含三个主要结构:
- 主从复制偏移量:
- 主从服务器分别维护一个复制偏移量,标记当前已经传播/接收的字节数据
- 如果主从一致,那么主从服务器的复制偏移量相同,否则不一致
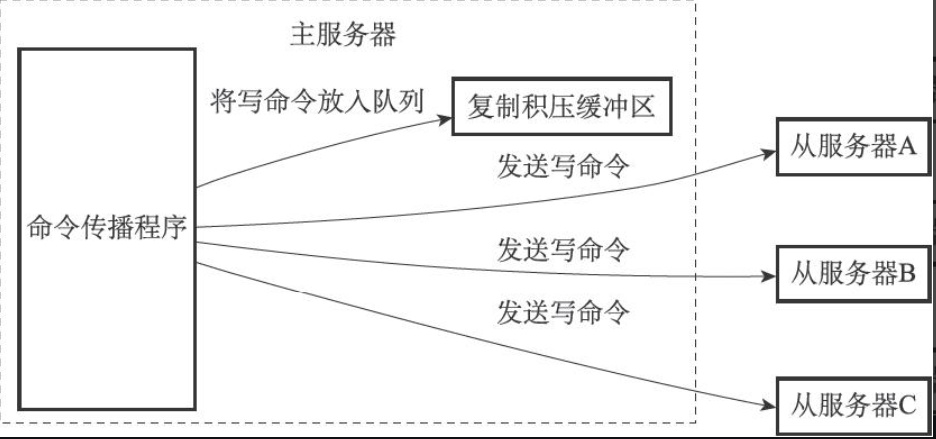
- 主服务器的复制积压缓冲区:
- 结构上是一个固定长度的FIFO队列,默认1MB
- 主服务器进行命令传播时,不仅发送给所有从服务器,也写入复制积压缓冲区,并为每个字节记录偏移量
- 从服务器断线重连后,根据复制偏移量之后的数据是否还在积压缓冲区中,决定执行完整/部分重同步
- 服务器运行ID:
- 初次复制时,主服务器将自己的ID发送给从服务器,从服务器保存下来
- 从服务器断线重连后,根据运行ID是否一致,决定执行完整/部分重同步
- 主从复制偏移量:
- PSYNC通信协议:
- 初次复制时,从服务器发送
PSYNC ? -1请求进行完整重同步 - 非初次复制时,从服务器发送
PSYNC <runid> <offset>,主服务器判断执行哪种同步操作 - 主服务器返回
+FULLRESYNC <runid> <offset>表示将执行完整重同步,并告知运行ID和初始复制偏移量 - 主服务器返回
+CONTINUE表示将执行部分重同步,随后将发送缺失的数据 - 主服务器返回
-ERR表示不支持PSYNC命令,随后将执行完整的SYNC操作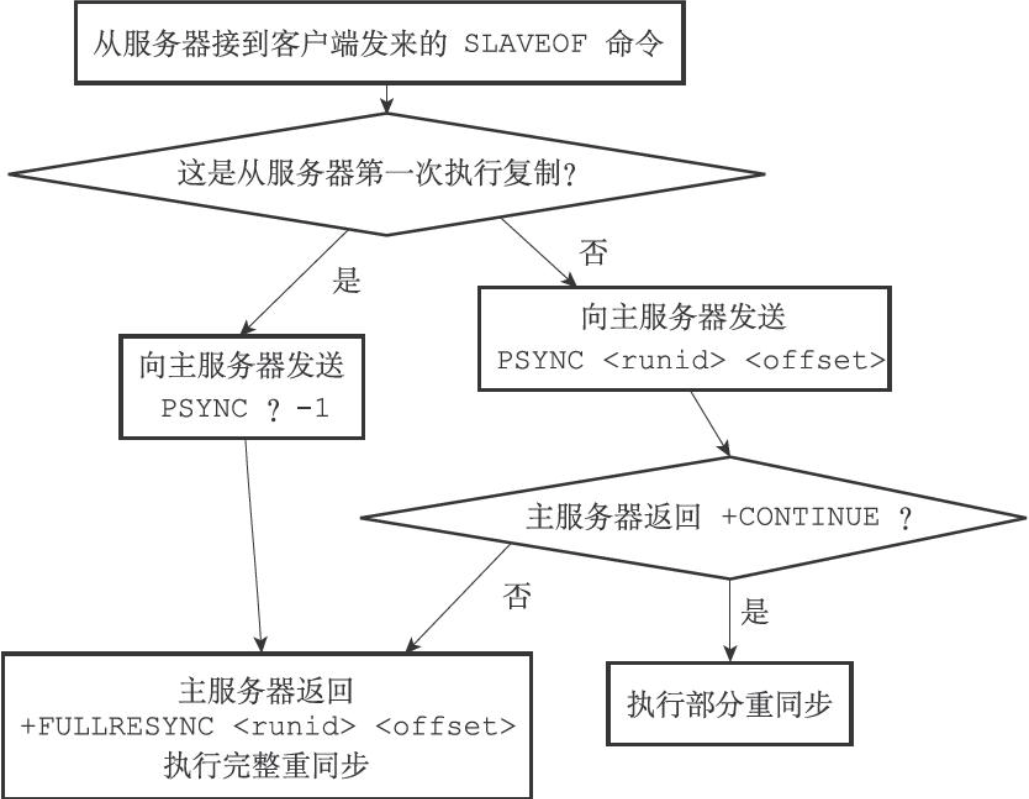
- 初次复制时,从服务器发送
复制完整逻辑
SLAVEOF <master_ip> <master_port>命令的底层实现步骤:
- 从服务器设置主服务器的地址和端口,记录在redisServer/masterhost, masterport属性
- 从服务器建立套接字连接,并关联用于处理复制工作的文件事件处理器。此时从服务器成为主服务器的一个客户端
- 从服务器向主服务器发送PING,主服务器恢复PONG,验证套接字连接正常,否则断开重连
- 使用AUTH进行身份验证,必须主服务器的requirepass和从服务器的masterauth同时设置或同时不设置,否则一直重试
- 从服务器发送监听端口号
REPLCONF listening-port <port> - 开始同步,从服务器发送PSYNC。此后,主从服务器互为对方的客户端
- 完成同步后,主服务器进入命令传播阶段
心跳检测
在命令传播阶段,从服务器默认每秒发送一次REPLCONF ACK <replication_offset>,作用有三:
- 监测主从服务器连接状态
- 辅助实现min-slaves选项:Redis在从服务器少于min-slaves-to-write,或服务器延迟大于等于min-slaves-max-lag时,将拒绝执行写命令
- 检测命令丢失:复制偏移量不一致时,说明发生了命令丢失,主服务器将补发缺失数据
Sentinel
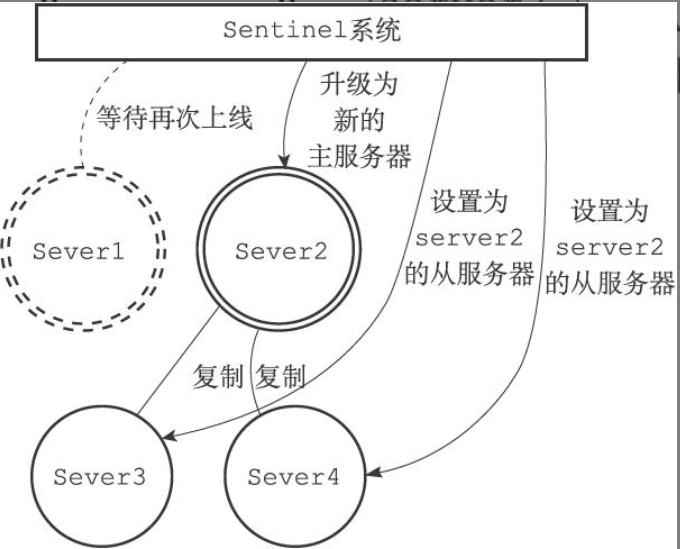
Sentinel(哨兵)是Redis的高可用性解决方案:由若干Sentinel实例组成的Sentinel系统可以监视多个主服务器,以及属下的从服务器,并在主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求,旧主服务器重新上线后降级为从服务器。
启动和初始化
通过redis-sentinel sentinel.conf命令启动sentinel,执行步骤包括:
-
初始化服务器
- 和普通Redis服务器不完全相同,例如不载入持久化文件
-
使用Sentinel专用代码
- 将一部分普通Redis服务器代码替换成Sentinel专用代码
- 例如Sentinel的命令表sentinelcmds中仅有 PING, SENTINEL, INFO, SUBSCRIBE, UNSUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE 七个命令
-
初始化Sentinel状态
- sentinelState结构保存和Sentinel功能相关的状态信息
- 服务器一般状态仍保存在redisServer中
-
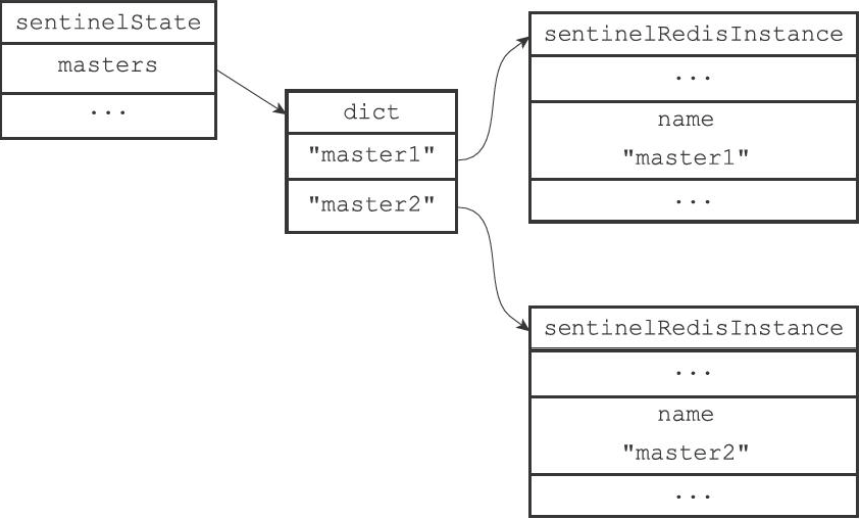
初始化Sentinel的监视主服务器列表
- sentinelState/masters字典属性记录了所有被Sentinel监视的主服务器
- 字典的键是主服务器的名字,值是对应的sentinelRedisInstance实例,可以是主/从服务器或另一个Sentinel
-
创建连向主服务器的网络连接
- 对于每个监视的主服务器,Sentinel将创建两个异步网络连接
- 一个是命令连接,用于发送命令,接收命令回复
- 另一个是订阅连接,用于订阅主服务器的__sentinel__:hello频道
通信连接
获取主服务器信息 Sentinel默认每10s通过命令连接向主服务器发送INFO命令,来获取主服务器当前信息并更新。
# Server 关于主服务器本身的信息
...
run_id:7611c59dc3a29aa6fa0609f841bb6a1019008a9c
...
# Replication 主服务器角色及下属从服务器信息
role:master
...
slave0:ip=127.0.0.1,port=11111,state=online,offset=43,lag=0
slave1:ip=127.0.0.1,port=22222,state=online,offset=43,lag=0
slave2:ip=127.0.0.1,port=33333,state=online,offset=43,lag=0
...
# Other sections
...
- Sentinel无须用户提供从服务器地址信息,就可以自动发现
- 从服务器信息保存至sentinelRedisInstance/slaves字典中,键是
ip:port,值是对应sentinelRedisInstance从服务器结构
获取从服务器信息 Sentinel发现主服务器有新的从服务器后,会创建对应的从服务器结构和对应的命令连接、订阅连接。然后默认每10s通过命令连接向从服务器发送INFO命令,来获取从服务器当前信息并更新。
# Server
...
run_id:32be0699dd27b410f7c90dada3a6fab17f97899f
...
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
# 从服务器复制偏移量
slave_repl_offset:11887
# 从服务器优先级
slave_priority:100
# Other sections
...
向服务器发送信息
Sentinel默认每2s通过命令连接向所有主/从服务器发送命令:
PUBLISH __sentinel__:hello "<s_ip>,<s_port>,<s_runid>,<s_epoch>,<m_name>,<m_ip>,<m_port>,<m_epoch>"
其中,s_开头的是Sentinel本身信息,m_开头的是(从服务器正在复制的)主服务器信息。
接收服务器信息
Sentinel与主从服务器建立订阅信息后,发送SUBSCRIBE __sentinel__:hello创建订阅频道,一直持续到连接断开。Sentinel通过订阅连接接收来自主从服务器的信息。

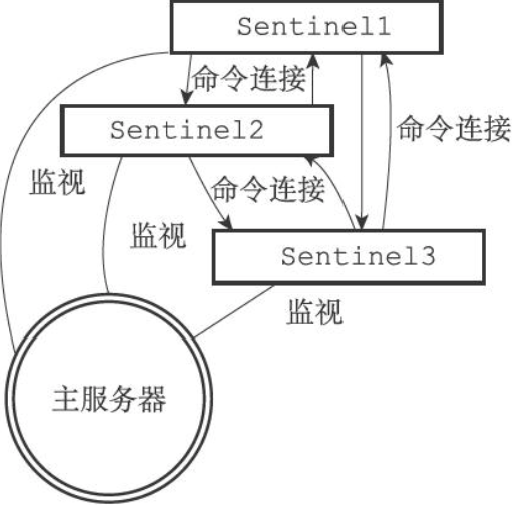
多个Sentinel 多个Sentinel监视同一个服务器,任意Sentinel发送的信息(包括本Sentinel信息、主服务器信息)会被其它Sentinel接收到,并更新各自保存的主服务器sentinelRedisInstance/sentinels字典。
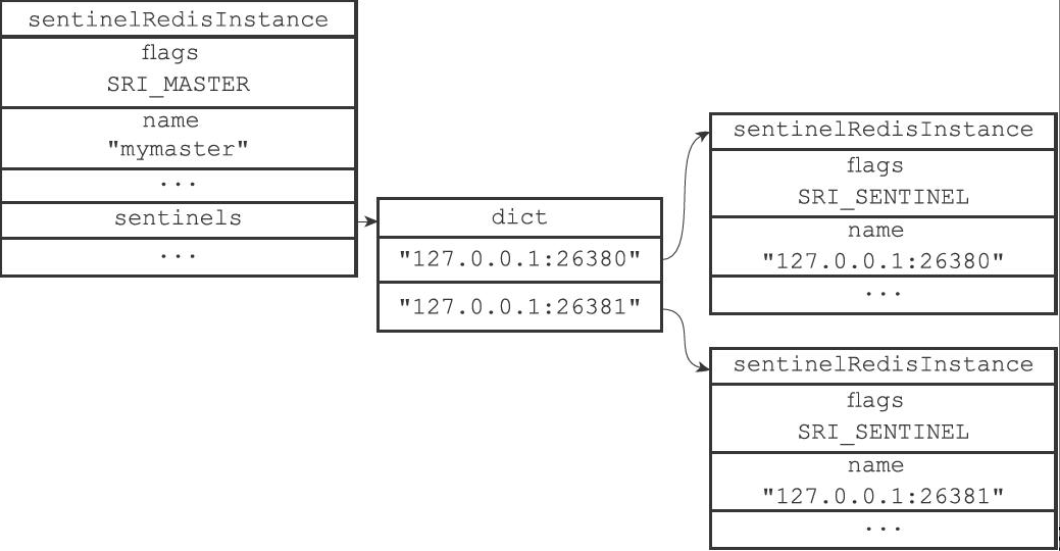
监视同一个服务器的Sentinel可以通过频道信息自动发现对方,并创建Sentinel之间的命令连接(无订阅连接),最终这些Sentinel将形成互相连接的网络
检测下线状态
主观下线 Sentinel默认每1s向所有建立命令连接的实例(主/从/Sentinel)发送PING命令,根据回复判断是否在线:
- 有效回复:+PONG, -LOADING, -MASTERDOWN
- 无效回复:其它或无回复
如果返回无效回复的时间超过down-after-milliseconds,那么Sentinel将认定该实例主观下线,打开sentinelRedisInstance/flags的SRI_S_DOWN标记
客观下线
- Sentinel发送
SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid>来询问其它Sentinel是否同意该主服务器已下线 - 目标Sentinel收到源Sentinel的询问命令后,解析并检查,然后回复三个参数的Multi Bulk:
- down_state: 检查结果,1下线,0在线
- leader_runid: *表示询问下线的回复;否则表示局部领头Sentinel的运行id
- leader_epoch: leader_runid不为*时,表示局部领头Sentinel的配置纪元。否则为0
- 当同意该主服务器已下线的Sentinel总数$>=quorum$,认定客观下线,打开sentinelRedisInstance/flags的SRI_O_DOWN标记
选举领头Sentinel
当一个主服务器被判定客观下线,监视该服务器的所有Sentinel将选举出一个领头Sentinel,来执行故障转移操作。
规定:
- 监视该主服务器的所有在线Sentinel都可能成为领头
- 每次选举不论是否成功,所有Sentinel的配置纪元(epoch)都会自增,相当于计数器
- 在一个配置纪元里,所有Sentinel都有一次将某个Sentinel设置为局部领头的机会,并且一旦设置不能更改
- 某个Sentinel被超过半数的Sentinel设置为局部领头,才能成为领头Sentinel
- 基于上述两点,在一个配置纪元里面只会出现一个领头Sentinel。
步骤:
- 当Sentinel判定主服务器客观下线,会要求其他Sentinel将自己设置为局部领头
- 源Sentinel向另一个目标Sentinel发送
SENTINEL is-master-down-by-addr命令,且参数runid是源Sentinel的运行ID,表示源Sentinel要求目标Sentinel将源设置为目标的局部领头 - 局部领头遵循先到先得,最先收到的请求将设置成功
- 源Sentinel向另一个目标Sentinel发送
- 目标Sentinel接收到
SENTINEL is-master-down-by-addr命令之后,将向源Sentinel返回一条命令回复- 回复中的 leader_runid 记录该Sentinel设定的局部领头运行ID
- 回复中的 leader_epoch 记录该Sentinel设定的局部领头配置纪元
- 源Sentinel解析目标Sentinel返回的命令回复
- 检查回复中 leader_epoch 和自己的配置纪元是否相同,如果相同则继续
- 检查回复中 leader_runid 和自己的运行ID是否相同,如果相同,表示目标将源设置成了局部领头
- 如果某个Sentinel被超过半数的Sentinel设置成局部领头,那么这个Sentinel成为领头Sentinel
- 如果给定时限内没有一个Sentinel被选举为领头Sentinel,将在一段时间后再次选举,直到选出领头Sentinel为止
故障转移
选举产生的领头Sentinel负责对已下线的主服务器执行故障转移操作:
-
在已下线主服务器属下的所有从服务器里,选择一个从服务器发送
SLAVEOF no one命令,转换为主服务器。选择策略如下:- 剔除下线/断线的从服务器
- 剔除近5s内没有回复INFO命令的从服务器
- 剔除所有与旧主服务器连接断开超过$down-after-millseconds*10 ms$的从服务器
- 剩余候选者中选择优先级最高的从服务器
- 优先级相同,选择复制偏移量最大的从服务器
- 优先级和偏移量都相同,选择运行ID最小的从服务器
-
发送SLAVEOF命令,让旧主服务器属下的所有从服务器改为复制新的主服务器
-
将旧主服务器设置为新主服务器的从服务器(修改对应实例结构),当旧主服务器重新上线时,它就会成为新主服务器的从服务器
集群
节点
Redis服务器根据配置决定是否开启集群模式,一个集群由多个节点组成,节点会继续使用所有单机模式下的组件,以及集群特定的相关组件。
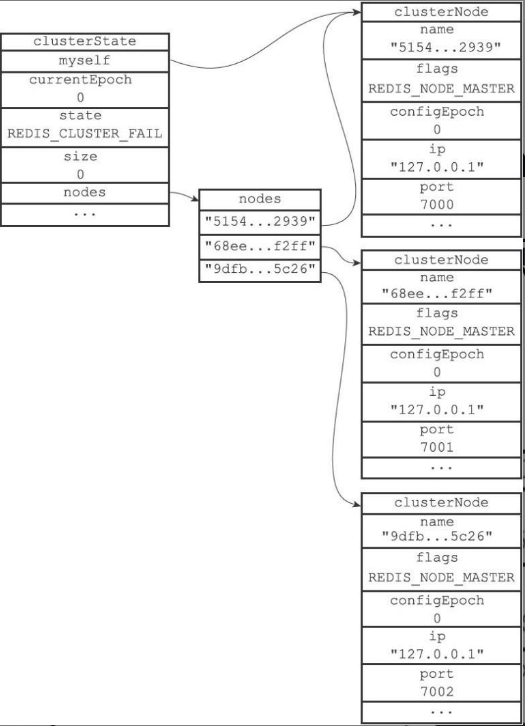
数据结构
- clusterNode:
- 每个节点使用一个clusterNode记录自己的状态,并为集群中其它节点创建一个对应的节点结构
- 包括ctime, name, flags, configEpoch, ip, port, clusterLink[]…
- clusterLink:
- 保存连接节点所需的信息
- 包括套接字描述符、输入/输出缓冲区、关联节点…
- clusterState:
- 每个节点保存一个集群状态结构,记录当前节点视角下的集群所处状态
- 包括currentEpoch, state, size…
CLUSTER MEET 命令实现
节点A向节点B发送CLUSTER MEET <ip> <port>命令,将节点B纳入A所在集群,实现如下(三次握手):
- A为B创建clusterNode,并添加到自己的clusterState.nodes字典里面
- 然后A根据给定的IP和端口,向B发送一条MEET消息
- B收到A发送的MEET消息后,会为A创建clusterNode,并添加到自己的clusterState.nodes字典里面
- 接着B向A返回一条PONG消息
- A收到B返回的PONG消息后,可以知道B已经成功接收到自己发送的MEET消息
- 最后A向B再返回一条PING消息
- B收到A返回的PING消息后,可以知道A已经成功接收到自己返回的PONG消息,握手完成
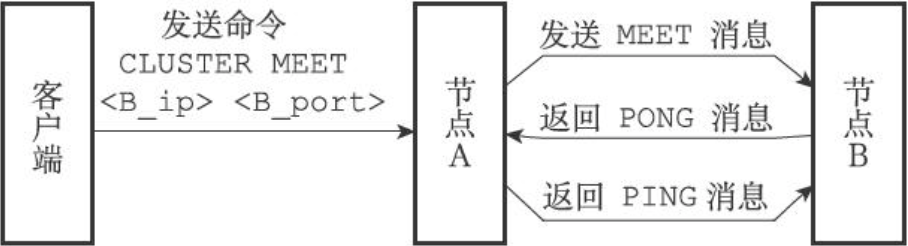
之后A将B的信息通过Gossip协议传播给集群中其它节点,最终,节点B与集群所有节点握手成功。CLUSTER NODES查看当前集群节点状态。
集群节点的特殊之处
- 节点只能使用0号数据库
- 节点会在clusterState/slots_to_keys跳跃表保存槽和键的对应关系,跳跃表节点的成员是数据库键,分值是槽号
分片与槽
Redis集群通过分片的方式来保存数据库中的键值对,集群的整个数据库被分为16384个槽(slot),每个键都属于其中一个槽,集群中的每个节点可以处理0~16384个槽。只有当16384个槽都有节点负责处理时,集群处于上线状态。
记录槽指派信息
- clusterNode/numslot 属性记录本节点负责处理的槽数量
- clusterNode/slots[] 属性是一个2048Byte(16384bit)的数组,每一位表示对应的槽是否被指派给本节点
- clusterState/slots[] 是长度为16384的clusterNode指针数组,每个指针指向负责处理对应槽的节点
设计考量:
- 一个节点不仅会记录自己负责处理的槽记录,还会通过消息发送给集群中其它节点,因此集群中每个节点都知道16384个槽分别被指派给哪些节点。
- clusterNode保存槽指派信息。使得传播某个节点的槽指派信息变得高效
- clusterState保存槽指派信息,使得程序能够以O(1)检查某个槽是否被指派,以及指派的节点
ADDSLOTS 命令实现
CLUSTER ADDSLOTS <slots>命令将若干槽指派给当前节点负责,实现上即修改clusterNode/slots和clusterState/slots属性。执行完毕后节点会通过消息告知其它节点自己目前负责的槽信息。
重新分片
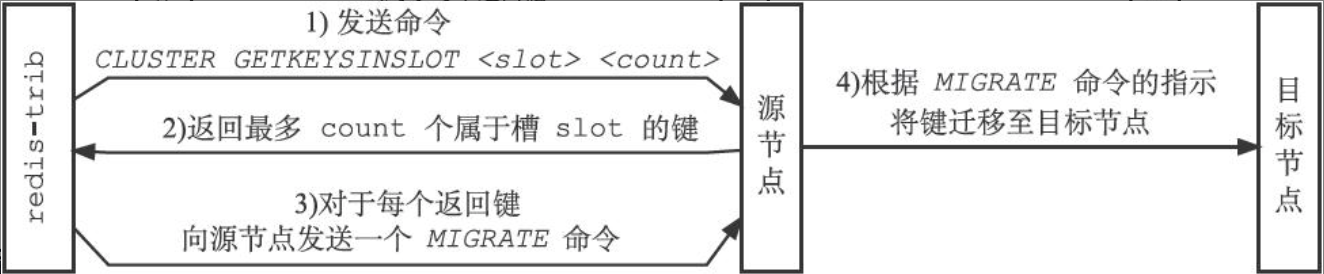
Redis集群的重新分片可以将任意数量的槽修改分配节点,并且相关槽所属的键值对也会迁移至目标节点。操作由集群管理工具redis-trib负责,实现原理如下:
- redis-trib对目标节点发送
CLUSTER SETSLOT <slot> IMPORTING <source_id>命令,让目标节点准备好从源节点导入属于槽slot的键值对。- 修改cluserState/importing_slots_from[](clusterNode指针数组),不为NULL表示当前节点正从指向的clusterNode导入对应的槽
- redis-trib对源节点发送
CLUSTER SETSLOT <slot> MIGRATING <target_id>命令,让源节点准备好将属于槽slot的键值对迁移至目标节点。- 修改cluserState/migrating_slots_to[](clusterNode指针数组),不为NULL表示当前节点正将对应的槽迁移至指向的clusterNode
- redis-trib向源节点发送
CLUSTER GETKEYSINSLOT <slot> <count>命令,获得最多count个属于槽slot的键值对的键名。 - 对于步骤3获得的每个键名,redis-trib都向源节点发送一个
MIGRATE <target_ip> <target_port> <key_name> 0 <timeout>命令,将被选中的键原子地从源节点迁移至目标节点。 - 重复执行步骤3和步骤4,直到源节点保存的所有属于槽slot的键值对都被迁移至目标节点为止。
- redis-trib向集群中的任意一个节点发送
CLUSTER SETSLOT <slot> NODE <target_id>命令,将槽slot指派给目标节点,这一指派信息会通过消息发送至整个集群。 - 如果重新分片涉及多个槽,那么redis-trib将对每个给定的槽分别执行上面给出的步骤。
集群中执行命令
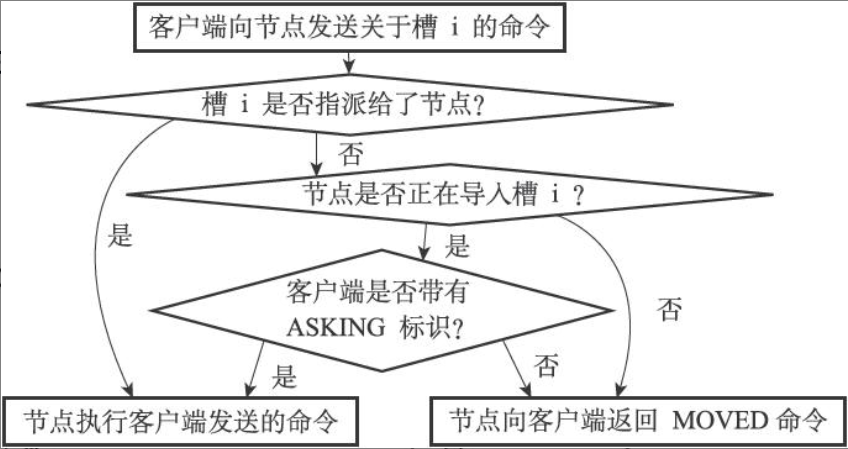
当数据库的16384个槽有进行指派后,集群进入上线状态,客户端就可以发送命令请求了。当发送与数据键相关命令时:
- 计算给定键所在的槽:
CRC16(key) & 16383(CLUSTER KEYSLOT <key>命令查看键对应的槽) - 检查clusterState/slots属性,判断槽是否由当前节点负责
- 如果槽正好由当前节点负责,那么节点直接执行
- 否则节点返回
MOVED <slot> <ip>:<port>,指引客户端自动转向到正确的节点,并再次发送命令
一个集群客户端通常会与集群中的多个节点创建套接字连接,节点转向即换一个套接字发送命令,如果没有创建套接字连接,会先连接节点再进行转向。
ASK与ASKING 在重新分片期间,如果客户端发送了关于某个键的命令:
- 节点首先查看键是否在自己的数据库中,在就直接执行
- 否则检查migrating_slots_to数组,查看是否正在迁移,如果是发送
ASK <slot> <target_ip>:<target_port>错误信息 - 客户端接收到ASK错误后,转向正在导入槽的目标节点,发送
ASKING命令,打开REDIS_ASKING一次性标记 - 目标节点查询importing_slots_from是否正在导入,如果正在导入,则破例执行一次命令
- MOVED错误代表槽的负责权已经从一个节点转移到了另一个节点:在客户端收到关于槽i的MOVED错误之后,客户端每次遇到关于槽i的命令请求时,都可以直接将命令请求发送至MOVED错误所指向的节点,因为该节点就是目前负责槽i的节点。
- 与此相反,ASK错误只是两个节点在迁移槽的过程中使用的一种临时措施:在客户端收到关于槽i的ASK错误之后,客户端只会在接下来的一次命令请求中将关于槽i的命令请求发送至ASK错误所指示的节点,但这种转向不会对客户端今后发送关于槽i的命令请求产生任何影响,客户端仍然会将关于槽i的命令请求发送至目前负责处理槽i的节点,除非ASK错误再次出现。
复制与故障转移
Redis集群中的节点分主节点和从节点,其中主节点负责处理槽,从节点用于复制某个主节点以及故障转移。
设置从节点
CLUSTER REPLICATE <node_id>让接收到命令的节点成为指定节点的从节点,并开始复制。实现上:
- 修改自己的clusterState.myself.slaveof指针,记录正在复制的主节点
- 修改flags,打开REDIS_NODE_SLAVE标记
- 调用复制功能,与单机复制相同
- 将自己成为从节点这一消息发送给集群中的其它节点
- 其它节点接收消息后,修改主节点clusterNode/slaves, numslaves属性,记录所属从节点和数量
故障检测
集群中每个节点定期向其它节点发送PING,如果目标节点没有在规定时间内回复PONG,则打开REDIS_NODE_PFAIL疑似下线标记。并通过消息在集群内交换信息,并记录在对应的节点的fail_reports下线报告中。如果集群内超过半数的主节点报告某个节点X疑似下线,则将X标记FAIL已下线,并广播给所有节点。
故障转移
当一个从节点发现自己正在复制的主节点已下线时,从节点将开始进行故障转移:
- 下线主节点的所有从节点中选举一个新的主节点,选举方法和Sentinel类似,都是基于Raft共识算法:
- 当某个节点开始故障转移,集群配置纪元(计数器,初始0)的值自增1
- 一个配置纪元里,每个主节点都有一次投票机会,且第一个向主节点要求投票的从节点将获得主节点的投票
- 当从节点发现所属的主节点已下线时,从节点广播一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,要求所有主节点给自己投票。 - 如果一个主节点具有投票权(正在负责处理槽),并且尚未投票给其他从节点,那么主节点将向要求投票的从节点返回一条
CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,表示给该从节点投票 - 参与选举的从节点根据投票回复,统计自己得票数
- 如果集群里有N个具有投票权的主节点,那么当一个从节点得到 $>=\frac{N}{2}+1$ 张支持票时,当选为新主节点。一个配置纪元里,仅有一个节点能当选成功。
- 如果一个配置纪元里没有从节点能得到足够多的支持票,那么集群进入新的配置纪元,并再次进行选举,直到选出新的主节点为止。
- 新主节点执行SLAVEOF no one命令
- 新主节点将所有对旧主节点的槽指派转移给自己
- 新主节点广播PONG消息,告知集群自己成为新的主节点,并负责处理相应的槽
- 新主节点开始接收相应的槽有关的命令请求,故障转移完成
消息
集群中各个节点通过发送和接受消息进行通信,常见消息分为五种类型:MEET, PING, PONG, FAIL, PUBLISH。
结构
- 所有消息都由消息头 + 消息正文组成。
- 消息头记录消息发送者本身的一些信息,由clusterMsg结构表示
- 包括消息长度、类型、配置纪元、发送者名字、槽指派信息、从节点…
- 接收者根据收到的信息,更新相应的clusterNode结构
- 消息正文由clusterMsgData结构表示,不同类型的消息内容不同
实现
- MEET:请求接收者加入到发送者所处的集群里。
- PING:默认每隔1s随机选出五个节点,对其中最长时间没有PING过的节点发送PING消息,检测是否在线
- PONG:回复MEET和PING,或广播告知集群刷新自己的状态,例如成为主节点
以上三类消息都基于Gossip协议,消息正文由两个clusterMsgDataGossip结构组成,保存两个目标节点相关信息。接收者收到消息后更新对应的节点结构。
- FAIL:集群广播告知某个主节点进入下线状态
- Gossip协议有延迟,难以保证即使进行故障转移,因此采用广播消息
- 消息正文由clusterMsgDataFail结构表示,仅含下线节点名字一个属性
- PUBLISH:执行命令并向集群广播该条PUBLISH消息,所有接收到的节点都会执行相同的PUBLISH命令
- 收到
PUBLISH <channel> <msg>命令不仅向某个频道发送消息,还会向集群广播PUBLISH消息 - 消息正文由clusterMsgDataPublish结构表示,包括频道、信息的长度和内容
- 收到
评论加载中。如果这里长期空白,请检查 giscus.app / GitHub 是否可访问。